Построение ассоциативной памяти.
МИНОБРНАУКИ РОССИИ
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ
БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
«САМАРСКИЙ ГОСУДАРСТВЕННЫЙ АЭРОКОСМИЧЕСКИЙ
УНИВЕРСИТЕТ имени академика С.П. КОРОЛЕВА
(национальный исследовательский университет)»
ИССЛЕДОВАНИЕ КЛАССИФИКАТОРА НА НЕЙРОННЫХ СЕТЯХ
Методические указания к лабораторной работе
САМАРА
2016
МИНОБРНАУКИ РОССИИ
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ
БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
«САМАРСКИЙ ГОСУДАРСТВЕННЫЙ АЭРОКОСМИЧЕСКИЙ
УНИВЕРСИТЕТ имени академика С.П. КОРОЛЕВА
(национальный исследовательский университет)»
ИССЛЕДОВАНИЕ КЛАССИФИКАТОРА НА НЕЙРОННЫХ СЕТЯХ
САМАРА
2016
УДК 519.688
Составитель: Конюхов В.Н.
Исследование классификатора на нейронных сетяхметод. указания к лабораторной работе/ Самар. гос. аэрокосм. ун-т; Сост. В.Н. Конюхов, Самара, 2016. 24с.
В методических указаниях изложены сведения об основных методах обработки биомедицинских данных с помощью нейронных сетей, в частности, таких как классификация векторов данных. Показаны области применения, назначение и ограничения. Рассмотрены вопросы построения и обучения многослойного персептрона для классификации QRS-комплексов электрокардиосигнала с использованием встроенных средств пакета Matlab.
Пособие разработано на каф. радиотехники и МДС радиотехнического факультета для магистрантов направления подготовки 12.04.04 (Биотехнические системы и технологии ) и выполняющих лабораторные работы по дисциплине «Математические методы обработки медико-биологических данных»
|
|
|
Печатаются по решению редакционно-издательского совета Самарского государственного аэрокосмического университета им. академика С.П. Королёва
Рецензент: доц. Кудрявцев И.А.
Цель работы: изучение методов классификации биомедицинских данных с помощью нейронных сетей, способов обучения нейронных сетей, а также основных характеристик и особенностей построения классификаторов на нейронных сетях.
КРАТКИЕ ТЕОРЕТИЧЕСКИЕ СВЕДЕНИЯ
ОСНОВНЫЕ ПОЛОЖЕНИЯ.
Искусственные нейронные сети (ИНС)- этосовокупность моделей биологических нейронных сетей (НС), которые отражают основные закономерности функционирования биологических НС. Безусловно, как и всякие модели, ИНС являются существенным упрощением биологических НС. В большинстве современных ИНС не учитываются различия между нейронами, роль глии, временную динамику нейронов.
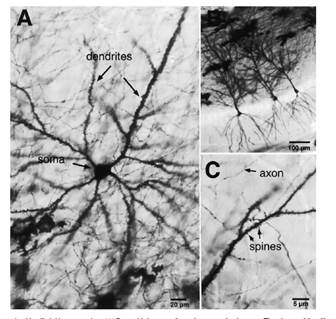 |
Биологические нейроны различаются большим разнообразием форм и функций (рис.1,2).
|
|
|
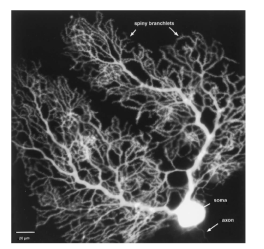 |
Рисунок 1- Пирамидальный нейрон
Рисунок 2- Нейрон Пуркинье
Искусственные, или формальные, нейроны основаны на схематическом представлении биологического нейрона (рис.3).
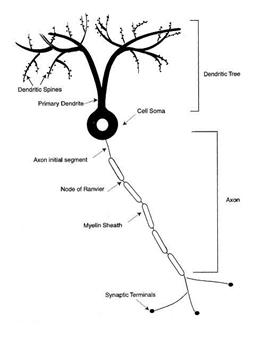
Рисунок 3- Схематическое представление нейрона
Первой моделью искусственного нейрона была модель МакКаллока- Питса (рис.4).
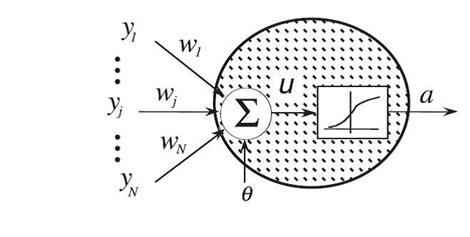
Рисунок 4- модель МакКаллока- Питса
В этой модели входные сигналы 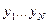 имитируют аксоны предыдущих нейронов, веса связей
имитируют аксоны предыдущих нейронов, веса связей 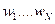 - синаптическую передачу между аксонами предыдущих нейронов и дендритами, активность сомы имитирует функция активации, а выходной сигнал
- синаптическую передачу между аксонами предыдущих нейронов и дендритами, активность сомы имитирует функция активации, а выходной сигнал 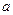 -аксон данного нейрона, с которой сигнал поступает на синапсы следующих нейронов. Формально, значение выхода нейрона получается после последовательности следующих преобразований:
-аксон данного нейрона, с которой сигнал поступает на синапсы следующих нейронов. Формально, значение выхода нейрона получается после последовательности следующих преобразований:
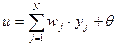 ,
,
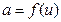 .
.
Таким образом, сигнал на выходе формального нейрона представляет собой взвешенную сумму входных данных, преобразованную с помощью функции, обычно нелинейной, 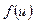 , называемой функцией активации. Принципиальным, в данном случае, является нелинейность функции преобразовании. В противном случае, выходной сигнал формального нейрона был бы эквивалентен сигналу на выходе линейного фильтра.
, называемой функцией активации. Принципиальным, в данном случае, является нелинейность функции преобразовании. В противном случае, выходной сигнал формального нейрона был бы эквивалентен сигналу на выходе линейного фильтра.
|
|
|
Выбор функции активации определяется:
- спецификой задачи;
- удобством реализации на ЭВМ, в виде электрической схемы или другим способом;
- алгоритмом обучения, а именно, некоторые алгоритмы накладывают ограничения на вид функции активации.
Вид нелинейности обычно не оказывает принципиального влияния на решение задачи, но удачный выбор может сократить время обучения в несколько раз.
На практике наиболее часто используются следующие функции активации.
1. Ступенчатая функция активации, определяемая как
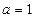 , если
, если 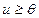 ;
; 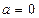 в противном случае.
в противном случае.
Ступенчатая функция активации была использована в классическом формальном нейроне МакКаллока- Питса. Основное достоинство ступенчатой функции- простота вычисления, основной недостаток- эта функция не дифференцируемая, что не позволяет использовать градиентные методы обучения.
2. Логистическая (рис.5), или сигмоидная функция определяемая как
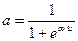 .
.
Логистическая функция наиболее часто используется в качестве функции активации.
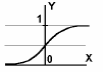
Рисунок 5- Логистическая функция активации
При уменьшении коэффициента логистическая функция становится более пологой, в пределе, при α=0, вырождаясь в горизонтальную линию на уровне 0.5. При увеличении α логистическая функция приближается по внешнему виду к функции единичного скачка. Из выражения для логистической функции, очевидно, что выходное значение нейрона лежит в диапазоне [0,1].
|
|
|
Одним из ценных свойств логистической функции является простое выражение для ее производной, что упрощает применение градиентных методов обучения.
Кроме того, она обладает свойством усиливать слабые сигналы лучше, чем большие, и предотвращает насыщение от больших сигналов, так как они соответствуют областям аргументов, где функция имеет пологий наклон.
3. Функция гиперболического тангенса (рис.6) определяемая как
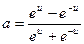 .
.
Эта функция, как и логистическая функция, используется в сетях, работающих с непрерывными сигналами. Функция симметрична относительно точки (0,0), что является ее преимуществом по сравнению с логистической функцией.
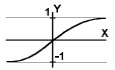
Рисунок 6- Функция гиперболического тангенса
Применяются также и другие функции активации, таки как экспонента, участки синусоиды, гауссовская функция и т.д.
АРХИТЕКТУРЫ НЕЙРОННЫХ СЕТЕЙ.
Объединение формальных нейронов в искусственные нейронные сети может проводится различным образом. По архитектуре связей искусственные нейронные сети можно сгруппировать в две большие группы: сети прямого распространения, в которых нет обратных связей и рекуррентные сети или сети с обратными связями (рис.7).
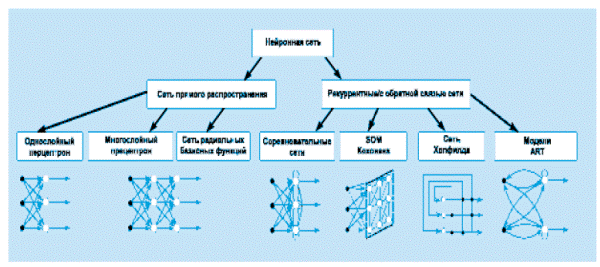
Рисунок 8- Архитектуры искусственных нейронных сетей
Каждый тип архитектуры искусственной нейронной сети оптимизирован для решения определенного класса задач.
Основными типами задач, решаемыми искусственными нейронными сетями являются:
1) Распознавание образов. В данном случае задача заключается в указании принадлежности входного образа, представленного вектором признаков, тому или иному известному классу. Практическими приложениями решения данной задачи являются, например, распознавание букв, речи, классификация электрокардиограмм, клеток крови, рентгеновских изображений и т.п.
2) Кластеризация данных (обучение без учителя). При решении этой задачи обучающая выборка отсутствует, и принадлежность образа определенному кластеру основывается на подобии вектора признаков. Кластеризация применяется для сжатия информации, извлечения знаний и исследования свойств данных.
3) Аппроксимация функций. Задача в этом случае заключается в нахождении неизвестной функции по набору экспериментальных данных.
Предсказание и прогноз.
Оптимизация.
Построение ассоциативной памяти.
Управление.
Примеры использования различных архитектур искусственных нейронных сетей приведены в таблице 1.
Таблица 1- Искусственные нейронные сети. Архитектура, обучение, решаемые задачи
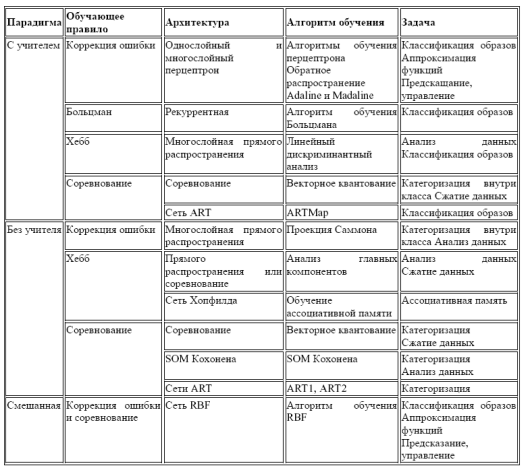
Подавляющее большинство практических приложений связано с применением многослойных перцептронов или, для краткости, просто перцептронов (название происходит от английского perception - восприятие, т.к. первый образец такого рода машин предназначался для моделирования зрения). Одной из задач решаемых многослойными перцептронами является задача распознавания образов, которыми могут быть, например, различные типы электрокардиосигналов. Рассмотрим далее особенности построения и обучения многослойных перцептронов.
МНОГОСЛОЙНЫЙ ПЕРЦЕПТРОН.
ОСНОВНЫЕ ПОЛОЖЕНИЯ.
В общем случае перцептроны решают задачу аппроксимации многомерных функций, т.е. построения многомерного отображения, обобщающего заданный набор примеров 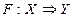 , где X- набор входных переменных, Y- выходных. В зависимости от типа выходных переменных (тип входных не имеет решающего значения), аппроксимация функций может принимать вид:
, где X- набор входных переменных, Y- выходных. В зависимости от типа выходных переменных (тип входных не имеет решающего значения), аппроксимация функций может принимать вид:
- классификации (дискретный набор выходных значений),
- регрессии(непрерывные выходные значения).
Многие практические задачи распознавания образов, фильтрации шумов, предсказания временных рядов и др. сводится к этим базовым постановкам.
Простейшим устройством распознавания образов, принадлежащим к рассматриваемому классу сетей, является одиночный нейрон, превращающий входной вектор признаков в скалярный ответ, зависящий от линейной комбинации входных переменных:
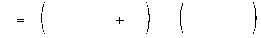 .
.
Скалярный выход нейрона можно использовать в качестве дискриминантной функции. Так, если входные векторы могут принадлежать одному из двух классов, то нейрон способен различить тип входа, например, если 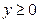 , то входной вектор принадлежит первому классу и наоборот. Такой нейрон является линейным дискриминатором. В некоторых ситуациях линейный дискриминатор - наилучший из возможных, а именно - в случае, когда вероятности принадлежности входных векторов к классу k задаются гауссовыми распределениями.
, то входной вектор принадлежит первому классу и наоборот. Такой нейрон является линейным дискриминатором. В некоторых ситуациях линейный дискриминатор - наилучший из возможных, а именно - в случае, когда вероятности принадлежности входных векторов к классу k задаются гауссовыми распределениями.
Возможности линейного дискриминатора ограничены. Он способен правильно решать лишь ограниченный круг задач - когда классы, подлежащие классификации линейно-разделимы, т.е. могут быть разделены гиперплоскостью. В d-мерном пространстве гиперплоскость может разделить произвольным образом лишь d+1 точки. Например, на плоскости можно произвольным образом разделить по двум классам три точки, но четыре - в общем случае уже невозможно (рис. 9).
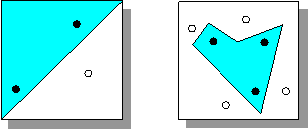
Рисунок 9- Пример линейно разделимых и линейно и линейно неразделимых классов.
Для решения таких более сложных классификационных задач необходимо усложнить сеть, вводя дополнительные (их называют скрытыми) слои нейронов, производящих промежуточную предобработку входных данных таким образом, чтобы выходной нейрон-классификатор получал на свои входы уже линейно-разделимые множества (рис.10). Причем, в принципе, всегда можно обойтись всего лишь одним скрытым слоем, содержащим достаточно большое число нейронов.
Результаты многих исследований аппроксимирующих способностей перцептронов показали:
n Сеть с одним скрытым слоем, содержащим H нейронов со ступенчатой функцией активации, способна осуществить произвольную классификацию Hd точек d-мерного пространства (т.е. классифицировать Hd примеров).
n Одного скрытого слоя нейронов с сигмоидной функцией активации достаточно для аппроксимации любой границы между классами со сколь угодно высокой точностью.
Для задач аппроксимации последний результат переформулируется следующим образом:
n Одного скрытого слоя нейронов с сигмоидной функцией активации достаточно для аппроксимации любой функции со сколь угодно высокой точностью. (Более того, такая сеть может одновременно аппроксимировать и саму функцию, и ее производные.)
Точность аппроксимации возрастает с числом нейронов скрытого слоя. При 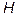 нейронах ошибка оценивается как
нейронах ошибка оценивается как 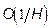 .
.
Обучение перцептрона заключается в подстройке весов 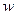 по обучающим примерам.
по обучающим примерам.
При этом возникают следующие основные вопросы:
1) С помощью каких алгоритмов производится обучение сети?
2) Какова вычислительная сложность обучения?
3) Каков оптимальный размер сети?
4) Как связан размер с числом обучающих выборок?
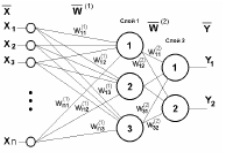
Рисунок 10- Двухслойный перцептрон
1.3.2. АЛГОРИТМ ОБУЧЕНИЯ СЕТИ. МЕТОД ОБРАТНОГО РАСПРОСТРАНЕНИЯ ОШИБКИ (back-propagation).
Суть метода заключается в следующем. Обозначим входы n-го слоя нейронов 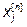 . Нейроны этого слоя вычисляют соответствующие линейные комбинации:
. Нейроны этого слоя вычисляют соответствующие линейные комбинации:

и передают их на следующий слой, пропуская через нелинейную функцию активации:
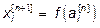 .
.
Для построения алгоритма обучения нам надо знать производную ошибки по каждому из весов сети:
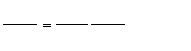
Таким образом, вклад в общую ошибку каждого веса вычисляется локально, простым умножением невязки нейрона  на значение соответствующего входа. (Из-за этого, в случае, когда веса изменяют по направлению скорейшего спуска
на значение соответствующего входа. (Из-за этого, в случае, когда веса изменяют по направлению скорейшего спуска 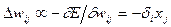 , такое правило обучения называют дельта-правилом.)
, такое правило обучения называют дельта-правилом.)
Входы каждого слоя вычисляются последовательно от первого слоя к последнему во время прямого распространения сигнала:
а невязки каждого слоя вычисляются во время обратного распространения ошибки от последнего слоя (где они определяются по выходам сети) к первому:
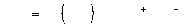 .
.
Последняя формула означает, что чем сильнее учитывается активация данного нейрона на следующем слое, тем больше его ответственность за общую ошибку.
Важность изложенного выше алгоритма back-propagation в том, что он дает чрезвычайно эффективный способ нахождения градиента функции ошибки 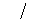 . Если обозначить общее число весов в сети как
. Если обозначить общее число весов в сети как 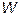 , то необходимое для вычисления градиента число операций растет пропорционально
, то необходимое для вычисления градиента число операций растет пропорционально 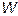 , т.е. этот алгоритм имеет сложность
, т.е. этот алгоритм имеет сложность 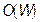 . Напротив, прямое вычисление градиента по формуле
. Напротив, прямое вычисление градиента по формуле
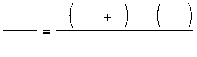
потребовала бы прямых прогонов через сеть, требующих операций каждый. Таким образом, алгоритм прямого вычисления имеет сложность 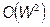 , что существенно хуже, чем у алгоритма back-propagation.
, что существенно хуже, чем у алгоритма back-propagation.
Существуют различные модификации алгоритма back-propagation о которых можно прочитать в литературе по нейронным сетям.
ОПТИМИЗАЦИЯ РАЗМЕРОВ СЕТИ
Одним из основных вопросов при проектировании нейронной сети является вопрос о выборе структуры сети: число слоев и количество нейронов в этих слоях. В данном случае решающим является выбор соотношения между числом весов и числом примеров. При конечном числе обучающих примеров всегда возможно построить нейросеть с нулевой ошибкой обучения, т.е. ошибкой, определенной на множестве обучающих примеров. Для этого нужно взять сеть с числом весов большим, чем число примеров. Действительно, чтобы воспроизвести каждый пример у нас имеется 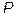 уравнений для неизвестных. И если число неизвестных меньше числа уравнений, такая система является недоопределенной и допускает бесконечно много решений. В этом-то и состоит основная проблема: у нас не хватает информации, чтобы выбрать единственное правильное решение - функцию-учителя. В итоге выбранная случайным образом функция дает плохие предсказания на новых примерах, отсутствовавших в обучающей выборке, хотя последнюю сеть воспроизвела без ошибок. Вместо того, чтобы обобщить известные примеры, сеть запомнила их. Этот эффект и называется переобучением.
уравнений для неизвестных. И если число неизвестных меньше числа уравнений, такая система является недоопределенной и допускает бесконечно много решений. В этом-то и состоит основная проблема: у нас не хватает информации, чтобы выбрать единственное правильное решение - функцию-учителя. В итоге выбранная случайным образом функция дает плохие предсказания на новых примерах, отсутствовавших в обучающей выборке, хотя последнюю сеть воспроизвела без ошибок. Вместо того, чтобы обобщить известные примеры, сеть запомнила их. Этот эффект и называется переобучением.
На самом деле, задачей обучения нейронной сети является не минимизация ошибки обучения, а минимизация ошибки обобщения, определенной для всех возможных в будущем примеров. Именно такая сеть будет обладать максимальной предсказательной способностью. И трудность здесь состоит в том, что реально наблюдаемой является именно и только ошибка обучения. Ошибку обобщения можно лишь оценить, опираясь на те или иные соображения.
Было показано, что минимум ошибки обобщения достигается при оптимальном числе весов в сети 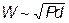 , соответствующих числу нейронов в скрытом слое равному по порядку величины
, соответствующих числу нейронов в скрытом слое равному по порядку величины 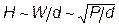 , где
, где 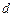 - размерность входов.
- размерность входов.
Этот результат можно использовать для получения окончательной оценки сложности обучения ( 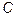 - от английского complexity)
- от английского complexity)
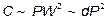
Отсюда можно сделать следующий практический вывод: нейроэмуляторам с производительностью современных персональных компьютеров ( 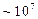 операций в секунду) вполне доступны анализ баз данных с числом примеров
операций в секунду) вполне доступны анализ баз данных с числом примеров 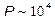 и размерностью входов
и размерностью входов  . Типичное время обучения при этом составит
. Типичное время обучения при этом составит  секунд, т.е. от десятков минут до несколько часов.
секунд, т.е. от десятков минут до несколько часов.
Другой вывод из выше приведенных качественных оценок - обязательность этапа предобработки высокоразмерных данных. Невозможно классифицировать непосредственно картинки с размерностью 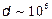 . Из оценки точности классификации следует, что это потребует числа обучающих примеров по крайней мере такого же порядка, т.е. сложность обучения будет порядка
. Из оценки точности классификации следует, что это потребует числа обучающих примеров по крайней мере такого же порядка, т.е. сложность обучения будет порядка 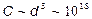 . Современным компьютерам с производительностью
. Современным компьютерам с производительностью 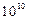 операций в секунду потребовалось бы несколько лет обучения распознаванию таких образов.
операций в секунду потребовалось бы несколько лет обучения распознаванию таких образов.
Дата добавления: 2019-02-22; просмотров: 193; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!