Опис організації вхідних та вихідних даних
Нейронні мережі нового покоління
Курсова робота
2007
Анотація
Пояснююча записка складається з основних розділів, які пов’язані з аналізом й обґрунтуванням теми магістерської роботи, призначенням і областю застосування, описом функціональних можливостей програми, вибором технічних і програмних засобів, організації вхідних та вихідних даних, розглядом очікуваних техніко - економічних показників та списком використаних джерел при розробці програмного продукту.
Програмний документ містить: розділів - 3, сторінок - 27.
Зміст
Анотація
Перелік умовних позначень
Вступ
1. Призначення і область застосування
2. Технічні характеристики
2.1 Постановка задачі на розробку програми
2.2 Опис алгоритму і функціонування програми
2.2.1 Огляд програм - аналогів
2.2.2 Теорія розкладів
2.2.3 Генетичні алгоритми
2.2.4 Нечіткі системи
2.3 Опис організації вхідних та вихідних даних
2.4 Опис організації вибору технічних і програмних засобів
2.5 Охорона праці
3. Очікувані техніко-економічні показники
3.1 Визначення трудомісткості розробки програмного продукту
3.2 Визначення собівартості години роботи на ПК
3.3 Розрахунок витрат на створення програмного продукту
3.4 Визначення договірної вартості на програмний продукт
3.5 Розрахунок ефективності впровадження програмного продукту
Список використаних джерел
Перелік умовних позначень
|
|
|
ГА - генетичні алгоритми
ПК - персональний комп’ютер
РМ - робоче місце
Вступ
В пояснюючій записці розглядається розробка на тему „Використання генетичних алгоритмів для складання розкладу” з умовним позначенням 482.362.80915-71.
Завдання на магістерську роботу затверджене на засіданні кафедри КСМ факультету комп’ютерних наук Чернівецького національного університету імені Юрія Федьковича, протокол засідання кафедри № 1 від 28 серпня 2006 р.
Призначення і область застосування
Розроблена програма повинна забезпечити створення розкладу для факультету вузу на основі навчального навантаження для груп з врахуванням вимог і побажань викладачів, а також наявності приміщень для проведення занять. Розклад складається на один семестр, при цьому враховується можливість навчання по першому і другому тижнях. Отриманий варіант розкладу повинен експортуватися в MS Excel з форматуванням, яке забезпечує його зручне й ефективне використання.
Область застоcування програми - складання розкладу для факультетів вищих навчальних закладів України.
Технічні характеристики
Постановка задачі на розробку програми
|
|
|
Розроблена програма повинна забезпечити створення розкладу для факультету вузу. Розклад складається на один семестр, при цьому потрібно врахувати можливість навчання по першому і другому тижнях. Врахувати об’єднання навчальних груп у потоки, а також поділ груп на підгрупи. При складанні розкладу потрібно мінімізувати кількість „вікон” для студентів і викладачів, кількість переходів між приміщеннями і корпусами, врахувати пристосованість приміщень для проведення занять; вимоги викладачів до вільних пар. Отриманий варіант розкладу повинен експортуватися в MS Excel у вигляді таблиці з відповідним форматуванням.
Опис алгоритму і функціонування програми
Огляд програм - аналогів
Розглянемо дві сучасні програми для складання розкладу: „AVTOR-2+" та „Ректор 3.7.9" [1]. За своїми характеристиками програми-аналоги подібні, зокрема різні їх модифікації дозволяють складати розклад як для шкіл, так і для вузів. Основні характеристики програм-аналогів наступні:
1) виконують мінімізацію кількості "вікон" для навчальних груп і викладачів;
2) враховують час переходу між приміщеннями;
3) дозволяють поділ навчальних груп на підгрупи;
4) враховують пристосованість приміщень для проведення занять;
|
|
|
5) виконують експорт розкладу в документи Word і Excel.
Програми „AVTOR-2+" та „Ректор 3.7.9" можуть складати розклад для шкіл за допустимий час. Наприклад, при використанні комп’ютера з процесором Intel Celeron 400 МГц й 256 МБ оперативної пам’яті розклад для старших класів школи (13 навчальних груп) створюється приблизно за 40 хв. В той же час при складанні розкладу для факультету вузу час розрахунку значно збільшується. Крім того, перелічені програми-аналоги є платними (вартість до 4 тис. грн), а безкоштовні програми для складання розкладу є або демонстраційними версіями, або показують значно гірші результати [1].
В результаті аналізу програм-аналогів зроблено наступні висновки:
1) при розробці програми для складання розкладу слід врахувати особливості факультетів вузів;
2) програма повинна мінімізувати кількість "вікон" для навчальних груп і викладачів, а також кількість переходів між приміщеннями (а особливо - між корпусами);
3) програма повинна забезпечити експорт розкладу в документи MS Excel;
4) для зменшення часу складання розкладу та підвищення його якості використати новий метод - генетичні алгоритми.
Теорія розкладів
|
|
|
Теорія розкладів досліджує задачі, в яких необхідно впорядкувати, тобто визначити послідовність виконання сукупності робіт, використання певних засобів та ін. До таких задач відносяться, наприклад, задачі складання розкладу для навчальних закладів [2].
У загальному формулюванні задача складання розкладу полягає у наступному. За допомогою деякої множини ресурсів або обслуговуючих пристроїв повинна бути виконана певна фіксована система завдань. Мета полягає в тому, що при заданих властивостях завдань і ресурсів, а також накладених на них обмежень, знайти ефективний алгоритм впорядкування завдань.
Загальна теорія розкладів передбачає, що всі обслуговуючі пристрої (або процесори) не можуть виконувати в даний момент часу більше одного завдання. Проте для розкладу навчальних занять така умова є достатньою, якщо в якості процесора при розподілі занять прийняти навчальну аудиторію. Так в деяких випадках в одній аудиторії можуть проводитися заняття з більш ніж з однією групою одночасно.
Таким чином формулювання задачі складання розкладу для навчальних закладів можна записати наступним чином: „Для заданого набору навчальних аудиторій (в даному випадку під навчальною аудиторією розуміється широкий круг приміщень, в яких проводяться навчальні заняття: від комп’ютерного класу до спортивного залу) і заданого набору часових інтервалів (навчальних пар) побудувати такий розподіл навчальних занять для всіх об’єктів (викладачі і навчальні групи), для якого вибраний критерій оптимальності буде найкращим.
Пошук оптимального або близького до оптимального розкладу виконується за допомогою одного з 4 підходів:
1) математичного програмування;
2) комбінаторного;
3) евристичного;
4) статистичного (ймовірнісного).
При використанні методів математичного програмування для розв’язку задач складання розкладу неминуча експоненційна складність часу розв’язку задачі. Для скорочення перебору використовуються різноманітні методи, зокрема методів віток і границь.
Комбінаторний метод зводиться до цілеспрямованої перестановки пар робіт в деякій послідовності, поки не буде отримано оптимальне (або близьке до оптимального) рішення.
Евристичні алгоритми засновані на прийомі зниження вимог. Він полягає у пошуку рішення, близького до оптимального, за допустимий час. Широко використовується так званий метод локального пошуку. При цьому наперед вибрана множина перестановок використовується для послідовного покращення початкового розв’язку до тих пір, поки таке покращення можливе, в іншому випадку буде отримано локальний оптимум.
Ймовірнісні методи полягають у випадковому виборі послідовності виконання робіт. Вибір повторюється багато разів, в результаті чого вибирається найкращий варіант розкладу.
Згідно з вищесказаним складемо математичну модель розкладу для факультету вузу:
Період розкладу QW = 2 тижні (1 і 2 тиждень, 10 робочих днів), номер тижня w=1. QW.
День тижня d=1. QD; де QD=10.
Номер пари z=1. QZ, де QZ=8.
Номер дисципліни j=1. QJ.
Для оптимізації навчального процесу групи слід об’єднувати в потоки, якщо в групах одного курсу читається лекція з однієї дисципліни.
Генетичні алгоритми
Генетичні алгоритми ГА (Genetic Algorithms) є складовою еволюційних методів, оскільки виникли у результаті спроб копіювання еволюції живих організмів. Ідея генетичних алгоритмів вперше висловив Дж. Холланд в кінці 60-х років ХХ століття. Суть методу полягала у створенні комп’ютерної програми, яка б вирішувала складні задачі так, як це робить природа - шляхом еволюції. Відповідно у ГА використовують поняття, запозичені з генетики [3-5].
За допомогою ГА задача вирішується наступним чином. Спочатку створюється математична модель штучного світу, який населений N істотами (особинами), причому генетичний код кожної особини - це деякий розв’язок задачі (допустимий варіант розкладу). Генетичний код кожної особини (генотип) записується у вигляді однієї хромосоми Х. Разом всі особини утворюють популяцію Р={X1, Xn,. ., XN}. У свою чергу кожна хромосома є набором з М генів Ge (кожен ген описує одне заняття), тобто X={Ge1, Gem, GeM}. Відповідно до видів занять існує три типи генів: потоки, заняття групи та підгруп. Кожний ген Ge={AL1,..., ALl,..., ALL} є послідовністю з L аллелів AL (цілих чисел), які описують одне заняття: номер групи, пари, дня, тижня, кількість підгруп і номер підгрупи, номери дисципліни, викладача, виду заняття, приміщення. Особина вважається тим більш пристосованою, чим краще рішення задачі вона забезпечує (мінімальне значення цільової функції F).
ГА подібні до еволюційних стратегій, але еволюційні стратегії оперують векторами дійсних чисел, а ГА - двійковими векторами.
Імітуючи еволюцію на комп'ютері часто використовується стратегія елітизму, яка полягає у збереженні життя кращому з індивідуумів поточного покоління.
За сучасними уявленнями еволюція - це процес постійної оптимізації біологічних видів. В класичних задачах оптимізації можна керувати декількома параметрами (позначимо їх значення через g1,… gM), а метою є максимізація (або мінімізація) деякої функції F (g1,… gM). Функція F називається цільовою функцією. Наприклад, якщо вимагається максимізувати цільову функцію "дохід компанії", то керованими параметрами будуть число співробітників компанії, об'єм виробництва, ціни товари і т.д. Цільова функція також називається функцією пристосованості (fitness function) або функція оцінки, яка дозволяє серед популяції особин виділити найкращих.
У випадку розкладу цільова функція F забезпечує: мінімізацію кількості вікон для навчальних груп та викладачів, мінімізацію переходів між приміщеннями і корпусами, рівномірний розподіл занять з кожної дисципліни за днями тижня; враховує пристосованість приміщень для проведення занять; вимоги викладачів до вільних пар.
Існує багато методів рішення оптимізацій них задач. У випадку, якщо цільова функція достатньо гладка і має тільки один локальний максимум (унімодальна), те оптимальне рішення можна одержати методом градієнтного спуску. Ідея цього методу полягає у тому, що оптимальне рішення знаходиться методом ітерацій. Тобто береться випадкова початкова точка, а потім в циклі відбувається зміщення цієї точки на малий крок в тому напрямі найшвидшого зростання цільової функції. Недоліком градієнтного алгоритму є дуже високі вимоги до функції - на практиці унімодальность зустрічається украй рідко, а для інших функцій градієнтний метод часто приводить до неоптимальної відповіді. Аналогічні проблеми виникають із застосуванням інших математичних методів.
Генетичний алгоритм являє собою метод, який відображає природну еволюцію методів вирішення проблем, у першу чергу задач оптимізації. Генетичні алгоритми - це процедури пошуку, засновані на механізмах природного відбору і спадкування. У них використовується еволюційний принцип виживання найбільш пристосованих особин. Га відрізняються від традиційних задач оптимізації кількома моментами:
ГА оброблюють не значення параметрів самої задачі, а їх закодовану форму;
виконують пошук рішення виходячи не з однієї точки, а з деякої популяції;
використовують тільки цільову функцію, а не її похідні або іншу додаткову інформацію;
використовують ймовірнісні, а не детерміновані правила відбору.
Основний (класичний) генетичний алгоритм складається з наступних кроків (рис.2.1):
1. Ініціалізація, або вибір початкової популяції хромосом.
2. Оцінювання пристосованості хромосом в популяції
3. Перевірка умови закінчення алгоритму.
4. Селекція хромосом
5. Використання генетичних операторів
6. Формування нової популяції
7. Вибір найкращої хромосоми
Розглянемо ГА більш детально:
1. Ініціалізація, або вибір початкової популяції хромосом. Полягає у випадковому виборі заданої кількості N хромосом (особин).
2. Оцінювання пристосованості хромосом в популяції полягає у розрахунку функції пристосованості для кожної хромосоми pS (Xi). Приймається, що функція пристосованості завжди приймає невід’ємні значення. Звичайно знаходиться максимум цієї функції.
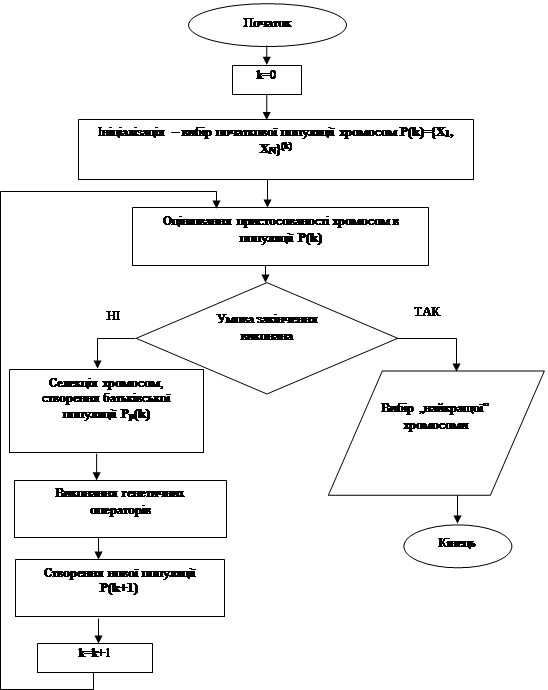 |
Рис.2.1 Алгоритм класичного ГА.
3. Перевірка умови закінчення алгоритму. Алгоритм може бути закінчений, якщо його виконання не приводить до покращення отриманого результату або через певний проміжок часу. .
4. Селекція хромосом полягає у виборі на основі функції пристосованості тих хромосом, які будуть приймати участь у створення нащадків, тобто нового покоління. Такий вибір виконується згідно принципу природного відбору, за яким найбільші шанси на створення потомства мають хромосоми з найвищими значеннями функції пристосованості. Існують різні методи селекції. Найбільш популярним вважається метод рулетки. Кожній хромосомі ставиться у відповідність сектор колеса рулетки, величина якого пропорційна до функції пристосованості даної хромосоми. Ймовірність селекції хромосоми Xi, i=1. N (для випадку, що функція F максимізується):
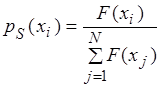 .
.
Таким чином, ймовірність селекції найбільша для хромосом з великим значенням функції пристосованості. У результаті селекції формується батьківська популяція з чисельністю N у яку особини з великим значенням pS (Xi) можуть увійти кілька разів, а з малим значенням pS (Xi) - жодного.
5. Використання генетичних операторів до відібраних у результаті селекції батьківських хромосом приводить до створення популяції нащадків. В класичному ГА використовують два основних генетичних оператора: оператор схрещування (crossover) і оператор мутації (mutation). Як і живих організмах, ймовірність мутації звичайно дуже мала (рм<0,1).
В ГА мутація може виконуватися на популяції батьків перед схрещуванням або на популяції нащадків, утворених у результаті схрещування.
Оператор схрещування. На першому етапі схрещування вибиваються пари хромосом з батьківської популяції. Операції схрещування полягають у обміні фрагментами ланцюжків між двома батьківськими хромосомами (рис.2.2). Далі для кожної пари вибирається позиція гена (локус) в хромосомі, який визначає точку схрещування. Якщо хромосома містить L двійкових чисел, то точка схрещування LK вибирається випадковим чином з інтервалу [1, L]. В результаті схрещування утворюються два нащадки:
1) нащадок, хромосома якого на позиціях від 1 до LK складається з генів першого предка, а позиції від LK+1 до L - з генів другого предка.
2) нащадок, хромосома якого на позиціях від 1 до LK складається з генів другого предка, а позиції від LK+1 до L - з генів першого предка.
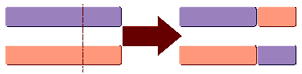
Рис.2.2 Умовна схема кросовера
6. Формування нової популяції. Хромосоми, отримані у результаті генетичних операторів до популяції предків, утворюють нову популяцію. Така популяція стає поточної для даної ітерації k ГА. На кожній ітерації розраховується значення функції пристосованості для всіх хромосом. В результаті перевірки умови закінчення ітерацій відбувається або зупинка алгоритму, або перехід до нового кроку ГА - селекції. В результаті селекції вся попередня популяція замінюється популяцією нащадків з кількістю N. Етап схрещування і мутації також називається еволюцією, на якому відбувається рекомбінація генів у хромосомах.
7. Вибір найкращої хромосоми. Найкращою вважається хромосома з максимальним значенням функції пристосованості.
Головний фактор еволюції - природний відбір, тобто природна селекція, приводить до того, що виживають найбільш пристосовані особини.
Генетичний алгоритм є комбінованим методом. Механізми схрещування і мутації в якомусь значенні реалізують переборну частину методу, а відбір кращих рішень - градієнтний спуск. Така комбінація дозволяє забезпечити стійко хорошу ефективність генетичного пошуку для будь-яких типів задач.
Нечіткі системи
За допомогою нечітких множин можна формально визначити неточні та багатозначні поняття, такі як "висока температура", "молодий чоловік", "середній зріст" або "велике місто" [3]. Перед формулюванням визначення нечіткої множини необхідно задати так звану область значень (universe of discourse). В випадку неоднозначного розуміння "багато грошей" великою буде визнана одна сума, якщо ми обмежимось діапазоном [0, 1000 грн.] та зовсім інша в діапазоні [0, 1000000 грн.]. Область значень, далі будемо називати простором або множиною, буде позначатись символом Х. Необхідно пам’ятати, що Х - чітка множина.
Визначення. Нечітка множина А в деякому (не порожньому) просторі Х, що позначається як А Í Х, називається множиною пар
A = { (x,mA (x)); xÎX} (2.1)
де
mA: X® [0,1] (2.2)
функція приналежності нечіткої множини А. Ця функція приписує кожному елементу х Î Х степінь його приналежності до нечіткої множини А, при цьому можна виділити три випадки:
1) mA (x) = 1 означає повну приналежність елемента х до нечіткої множини А, тобто х Î А;
2) mA (x) = 0 означає відсутність приналежності елемента х до нечіткої множини А, тобто х Ï А;
3) 0 < mA (x) < 1 означає часткову приналежність елемента х до нечіткої множини А.
В літературі застосовується символьне описання нечітких множин. Якщо Х - це простір з кінцевою кількістю елементів, тобто Х = {x1, …, xN}, то нечітка множина А Í Х записується у вигляді
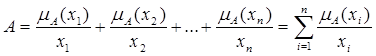 (2.3)
(2.3)
Приведений запис має символьний характер. Знак "-" не означає ділення, а означає приписування конкретним елементам х1, …, хn степенів приналежності mA (x1),…, mA (xn). Іншими словами, запис
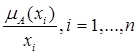 . (2.4)
. (2.4)
означає пару
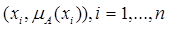 . (2.5)
. (2.5)
Так само знак "+" в виразі (2.3) не означає операцію додавання, а інтерпретується як множинне сумування елементів (2.5). Слід зазначити, що так само можна записувати і чіткі множини. Наприклад, множину шкільних оцінок можна символічно записати як
D = 2 + 3 + 4 + 5, (2.6)
що рівнозначно запису
D = {2, 3, 4, 5}. (2.7)
Якщо Х - це простір з нескінченною кількістю елементів, то нечітка множина А Í Х символічно записується у вигляді
Приклад. Якщо X = R, де R - множина дійсних чисел, то множину дійсних чисел "близьких до числа 7", можна визначити функцією приналежності вигляду (рис.2.3)
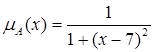 . (2.8)
. (2.8)
Тому нечітка множина дійсних чисел, "близьких до числа 7", описується виразом
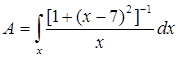 . (2.9)
. (2.9)
На рисунку 2.3 представлені дві функції приналежності нечіткої множини А дійсних чисел, "близьких до числа 7".
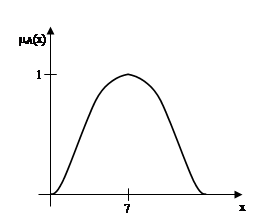 |
а) б)
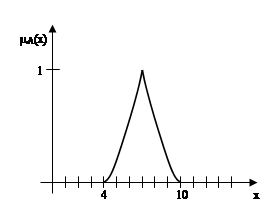 |
Рис.2.1 Функції приналежності нечіткої множини дійсних чисел, "близьких до числа 7"
Опис організації вхідних та вихідних даних
В якості вхідних (початкових) даних використано: навчальне навантаження викладачів (кількість занять для навчальних груп із визначених дисциплін); вимоги до послідовності проведення занять; пристосованість приміщень для проведення занять; поділ груп на підгрупи, умови їх об’єднання у потоки; вимоги викладачів до вільних пар або днів та ін. За змістом вхідні дані поділені на таблиці бази даних.
Вихідними даними програми є допустимий варіант розкладу. Розклад являє собою таблицю, в якій стовпці відповідають певній навчальній підгрупі, а рядки - певній парі з вказанням назви дисципліни, прізвища викладача та назва приміщення.
Проміжними вихідними результатами є варіант розкладу для покоління з номером k.
Дата добавления: 2019-07-15; просмотров: 637; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!