Исследование состояния и развития трубопроводного транспорта в России 1 страница
Географические границы исследуемого товарного рынка соответствуют границам зон деятельности хозяйствующих субъектов, которые являются поставщиками.
Географические границы товарного рынка по транспортировке на внутренний рынок светлых нефтепродуктов по магистральным трубопроводам предварительно определены как территория Российской Федерации.
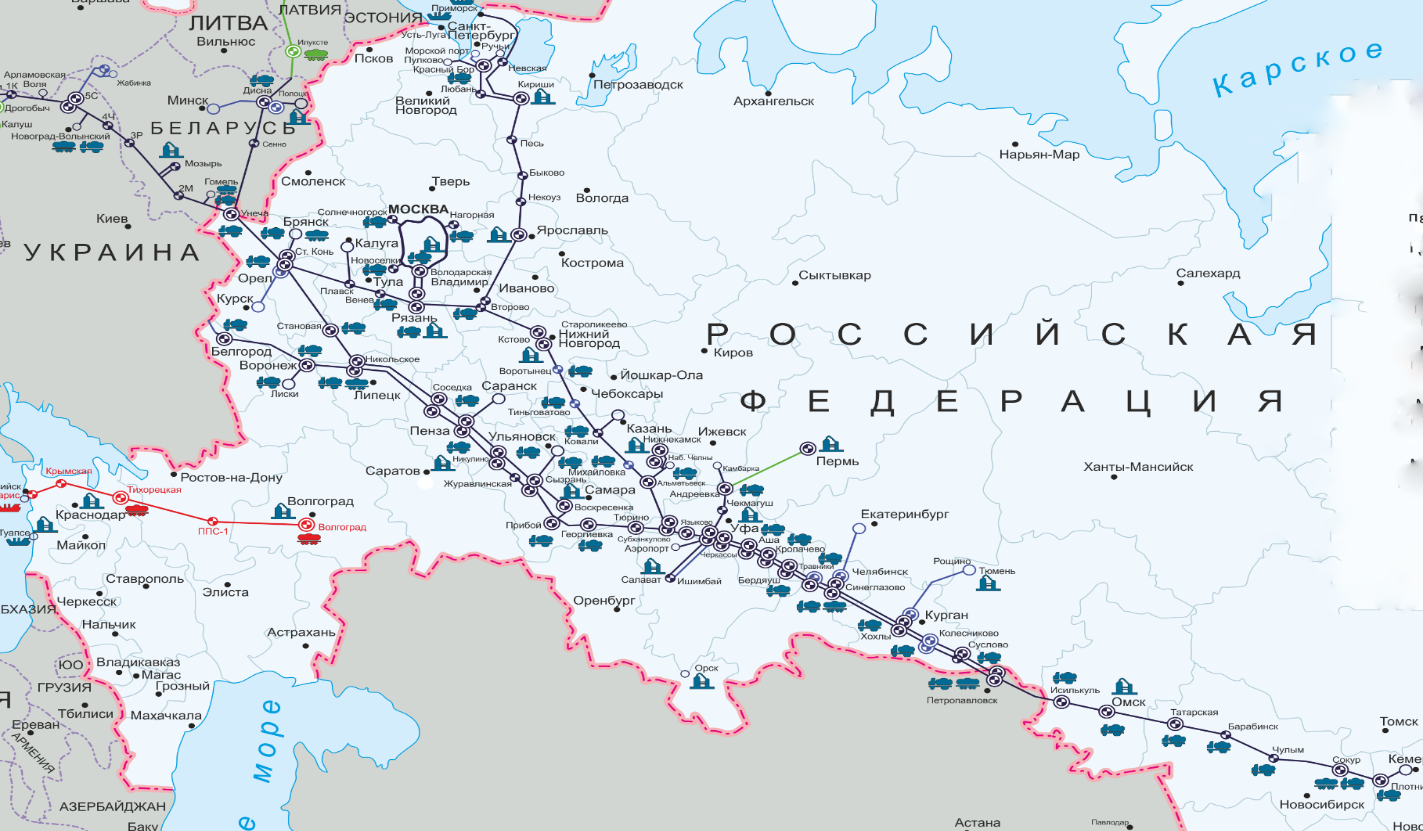
Рис.2.2 - Схема расположения системы магистральных нефте-продуктопроводов ПАО «Транснефть»
Как видно из рисунка 2.2, система магистральных нефтепродуктопроводов (далее - МНПП) ПАО «Транснефть» располагается по территории Российской Федерации от западной ее границы через европейскую часть и до севера Кемеровской области.
Транспортировка светлых нефтепродуктов с использованием непосредственно МНПП осуществляется ПАО «Транснефть» в 5 федеральных округов: Центральный, Северо-Западный, Приволжский, Уральский и Сибирский.
Результаты опроса потребителей показали, что в основном для доставки нефтепродуктов до конечного пункта назначения (АЗС, ТЗК) они используют трубопроводный и автомобильный транспорт или железнодорожный и автомобильный транспорт. Возможны комбинированные схемы транспортировки нефтепродуктов железнодорожным и трубопроводным транспортом, водным и железнодорожным и т.п. Таким образом, транспортировку нефтепродуктов следует рассматривать различными видами транспорта в совокупности. Исходя из этого, все маршруты транспортировки нефтепродуктов по системе МНПП имеют альтернативу для их транспортировки по железной дороге. Более того, сеть железнодорожных перевозок, исходя из анализа регионов доставки и направлений, более разветвленная, чем трубопроводная что позволяет доставлять нефтепродукты железнодорожным транспортом от НПЗ, не подсоединенных к системе МНПП, в регионы, куда невозможна поставка трубопроводным транспортом.
Схема грузопотоков нефтепродуктов по системе магистральных трубопроводов в период с 01.01.2017 по 31.12.2017 приведены на рис. 2.3.

Рис. 2.3 - Схема грузопотоков нефти и нефтепродуктов по системе магистральных нефтепродуктов в 2017 г.
По данным ПАО «Транснефть», протяженность системы МНПП ПАО «Транснефть», по которой Компания осуществляет транспортировку светлых нефтепродуктов, составляет в настоящее время 19,2 тыс. км, из них магистральных трубопроводов - 15,4 тыс. км, отводов - 3,7 тыс. км, в том числе:
- по территории России - 16,4 тыс. км;
- по территории Украины - 1,2 тыс. км (в 2016 году трубопроводная система продана);
- по территории Белоруссии - 1,2 тыс. км;
- по территории Казахстана - 0,3 тыс. км;
- по территории стран Балтии - 415 км (СП «ЛатРосТранс»).
К системе МНПП ПАО «Транснефть» подключены 19 НПЗ, из которых 17 расположены на территории России (Таблица 2.3) и 2 на территории Белоруссии («Мозырский НПЗ» и «Новополоцкий НПЗ» (ОАО «Нафтан»).
Таблица 2.3 - Система МНПП ПАО «Транснефть»
| № п/п | Наименование НПЗ | Собственник | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 1 | Филиал ПАО АНК «Башнефть» «Башнефть-Уфанефтехим» | ПАО «АНК «Башнефть» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 2 | Филиал ПАО АНК «Башнефть» «Башнефть-Новойл» | ПАО «АНК «Башнефть» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 3 | Филиал ПАО АНК «Башнефть» «Башнефть-УНПЗ» | ПАО «АНК «Башнефть» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 4 | ООО «КИНЕФ» | ОАО «Сургутнефтегаз» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 5 | ОАО «Газпромнефть-ОНПЗ» | ОАО «Газпром нефть» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 6 | ОАО «Газпром нефтехим Салават» | ОАО «Газпром» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 7 | ОАО «Газпромнефть-МНПЗ» | ОАО «Газпром нефть» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 8 | ОАО «Куйбышевский НПЗ» (Самарский) | ОАО «НК «Роснефть» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 9 | ОАО «НК Новокуйбышевский НПЗ» (Самарский) | ОАО «НК «Роснефть» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 10 | АО «Сызранский НПЗ | ОАО «НК «Роснефть» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 11 | ЗАО «РНПК» (Рязанская нефтеперерабатывающая компания) | ОАО «НК «Роснефть» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 12 | ОАО «ТАИФ-НК» (Нижнекамскнефтехим») | ОАО «ТАИФ-НК» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 13 | ОАО «ТАНЕКО» | ПАО «Татнефть» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 14 | ООО «Лукойл-Нижегороднефтеоргсинтез» | ПАО «ЛУКОЙЛ» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 15 | ООО «Лукойл-Пермнефтеоргсинтез» | ПАО «ЛУКОЙЛ» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 16 | ОАО «Славнефть-ЯНОС» (ЯНОС) | ОАО «НГК «Славнефть» | |
| Модель Леонтьева. Если в балансы отраслей включить потребление сырья, материалов и услуг для производственных целей, будет получен счет производства, сальдо которого представляет валовую добавленную стоимость в секторе ?. Счет представлен потоками, порождающими таблицу межотраслевого обмена. Она используется для описания равновесия ресурсов и использования (квадранты A, B, C). Квадрант A – это n?n-матрица затрат и выпусков продукции n отраслями экономики, B – n?k-матрица потоков использования, а C – m?n-матрица потоков ресурсов. Рис.1. Межотраслевой баланс национальной экономики. Это представление экономики указывает направления использования продуктов и ресурсов отраслей, но для применения межотраслевого баланса экономическую деятельность нужно распределить так, чтобы каждому продукту соответствовала одна отрасль, а каждой отрасли – один продукт. Состояние экономики Японии в 1975 г. отражает модель с n=13 отраслями [1]: 1 – сельское и лесное хозяйство, 2 – добывающая промышленность, 3 – обрабатывающая промышленность, 4 – строительство, 5 – электроэнергетика, газо- и водоснабжение, 6 – торговля, финансы и страхование, 7 – операции с недвижимостью, 8 – транспорт и связь, 9 – общественные услуги, 10 – услуги, 11 – канцелярские товары, 12 – упаковка, 13 – другие отрасли. Столбцами матрицы B являются: 14 – доходы вне домохозяйств, 15 – личное потребление, 16 – государственное потребление, 17 – инвестиции, 18 – прирост запасов, 19 – экспорт, 20 – импорт, 21 – таможенные пошлины. Строками матрицы C являются: 14 – расходы вне домохозяйств, 15 – оплата труда, 16 – прибыль, 17 – амортизация, 18 – налоги, 19 – субсидии. Таблица 1A. Квадрант A (млрд.йен). Таблица 1B. Квадрант B (млрд.йен). Таблица 1C. Квадрант С (млрд.йен). Для Японии-1975 конечный выпуск Y=eTy=154865 млрд. йен, а валовой выпуск X=eTx=325295 млрд. йен. Таблица 1D. Валовый выпуск x, конечный выпуск y и добавленная стоимость v отраслей (млрд.йен). Таблица 2A. Матрица прямых затрат и доли добавленной стоимости. Таблица 2B. Матрица прямых выпусков и доли конечного продукта. Наибольший интерес представляет спектральный радиус ?A матрицы A (или B) и соответствующий ему собственный вектор xA. Таблица 2C. Cобственный вектор матрицы A для ?A=0,565. Обычно отрасли хозяйства группируют в три сектора: 1 – сельское хозяйство, 2 – промышленность, 3 – услуги и все отрасли, не вошедшие в два сектора. Столбцами матрицы B являются: 4 – доходы вне домохозяйств, 5 – личное потребление, 6 – государственное потребление, 7 – инвестиции, 8 – прирост запасов, 9 – экспорт, 10 – импорт, 11 – пошлины. Строками матрицы C являются: 4 – расходы вне домохозяйств, 5 – доходы занятых по найму, 6 – прибыль, 7 – амортизационные отчисления, 8 – налоги, 9 – субсидии. Таблица 3A. Квадранты А, B, C и Dx для Японии 1975 г. (млрд.йен). Таблица 3B. Доли затрат и выпусков в Японии 1975 г. Таблица 3C. Собственные векторы и собственные значения. Приведем уравнения валовых выпусков Ax+y=x и валовых затрат Bx+v=x к диагональному виду (XA-1AXA)(XA-1x)+(XA-1y)=(XA-1x) и (Xb-1BXB)(XB-1x)+(XB-1v)=(XB-1x). Результаты приведения указаны в таблице 2D: добавленная стоимость сT(XB-1x), конечный выпуск dT(XB-1x), валовые затраты fT(XB-1x), валовой выпуск gT(XB-1x). Коэффициенты полезного действия секторов ?1=43,8%, ?2=88,0% и ?3=96,8%, а экономики Японии-1975 г. ?=dTx/tr(Dx)=47,6%. Таблица 2D. Приведение матриц A, B, C и D. Линейная регрессия. Регрессионный анализ – это совокупность приемов восстановления известных функциональных зависимостей по данным наблюдений. Гипотезу о зависимости данных наблюдений называют моделью регрессии. Модель линейной регрессии, (1) где уr – зависимая переменная (регрессанд), х – независимая переменная (регрессор), b0 и b1 – неизвестные параметры регрессионной модели. Класс функций Ф образуют функции {?}, которые определяются формулой (1) и парой числовых параметров (b0,b1). Пусть известны данные наблюдений (х1,y1), (x2,y2),...,(хn,уn) (2) Даже если зависимость y от х линейная, неминуемые ошибки наблюдения приводят к тому, что на самом деле , i=1,...,n, (3) где ei – ошибка в i-го наблюдения. В методе наименьших квадратов выбор значений b0 и bl состоит в поиске решения b*= (b0*,b1*) задачи квадратичного программирования. (4) С учетом соотношений (3), задача (4) имеет другую интерпретацию. Найти значения b0 и b1, при которых минимальна сумма квадратов остатков, (5) где еi=yi–b1xi–b0, i=1,...,п. Решение задачи (4) будет стационарной точкой функции f и потому нужно решить систему линейных уравнений:, (6). (7) Из уравнения (6) имеем:, (8) а из (7) находим. (9) Поделим обе части уравнения (9) на n и введем обозначения и (10) для средних значений регресcора x и регресcанда y. В новых обозначениях уравнение (9) примет вид:. (11) С учетом этого уравнение (8) можно переписать в виде. (12) Разделим обе части этого равенства на п и с учетом (10) получим:, (13) где var(x) – дисперсия значений {хi}. Ковариация переменных:. (14) Параметр b1 регрессионной модели (1) связан с ковариацией и дисперсией. (15) Рассмотрим два случая. Предположим, что var(x)=0. Так может быть, если значения {хi} совпадают и xi=mx. Но в таком случае cov(x,y) равен 0, и любые значения b0 и b1 дают минимум целевой функции f(b) задачи (4). Пусть var(x)>0. В этом случае существует решение задачи (4), которое вычисляется по формулам (11) и (15). Основные свойства линейной регрессии (1), параметры b0 и b1 которой определяются по МНК. 1. Прямая регрессии (1) проходит через точку (mх,mу). 2. Среднее значение остатков регрессии равно 0:. (16) 3. Остатки {еi} имеют нулевую ковариацию с наблюдаемыми значениями {хi} и регрессии {yri=blxi+b0}: cov(e,x)=0 и cov(e,yr)=0. Если дисперсии var(x) и var(y) не равны 0, то после подстановки в целевую функцию (4) параметров bl и b0 из формул (11) и (15)) получим, (17) где коэффициент корреляции показателей х и y по наблюдениям {хi} и {yi}:. (16) Коэффициент корреляции, в отличие от коэффициента ковариации, является относительной мерой связи показателя и фактора. Если абсолютная величина коэффициента корреляции «близка» к 1, это говорит о «сильной» связи показателей. Если абсолютная величина коэффициента корреляции «близка» к 0, считается, что связи между показателями нет. Это толкование связи показателей обусловлено зависимостью значения f* от rxy: если |rxy| стремится к 1, то f* приближается к 0, а если rxy стремится к 0, то f* приближается к увеличенной в n раз дисперсии var(y) и не зависит от {xi}. Количественная мера связи х и y с помощью наблюдений {хi} и {yi} определяется коэффициента корреляции rxy. Коэффициент корреляции дает меру наилучшей линейной замены показателя y показателем х. Оценивать степень линейной зависимости y от х при действии влияющих на значение {yi} факторов можно и так. Для наблюдения i=1,...,п выполняется равенство yi–my=(yri–my)+(yi–yri). Значение yi–my – общее отклонение, разность (yri–my) – отклонениее, которое можно объяснить, исходя из прямой регрессии (при изменении xi его можно подсчитать по формуле линейной регрессии), а разность (yi–yri) – необъясненное отклонение. Возведем yi–my=(yri–my)+(yi–yri) в квадрат и просуммируем по i:, (18) где используются обозначения. (19)Поделив обе части (18) на п, получим соотношение для дисперсий:, (20) где слагаемое se2 называют дисперсией ошибок. Вклад var(yr) в правой части (20) обусловлен влиянием линейной зависимости y от х. Его относительная величина называется коэффициентам детерминации. (21) Значение R2 совпадает с квадратом коэффициента корреляции rxy. Поэтому коэффициента детерминации неотрицателен и не больше единицы (0?R2?1). Каждой сумме SST, SSR и SSE можно сопоставить определенную степень свободы. Степень свободы – это минимальное число из п результатов наблюдений y1,…,уn за показателем y, которое достаточно для вычисления значения суммы. Для определения SST нужно подсчитать п значений y1–my,...,yn–my. Но они связаны условием, (22) с учетом которого можно обойтись п–1 разностями {yi–my}. Поэтому степень свободы суммы SST равна п–1. Для SSR используют п значений yri–my,...,yrn–my, но легко доказать, что. (23) Поскольку правильно определить значения b1, как функции {yi}, можно независимым варьированием значения лишь одного наблюдения, то степень свободы SSR равна 1. Степень свободы SSE равна п–2. Действительно, подсчет SSE предусматривает знание п значений {yi} и n значений {yri}. Но {yri} определяются через b1 и b0, что уменьшает число независимых значений {уi} на две единицы. Средним квадратом называется сумма квадратов, деленная на число степеней свободы. Средний квадрат объясняющий регрессию и средний квадрат ошибок – это числа и (25) (24) Значения указанных статистических характеристик показателя располагают в базовой таблице дисперсионного анализа (ANOVA-таблица): Число с. с. Сумма квадратов Средние квадраты 1 SSR MSR=SSR/1 n–2 SSE MSE=SSE/(n–2) n–1 SST Если значение R2 близко к 0.5, так обосновать адекватность модели некорректно. В таких случаях используется F-критерий Фишера. Из определения величины R2 следует равенство. (3) Обозначим. (4) Чем больше значение F, тем более адекватно соотношение (1), а чем ближе F к нулю, тем более модель линейной регрессии противоречит наблюдениям. Поскольку и, (5) то величины MSR, MSE и F, как функции случайных величин {yi}, случайны. Проверка модели на адекватность по F-критерию. Выбирается число 1–? – вероятность сделать правильный вывод по данным наблюдений о связи (1) между y и х (вероятность сделать неправильный вывод определяется числом ?, которое не может быть больше 1 и которое называется уровнем значимости критерия). Обычно полагают ?=0.05 или 0.01. По таблице F-распределения Фишера с (1,п–2) степенями свободы и уровнем значимости ? находят критическое значение Fкр (cлучайная величина MSR имеет степень свободы 1, а MSE – n–2). Если выполняется неравенство F?Fкр, то модель (1) адекватна (с вероятностью 1–?) существующей связи у и х. Если выполняется неравенство F<Fкр, то гипотеза отвергается с вероятностью ошибки ?. Этот способ проверки адекватности модели (1) достаточно сложен. Поэтому на практике широко распространены простые способы, которые связаны с отклонением {еi} гипотетических наблюдений {yri} от имеющихся {yi}. Остатком регрессии (ошибкой) называется ei=yi–yri, а гипотетическое значение yri для модели линейной регрессии рассчитывается по формуле yri=b0+b1xi. Приведем другие критерии качества линейной регрессии. 1. Средняя ошибка прогноза (6) Если параметры b0 и b1 вычисляются по МНК, то me=0. В общем случае, если значения b0 и b1 в модели (1) правильно отображают имеющуюся связь между y и х, то me?0 при n??. 2. Дисперсия ошибок и стандартное отклонение и. (7) 3. Среднее абсолютное отклонение. (8) 4. Средняя абсолютная ошибка. (9) 5. Средний квадрат ошибок. (10) 6. Средняя относительная процентная ошибка. (11) Значение MRPE меньше 10 % свидетельствует о правильном выборе значений параметров b0 и b1 в модели (1), которая адекватно отображает имеющуюся зависимость между y и х; от 10 % до 20% – хорошее приближение модели (1) к имеющейся зависимости; от 20% до 50% – удовлетворительное; свыше 50% – модель (1) не отображает имеющуюся связь. Чем меньшие абсолютные значения {еi}, тем более удачно выбраны параметры b0 и bl в модели линейной регрессии. Легко показать, что средний квадрат ошибок MSE, увеличенный в п раз, является целевой функцией МНК. Если качество выбора параметров регрессии оценивать величиной средней абсолютной ошибки MAE, умноженной на п, то это соответствует методу робастного оценивания. Пусть {yi}, i=1,...,п – данные наблюдений показателя y явления, рассчитываемые по известным значениям {хi}, i=1,...,n фактора х. По данным {yi} и {хi} по методу наименьших квадратов были рассчитаны значения b0 и b1, которые конкретизировали линейную зависимость y от х. Предположим, что при тех же {хi} через равноотстоящие промежутки времени вычисления значений y повторили по той же методике. Понятно, что под влиянием случайной ошибки e в каждой серии наблюдений значения показателя будут отличаться. Поэтому и рассчитанные значения параметров b0 и b1 будут случайными. На основе значений {b0,b1} делают статистические выводы о выборе «наилучших» значений параметров ?0 и ?1 модели. (12) Приведем основные предположения. 1. Математическое ожидание случайной величины ?i не зависит от хi и равно 0. 2. Автокорреляция между случайными величинами ?i и ?j отсутствует: cov(?i,?j)=0 для i,j=1,...,n, i?j. 3. Случайные величины {?j} гомоскедастичны, то есть для i=1,...,n. (12) 4. Случайная величина ? распределена нормально, имеет нулевое ожидание и дисперсию ???. 5. Модель (1) точно отображает имеющуюся связь между показателем y и х. При этих предположениях: а) Математическое ожидание и дисперсия случайной величины yi: и . (13) б) Математическое ожидание и дисперсия случайной величины b0: и . (14) в) Математическое ожидание и дисперсия случайной величины b1: и . (15) Дисперсия ??? неизвестна. Поэтому вычисление по формулам (14) и (15) дисперсий случайных величин b0 и b1 невозможно. Но можно доказать, (16) где оценка дисперсии, (17) Это соотношение делает возможным использовать оценку se? вместо ???. Значения b0 и b1 – случайные величины. Они используются как оценки параметров ?0 и ?1 в модели. (1) Определим доверительные интервалы для параметров ?0 и ?1, в которых с заданной вероятностью находятся их значения. Пусть случайная величина B имеет нормальный закон распределения с ожиданием M[B]=? и дисперсией ?2=M[(B–?)2], а плотность ее распределения:. (2) Вероятность попадания B в интервал (bl,bu). (3) Случайная величина (4) имеет нормальный закон распределения, но с нормированными параметрами распределения M[Z]=0 и дисперсией ?2=M[Z2]=1. Подсчитаем вероятность. (5) Нас интересует значение z?, при котором с вероятностью ? выполняется неравенство |Z|?z?. Подынтегральная функция четная, а поэтому вероятность события |Z|?z? равна. (6) Правая часть монотоно увеличивается от 0 до 1 при увеличении z? от 0 до ?. Поэтому при любом ?=P(|Z|?z?)?[0,1) уравнение имеет решение z?. Чтобы не тратить усилия на решение уравнения (5), построены специальные таблицы, которые для уровней доверия (значимости) {?} содержат решения {z?} этого уравнения. Доверительный интервал. (7) Чтобы для нормально распределенной случайной величины Z с известными ? и ?2 при данном ? определить доверительный интервал, нужно найти решение {z?} уравнения (6). Тогда, учитывая соотношение (4), с вероятностью ? выполняются неравенства (7). В частности, при ?=0.9973 имеем zа=3, а выход Z за «трехсигмовые» границы (|Z–z|>3?) считается «практически невозможным». Рассмотрим случай, когда кроме ? известна оценка s2 дисперсии ?2 случайной величины X и эта оценка имеет n–k степеней свободы. Тогда случайная величина (8) имеет распределение Cтьюдента с п–k степенями свободы. Для заданного уровня ??(0,1) можно определить значения t?, для которого. (11) Значение величины T с вероятностью ? удовлетворяет неравенствам. (12) Для уровня доверия ??(0,1) можно построить доверительные интервалы для параметров ?0, ?1 линейной регрессии (1). Пусть для k=0,1, (13) где, (14) Найдем решение t? уравнения P(|T|?t?)=? для случайной величины T, имеющей t-распределение Стьюдента с п–2 степеней свободы. Таким образом, с вероятностью ? выполняются неравенства:, k=0, 1. (15) Вычисленные методом наименьших квадратов значения параметров b0, b1 линейной регрессии yr= b0+b1x между показателями х и у определенного явления используют для прогноза возможных y по заданному значению х. При этом точечный прогноз получается просто: для хn+1 прогнозное значение yrn+1 вычисляется по формуле yrn+1=b1xn+1+b0. Поскольку действительное значение уn+1 отличается от yrn+1, то кроме точечного прогноза составляют интервальний прогноз – доверительный интервал для уп+1. Техника его построения та же, что и для доверительных интервалов параметров ?0 и ?1. Ошибка en+1 прогноза yn+1 дается в виде, (15) а ее математическое ожидание равно нулю. Поскольку (16) то дисперсия ошибки еn+1 (17) где по определению. (18) С учетом того, что b0–?0=–mx(b1–?1), имеем. (19) С учетом выражений (14) и (17), после преобразований получим: (20) Дисперсия ошибки еп+1 минимальна при хn+1=mx и растет нелинейно при отклонении хn+1 от mx. С помощью оценки se стандартного отклонения ??, имеющей n–2 степени свободы, можно построить доверительный интервал для значения уn+1. Если t? является решением уравнения (12) для уровня значимости ??(0,1), то значение уп+1 с вероятностью ? удовлетворяет неравенству. (21) Если линия регрессии y от x имеет вид ?0+?1x, применяют модель, так что для данного x соответствующее значение y состоит из величины ?0+?1x и добавки ?, при учете которой любой индивидуальный y получает возможность не попасть на линию регрессии. Уравнение (1) – это модель, в которую мы верим. Модель нужно всесторонне критически исследовать в разных аспектах. Это наше «мнение» на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины ?0 и ?1 называются параметрами модели. Они неизвестны, а величина ? изменяется от наблюдения к наблюдению. Однако ?0 и ?1 остаются постоянными, и, хотя мы не умеем находить их без изучения возможных сочетаний y и x, можно использовать информацию из наблюдений для получения оценок b0 и b1 параметров ?0 и ?1. Запишем это, где yr обозначает предсказанное значение отклика y для данного x. Мы нашли коэффициент парной корреляции r, служащий оценкой истинного параметра ?. Мы можем получить доверительный интервал для ? или проверить нулевую гипотезу H0: ?=?0 против любой из альтернативных гипотез H1: ???0 или ?>?0, воспользовавшись z-преобразованием Фишера. Так как Z?N(atanh(?),1/(n-3)), то (1–?)-ый доверительный интервал для ? можно получить решением уравнения, где z1-?/2 – верхняя ?/2-ая точка распределения N(0,1) для двух значений ?, которые соответствуют двум альтернативам со знаками плюс и минус в правой части уравнения. В основе критерия для проверки гипотезы лежит статистика. Она сравнивается с процентными точками распределения N(0,1). Альтернативные гипотезы требуют: H1: ???0 – двухстороннего критерия H1: ?>?0 – одностороннего критерия для «верхнего» хвоста распределения и H1: ?<?0 – одностороннего критерия для «нижнего» хвоста распределения. Пусть n=103, r=0.5. Выберем ?=0,05. Тогда уравнение сводится к и 95%-ый доверительный интервал ? получается от 0,329 до 0,632. Значение ?0 за пределами интервала означало бы, что нулевая гипотеза H0: ?=?0 отвергается на 5%-ом уровне двухсторонним критерием против альтернативы H1: ???0. 1 2. Направленные сети Ребра направленного графа называются дугами, а цепь из дуг одного направления называется путем. Если начальная вершина k цепи совпадает с конечной l, цепь называется контуром. На рис.2.1 дана направленная сеть с 4 вершинами и 6 дугами, в также минимальное и максимальное покрывающие деревья, полученные перебором дуг в таблице 2.1. Рис.2.1. Направленная сеть (a) и ее деревья. Таблица 2.1. Построение дерева (слева – min, справа – max). Дуга Вес Линия Букет Дуга Вес Линия Букет 4|3 10 Сплошная 4,3 2|1 35 Сплошная 2,1 1|4 15 Сплошная 4,3,1 2|4 30 Сплошная 2,1,4 1|3 20 Пунктирная 4,3,1 3|2 25 Сплошная 2,1,4,3 3|2 25 Сплошная 4,3,1,2 1|3 20 Пунктирная 2|4 30 Пунктирная 1|4 15 Пунктирная 2|1 35 Пунктирная 4|3 10 Пунктирная Ветви направленного дерева не входят в одну вершину, а корнем является вершина, в которую не входит дуга. Матрица инцидентности графа дана в таблицах 2.2 и 2.3. Корнем минимального дерева является вершина 1, а максимального дерева – вершина 3. Сокращенная 3?6-матрица (без строки корня дерева) A0=[Ab;Ac] содержит матрицу ветвей Ab и матрицу хорд Ac. Таблица 2.2. Матрица инцидентности графа рис.2.1b. A 4|3 1|4 3|2 1|3 2|4 2|1 1 0 1 0 1 0 –1 2 0 0 –1 0 1 1 3 –1 0 1 –1 0 0 4 1 –1 0 0 –1 0 Таблица 2.3. Матрица инцидентности графа рис.2.1c. A 2|1 2|4 3|2 1|3 1|4 4|3 1 –1 0 0 1 1 0 2 1 1 –1 0 0 0 4 0 –1 0 0 –1 1 3 0 0 1 –1 0 –1 Матрицы сечений и контуров направленного графа и, где матрица ветвь-хорда Abc=Ab-1Ac имеет размерность (n–1)?(m+n–1). Ветвь инцидентна сечению, и ему приписывается направление ветви. Ненулевые элементы строки матрицы Abc указывают на совокупность хорд, инцидентных сечению, причем плюс означает, что хорда имеет в сечении направление ветви (минус – направления противоположны). Хорда инцидентна контуру. Ему приписывается направление хорды. Ненулевые элементы строк матрицы AbcT указывают на совокупность ветвей, инцидентных контурам, причем плюс означает, что ветвь имеет направление контура (минус – направления противоположны). Таблица 2.4. Матрицы сечений и контуров графа рис.2.1b. Таблица 2.5. Матрицы сечений и контуров графа рис.2.1с. Если при выборе дерева направленной сети встречается замкнутый путь, его дуги и вершины можно заменить фиктивной вершиной (Эдмондс). Исходная сеть G преобразуется в сеть Gi с фиктивной вершиной i. При i=0 букеты вершин пустые. 1). Выбрать вершину и включить ее в букет. Среди выходящих дуг взять дугу с наибольшим весом и включить в букет вместе с вершиной. Если такой дуги нет, вернуться к шагу 1. Если вершины сети Gi собраны в букет, перейти к шагу 3. Если появился замкнутый путь, перейти к шагу 2. 2). Стянуть дуги и вершины замкнутого пути в вершину i, получить сеть Gі+1. Если дуга (k,l) сети Gi заменена дугой (k,i) сети Gi+1, то ее новый вес, где tmin – минимальный вес дуги в замкнутом пути, а дуга (i,l) замкнутого пути входит в вершину l. Веса выходящих дуг оставить без изменений. Увеличить i на 1 и перейти к шагу 1. 3). Если i=0, закончить поиск. Если i?0, возможны два случая: а) Фиктивная вершина i+1 является корнем дерева. Удалить из замкнутого пути дугу с весом tmin. в) Фиктивная вершина i+1 не является корнем дерева: удалить дугу из замкнутого пути. Уменьшить i на 1 и повторить шаг 3. Рис.2.2. Выбор максимального дерева. В исходной сети G0 рис 2.2 есть замкнутый путь 1|3|2|1 (из двух дуг в вершине 1 выбирается с большим весом). Его заменяем фиктивной вершиной 0. Дуги 1|4 и 2|4 выходящие, их передачи оставляем без изменений. Дуга 4|3 входящая, ее новый вес t(4,0)=t(4,3)+tmin–t(1,3)=10+20–20=10. Если фиктивная вершина 0 является корнем дерева, удаляем дугу 4|0, а из дуг 0|4 выбираем дугу с большим весом. Раскрывая вершину 0, получим направленное дерево рис.2.2с. Если корень максимального дерева в вершине 4, удаляем дуги 0|4, а в раскрытой фиктивной вершине удаляем дугу 1|3, получив дерево 4|3|2|1. Этот алгоритм применяется для сетей с минимальным направленным лесом (знаки весов нужно изменить на противоположные), максимальным покрывающим деревом с весами любого знака (к весам добавить константу), максимальным (минимальным) покрывающим деревом с корнем в заданной вершине (ввести вершину). Чтобы получить направленное дерево с корнем в вершине а, в сеть добавим вершину а? и дугу а?|а с большим весом. Если сеть содержит покрывающее дерево, то его корень в вершине а?, так как в нее не заходят дуги, а дерево исходной сети будет иметь корень в вершине а. Имеется сеть рынков (вершины – рынки, дуги – связи рынков, веса – число сделок). На каком рынке должен находиться представитель фирмы для обслуживания торговых сделок? Рис2.3. Сеть G0 межрыночных сделок фирмы. 1). Индекс i=0, букеты пусты, сеть – G0. Выбираем вершины 1, 4, 5, 2 и дуги с максимальными весами, замкнутый путь 1|4|5|2|1. 2). i=1, состав букета на рис.1 выделен жирными линиями, сеть – G1. Заменим замкнутый путь фиктивной вершиной 0. Новый вес входящей дуги 3|2 равен t(3,0)=t(3,2)+tmin–t(5,2)=16+7–7=16. Рис.2.4. Сеть G1 межрыночных сделок фирмы. Больше замкнутых путей нет. Индекс i уменьшим на единицу. 3). i=0, сеть G0. Раскрываем фиктивную вершину (рис.2.5). Рис.2.5. Покрывающее дерево рыночных сделок. Если представитель фирмы находится на рынке 3, он контролирует 160 торговых сделок. Если фирма может выделить двух представителей, они должны находиться на рынке 2 (51 сделка) и на рынке 3 (109 сделок). Сеть межрыночных сделок в этом случае не имеет покрывающего дерева, но имеет покрывающий лес из двух деревьев. Группа людей нацелена на выполнение определенной задачи. Нужно на основе системы предпочтений членов группы выбрать среди них лидеров. Вершины сети отвечают членам коллектива, дуги – желаниям каждого члена коллектива видеть своим лидером того ли иного члена. Веса дуг – оценка этого желания (баллы). Решение задачи сводится к поиску максимального направленного леса в сети. Корни выявленных деревьев отвечают лидерам. Цель известна членам коллектива, они заинтересованы в быстром ее достижении. Среди них есть лица, способные привести к цели. Члену группы поставим в соответствие вершину сети. Связи вершин отобразим дугами, весами дуг возьмем приоритеты. Каждый из 10 человек указывает два лица с высшей оценкой (левая часть рис.2.6) и нижней оценкой (правая часть). Рис.2.6. Графы предпочтений членов. Выбор лидера коллектива затруднен замкнутым путем 5|4|10|5. ЛПР назначит лидером члена коллектива 5, не согласившись с подчинением 10|5. С учетом проритетов второго плана получаем дерево подчиненности членов коллектива двум руководителям групп и однму лидеру. Рис.2.7. Покрывающее дерево подчинений. Нелинейная модель предложения и спроса Баженов В.К. Спрос q зависит от цены блага p и его полезности u:. Для трех сделок купли-продажи вектор спроса q=Xb – это произведение 3?3-матрицы факторов спроса X на вектор параметров спроса b. Обыкновенный товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=1 единицу того же товара, а полезность u2=p2q2=2. В третьей сделке покупателю удалось по цене p3=1,5 приобрести q3=1 единицу товара, а полезность u3=p3q3+?u больше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 1. Таблица 1. Cпрос на обыкновенный товар. Параметры спроса b=X-1q зависят от величины ?u:, , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса q(p) описывается выражением, где a0=–b0/b2=6?u–1; a1=–b1/b2=1–2?u; a2=–1/b2=2?u–1. Гиффиновский товар. В первой сделке покупатель по цене p1=1 приобрел q1=2 единицы товара, полезность этой сделки u1=p1q1=2. Во второй сделке покупатель по цене p2=1 приобрел q1=3 единицу того же товара, а полезность u2=p2q2=6. В третьей сделке покупатель согласился по цене p3=1,5 приобрести q3=3 единицу товара, полезность u3=p3q3–?u меньше уплаченной денежной суммы на величину ?u>0. Факторы спроса даны в таблице 2. Таблица 2. Cпрос на гиффиновский товар. Параметры спроса b=X-1q зависят от величины ?u: , , . Чтобы получить кривую спроса примем для любой сделки u=pq:. Кривая спроса, где a0=–b0/b2=2?u–3; a1=–b1/b2=2?u+3; a2=–1/b2=2?u–1. Конъюнктура потребительского рынка v>0 для обыкновенного товара и v<0 для гиффиновского товара. Кривую спроса p(q) описывает выражение. Для p>0 нужно иметь a1<q<a0/a2 или a0/a2<q<a1. Величина a1 – объем товара, покупаемого по любой цене (p?? при v>0), a2 – ценовая скидка. Кривые спроса q(p) на обыкновенный товар даны на рис.1 для ?u=0, ?u=0,5 и ?u=1. Спрос на обыкновенный товар при ?u=0 не зависит от цены, а при ?u>0 уменьшается с ценой p. Кривые спроса q(p) на гиффиновский товар даны на рис.2 для ?u=0, ?u=0,5 и ?u=1. Спрос на гиффиновский товар при ?u=0 не зависит от его цены, а при ?u>0 увеличивается с ценой p. Рис.1. Кривые спроса q(p) на обыкновенный товар. Рис.4. Кривые спроса q(p) на гиффиновский товар. Нелинейная экономика в закрытой зоне 1. Введение. Резидентами называются субъекты экономики, которые извлекают доход и уплачивают налоги. В закрытой экономической зоне (ЗЭЗ) число резидентов неизменно (они не участвуют во внешнеэкономической деятельности). Совокупность экономических свойств зоны называют ее состоянием. Для описания состояния ЗЭЗ достаточно знать небольшое число параметров состояния ЗЭЗ, которые связаны между собой уравнениями состояния ЗЭЗ. Окружающая среда характеризуется близкими свойствами и внешними (экзогенными) параметрами. Из них для ЗЭЗ представляют интерес только два: ставка процента ? и ставка налога ?. Ставка процента определяет обмен финансами между ЗЭЗ и окружением, а ставка налога отражает фискальное давление государства на ЗЭЗ. Экономические свойства системы разделяются на экстенсивные и интенсивные. Экстенсивные свойства изменяются с размерами ЗЭЗ (совокупный доход, число резидентов, энтропия), а интенсивные свойства не зависят от размера ЗЭЗ (ставка процента, ставка налога). Если какое-то экономическое свойство изменяется во времени, то говорят, что в ЗЭЗ протекает экономический процесс. Циклическим называют процесс, когда ЗЭЗ возвращается в исходное состояние. Самопроизвольными являются процессы, которые не требуют финансовых вливаний. В результате самопроизвольного процесса ЗЭЗ, в конечном счете, переходит в такое состояние, когда ее свойства больше изменяться не будут - в ЗЭЗ установится равновесие. Равновесным называется такое состояние ЗЭЗ, которое сохраняется неизменным во времени без какого-либо участия окружающей среды. Равновесным называется процесс, который протекает очень медленно через непрерывный ряд состояний. Предельно замедленный процесс называют квазистатическим и экономически обратимым. Реальные экономические процессы необратимы и неравновесны. Необратимость процессов - наиболее яркий факт повседневного опыта. Основным является вопрос, совпадают ли макроэкономические характеристики системы многих резидентов со средними по ансамблю ее микроскопических аналогов. Ансамбль - это совокупность очень большого числа одинаково устроенных систем, причем у каждой отдельной системы есть воображаемая граница. В зависимости от типа границ различают канонический и большой канонический ансамбль. Взаимодействие между системами ансамбля всегда мало, а число резидентов вблизи границы много меньше полного числа резидентов в каждой системе. При выборе ансамбля учитывают флуктуации одних экономических величин и пренебрегают флуктуациями других. Обычно предполагается, что микросостояния системы несущественны для ее макроскопических характеристик, так как их наблюдение занимает определенное время. Микросостояния системы в течение этого времени быстро меняются, так что достигаются все состояния, представляемые данным ансамблем. Поэтому усреднение характеристик по времени для конкретной системы и усреднение по ансамблю приводит к одному и тому же результату (эргодическая гипотеза). Если система слабо связана с окружающей средой при данной ставке процента, если характер этой связи является неопределенным или точно неизвестным, если связь действует в течение длительного времени и, наконец, если все быстрые процессы уже прошли, а медленные – еще нет, то говорят, что система многих резидентов находится в состоянии экономического равновесия. Поведение равновесных систем многих резидентов описывается каноническим распределением Гиббса. 2. Математическая модель. Распределение совокупного дохода Y резидентов ЗЭЗ на потребление C и накопление S зависит как от процентной ставки, так и от налогового климата в зоне. С бухгалтерской точки зрения доход есть разность выручки и издержек. Это положение линейной теории дохода применимо к реальным экономическим системам вблизи состояния устойчивого равновесия. Но современная экономика нелинейная и требует адекватного описания ее состояния [1]. Первый шаг к этому был описан в [2]. Пусть n нумерует резидентов с доходами Yn. Согласно основному принципу статистической механики [3], если известна вероятность и статистическая сумма и , то можно найти совокупный доход Y, накопление S и потребление C [4] как функции ставки процента ?: , и . Дисперсия и асимметрия дохода выражаются в виде и . Энтропия в ЗЭЗ всегда увеличивается со ставкой процента, достигая насыщения при ?=?3=?3/3?2, если ?3>0. Экстенсивная переменная ? является мерой накопления S=??, а интенсивная переменная ? – ее оценкой. И ?, и ? неотрицательны. Для учета налогов используем экстенсивную переменную ?. Чистый доход резидента уменьшается с ростом ?, а определяет ставку налога , где вероятность Pn(?,?) зависит от налога ?, так как Yn зависит от ?. В самом деле, если Xn - валовой доход n-го резидента, то чистый доход можно описать моделью В.В.Леонтьева [5]: Неотрицательная матрица A?0 является продуктивной, если существует вектор X>AX>0. Необходимым и достаточным условием продуктивности системы является существование собственного значения 0<?<1 этой матрицы. Чистый доход резидента зависит от ?, причем он уменьшается с ростом ?. 3. Энтропия. Предположим, что энтропию неравновесной системы можно описать в виде и рассмотрим ее изменение во времени:. Чтобы оценить изменение вероятности во времени, воспользуемся уравнением Паули, где wnn` - условная вероятность перехода. Подстановка дает. Полное число прямых переходов системы в единицу времени из состояния n в состояние n? не равно числу обратных переходов. Однако, при экономическом равновесии они совпадают:. Этот принцип детального равновесия означает d?/dt=0, что является достаточным условием экономического равновесия. Состояния, участвующие в установлении детального равновесия, очень близки по доходу друг к другу и Pn~Pn`. Следовательно, можно принять. Если принять этот принцип микроскопической обратимости, то . Каждое слагаемое здесь положительно, а поэтому энтропия неравновесной системы возрастает со временем. 4. Условия равновесия. В закрытой зоне имеются две пары сопряженных переменных (?,?), (?,?) и четыре потенциала C(?,?), I(?,?), T(?,?), Y(?,?) с дифференциалами, , , . Потребление C вычисляется по статистической сумме Q(?,?). Доход Y=С+?? включает потребление и накопление S=??. Большое потребление I=C+?? включает потребление и налоги L=??, а большое накопление T=C+??+??. Экономические потенциалы С(?,?), I(?,?), T(?,?), Y(?,?) аддитивны, а ставки ? и ? одинаковы для всех резидентов. Поэтому потенциалы должны быть однородными функциями первого порядка по переменным ? и ?: , , , , где N – число резидентов, а ?, ?, ? и ? – некоторые функции. Если рассматривать N как независимую переменную, в выражения для дифференциалов dC, dI, dT, dY нужно добавить ?dN при Дифференцируя I по N, получаем ?(?,?): оценка ? резидентов есть функция процентной ставки ? и налоговой ставки ?. Большой потенциал ?=С-?N является функцией ?, ? и ?: . Поскольку ?N=I и I=C+??, то ?=-?N. Если доход n-ого резидента в открытой экономической зоне обозначить , то вероятность дохода. Накопление теперь зависит от дохода Y, среднего числа резидентов и большой статистической суммы: , и . Такая открытая система называется большим каноническим ансамблем [6]. Экономические процессы в закрытой зоне сопровождаются ростом энтропии, пока она не достигнет наибольшего значения, соответствующего полному равновесию. Пусть взаимозависимые переменные ?, ? и ? отвечают любой тройке факторов ?, ?, ? и ?. Тогда ?-ой эластичностью фактора ? при неизменном факторе ? называется величина ???=?(??/??)?. Статистическая теория дает точную формулировку условий равновесия. Если окружающая среда характеризуется ставками процента ?* и налога ?*, то необходимые и достаточные условия устойчивого равновесия ЗЭЗ: и , и . Статистическая оценка этих эластичностей: и , где означает усреднение с учетом вероятности Pn. Неравенства означают, что дисперсия положительна, а ставка налога уменьшается с налогом при неизменной ставке процента. Налог как функция потребления и ставки процента имеет частные производные: , , , , . Можно доказать, что флуктуации налога и ставки процента статистически независимы =0. Квадратичные флуктуации налога и ставки процента: и . Для устойчивости дохода требуется, чтобы флуктуация налога не возрастала, т.е. . Конъюнктура как функция дохода и налога имеет частные производные: , , , ,. Можно также доказать, что флуктуации конъюнктуры и ставки налога статистически независимы =0. Квадратичные флуктуации конъюнктуры и ставки налога: и . Для устойчивости дохода требуется, чтобы флуктуации ставки налога не возрастали, т.е. . 5. Простая экономическая зона. Закрытую экономическую зону назовем простой, если статистическая сумма, где N – число резидентов, а L зависит только от ставки процента ?. Потребление в простой зоне:, где f(?)=?lnL(?), а конъюнктура ?(?,?) и ставка налога ?(?,?): и . Эластичности этих факторов: и . Простая зона устойчива только при и ? > 0. Идеальной назовем простую зону с . Для идеальной зоны: , где ? и – постоянные интегрирования. Без потери устойчивости можно принять ?=0,. Потенциалы идеальной зоны: , , и , где ???=???+N. Энтропия и ставка налога в идеальной зоне: ?(?,?)=???ln ? + N(1+ln ?) и ?(?,?) = N?/?. Зависимости C и S=Y-C от ? приводятся на рис.1 для шести значений ?. Накопление возрастает нелинейно со ставкой процента и уменьшается с ростом налога. Рис.1. Потребление и накопление в идеальной системе как функция ставки процента для шести значений налога. Использованы относительные единицы C/???, S/???, N=2???. Число резидентов невелико при большом бизнесе. Конъюнктура в идеальной зоне с заданной ставкой налога зависит от ставки процента и числа резидентов: Эта зависимость показана на рис 2. С ростом числа резидентов конъюнктура возрастает при фиксированных ставках процента и налога. Это означает, что норма накопления при контролируемых ставках увеличивается с числом резидентов, т.е. с переходом от большого к малому бизнесу. Резиденты малого бизнеса слабо взаимодействуют друг с другом в идеальной зоне и представляют собой однородную массу, а их доход линейно зависит от ставки процента. Основной недостаток идеальной системы состоит в том, что доход резидентов здесь расходится при ?=0. Этот налоговый коллапс не должен допускаться государством, которое может установить минимальный предел ?0. Рис.2. Зависимость конъюнктуры идеальной системы от ставки налога для четырех значений числа резидентов. Использованы относительные единицы ?/???, N/??? и значение ставки налога ?=0,5. 6. Закрытая зона. Невозможность беспредельного уменьшения налога для закрытой зоны дает выбор потребления в виде, так как при ?<?0 аргумент логарифма станет отрицательным. Появление константы a>0 вызвано необходимостью обеспечения глобальной устойчивости бизнеса в закрытой зоне. Энтропия и ставка налога получаются с помощью дифференцирования: ?(?,?) = ???ln ? + N[1 + ln(?-??)} и . Состояние закрытой зоны с и назовем критическим: и . Для устойчивости критического состояния необходимо иметь или . Для критического состояния закрытой зоны: , и . Если ?>??, то ???=?(??/??)?<0 и состояния не отличаются существенно от состояний идеальной зоны. Однако при ?<?K уравнение состояния зоны имеет уже три действительных корня ?1<?2<?3, которым отвечают два устойчивых ?1,?3 и одно неустойчивое ?2 состояние. Область неустойчивости ограничена налогами ?`2 и ?`3. Зависимость ? от ? и ? показана на рис.3, где кривая ?1(?) проходит через экстремальные точки налоговых ставок (под этой кривой находится область неустойчивых состояний систем неидеальной зоны). Рис.3. Зависимость ставки ? налога от налога ?. Минимуму ?(?) отвечает значение ?2=?(?`2), а максимуму – значение ?3=?(?`3). При ?>?3 все резиденты уплачивают меньший налог ?1, а при ?<?2 – больший налог ?3. При ?2<?<?3 происходит налоговое «расслоение» резидентов: N? ?-резидентов платят малый налог ?1, а N? (=N-N?) ?-резидентов – большой налог ?3. Состояния ?-резидентов с налогом ?1<?<?`2 является метастабильным («перегретым»), как и состояние ?-резидентов с налогом ?`3<?<?3 («переохлажденным»). Равновесному переходу ?-резидентов в ?-резиденты соответствуют вертикальные прямые отрезки на рис.4, положение которых определяется условиями равновесия:. Рис.4. Зависимость налога ?/?K от ставки налога ?/?K (при ?=7?K/8) и границ области неустойчивости ?`/?K от ставки процента ?/?K. Значения ?` уменьшены в 100 раз, а ?` - в 10 раз. 6. Выводы. Равновесие резидентов зоны при определенных ставках ? и ? достигается при равенстве больших потреблений, что задает кривую равновесия ?=?(?). Пересечение этой кривой сопровождается расслоением резидентов на две фазы, после чего в зоне остаются резиденты только одного типа. Переход из ?-фазы в ?-фазу сопровождается скрытым накоплением S??=?(??-??). Если ?=?*+?? и ?=?*+??, то при ??<<?* и ??<<?* из равенства больших потреблений следует:, где ???=??-?? – приращение налога при переходе. Это уравнение определяет изменение ставки налога со ставкой процента вдоль кривой равновесия ?- и ?-резидентов. Налог ?-резидентов всегда больше налога ?-резидентов, а энтропия ?-резидентов всегда больше энтропии ?-резидентов. Поэтому d?/d?>0 в закрытой зоне: ставка налога возрастает со ставкой процента. 3. Непрерывные распределения Характеристическая функция нормального распределения со средним ? и дисперсией ?2 равна, а характеристическая функция выборочного среднего. Если вместо m рассмотреть m–?, получим. Это характеристическая функция нормального распределения с дисперсией. Для стандартного нормального распределения (?=0, ?2=1) имеем. Произведем выборку X1,X2,...,Xn из этого распределения и составим сумму квадратов элементов выборки. 5. Многомерное распределение Совместное нормальное распределение n случайных величин X=(X1,...,Xn) имеет плотность вероятности, где число k определяется условием равенства полной вероятности единице, x и m являются n-мерными веркторами, а B – n?n-матрицей. Функция f(x) симметрична относительно x–m: и M[X–m]=0 или M[X]=m. Дифференцируя интеграл по m, получаем. Математическое ожидание величины в квадратных скобках равно нулю:. Ковариационная матрица случайных величин X=(X1,...,Xn) связана с матрицей B:. Рассмотрим подробнее нормальное распределение двух случайных величин:. Введем обозначения, и . Обращая матрицу C, получаем. При нулевой ковариации (X1 и X2 независимы) матрица B принимает вид. Плотность вероятности в этом случае – произведение одномерных нормальных распределений:. Число k в этом случае равно. В общем случае n случайных величин и ненулевых ковариаций, где |B| – определитель матрицы B. Нормальное распределение зависимых случайных величин более сложно. Воспользуемся нормированными величинами (i=1,2). Теперь плотность вероятности принимает вид, где. Линии, на которых плотность вероятности постоянна, определяются из условия равенства постоянной величине c показателя экспоненты:. Примем сначала c=1. Тогда для исходных случайных величин получим. Это уравнение эллипса с центром в точке (m1,m2). Главные оси эллипса образуют угол ? с осями координат x1 и x2. Этот угол и полуоси p1 и p2 можно найти по известным формулам для конических сечений:,,, Это формулы относятся к ковариационному эллипсу двумерного нормального распределения. Ковариационный эллипс расположен внутри прямоугольника со сторонами 2?1 и 2?2 и с центром в точке (m1,m2). Он касается сторон прямоугольника в четырех точках. В предельных случаях, когда ?=?1, эллипс становится прямой, совпадающей с одной из диагоналей прямоугольника. Другие линии постоянной вероятности (при c?1) представляют собой эллипсы, подобные ковариационному эллипсу и расположенные внутри него для большей вероятности и снаружи него при меньшей вероятности. Следовательно, двухмерное нормальное распределение отвечает поверхности в трехмерном пространстве, горизонтальными сечениями которой являются концентрические эллипсы. Для наибольшей вероятности этот эллипс вырождается в точку (m1,m2). Вертикальные сечения, проходящие через центр распределения, имеют форму гауссовской функции, ширина которой прямо пропорциональна оси ковариационного эллипса, вдоль которого производится сечение. Если h(X1,X2) – дифференцируемая функция случайных переменных X1 и X2, то в обозначениях m1=M[X1], m2=M[X2], можно получить и, где, для i=1,2.. Если X1 и X2 не коррелированы (и тем более, если они независимы), приближение для дисперсии сводится к. Для произведения X1X2 независимых случайных переменных и, Для отношения X1/X2 независимых случайных переменных и, Случайные величины с положительными значениями могут подчиняться плотности вероятности, которая характеризует логнормальное распределение. Если значения случайной переменной лежат в интервале (a,b), то значения преобразованной переменной могут изменяться от -? до ?. Это преобразование Фишера используется в случае выборочного коэффициента корреляции. Случайная величина нормализуется с помощью интеграла вероятности ?(x). Преобразование X в Y при ?(Y)=F(X) дает стандартную случайную величину Y. Величина y=?-1(z) или y=5+?-1(z) называется пробитом z. Преобразование «логит» заменяет p на z=lnp/(1–p). Если задана функция распределения F(x) случайной величины Х, то преобразованная переменная U=F-1(X) будет иметь равномерное распределение в области (0,1). Равномерное распределение служит основой получения моделей. Случайная величина распределена экспоненциально (показательно) при, где ?>0 – параметр распределения. Это распределение является основным в теории марковских процессов, так как имеет свойство отсутствия последействия. Плотность вероятности распределения Вейбулла, где ? – параметр формы, ? – характеристическое время жизни. Это распределение либо совпадает с экспоненциальным (?=1), либо приближается к логнормальному (?>1). Подбирая величины ? и ?, можно добиться согласия с опытными данными. | |||
| 17 | ЗАО «Антипинский НПЗ» | Группа NewStream | |
Дата добавления: 2019-07-17; просмотров: 285; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!