Программы, используемые для статистического анализа
Некоторые простейшие статистические расчеты могут быть выполнены в табличном редакторе MS Excel. Это прежде всего касается определения центральной тенденции и разброса количественных данных, коэффициента линейной корреляции Пирсона и т.п. Тем не менее, для серьезной статистической обработки Excel не приспособлен, хотя в нем удобно производить предварительную подготовку данных для анализа. Наиболее известными и часто употребляющимися программами, специализированными для выполнения статистического анализа любой сложности, являются различные версии Statistica, SPSS и SAS. Есть и менее известные программы – MedCalc, GraphPad Prism, StatGraphics, StataSE, MathCad, Maple и т.д. Некоторые из них достойны эксклюзивного применения в отдельных областях статистической обработки данных. Так, например, в MedCalc реализован лучший в индустрии модуль ROC-анализа, а GraphPad Prism ориентирован на обработку графической информации (в частности, позволяет выявлять достоверность различий графиков функций, подбирать формулы, описывающие кинетические кривые, определять МПК и т.д.).
В Республике Беларусь стандартом de facto является программа Statistica, которая представляет собой своеобразную «золотую середину» мира программ для статанализа, позволяя выполнять все его основные разновидности и в то же время отличаясь интуитивно понятным интерфейсом, не требуя знания внутреннего макроязыка программирования (как SPSS, SAS и StataSE). Наиболее распространенной в наших учебных учреждениях является взломанная версия Statistica 6.0 с частичной русификацией интерфейса. Автор не рекомендует пользоваться указанной версией программы, предпочитая ей Statistica 7.0 или 8.0 с англоязычным интерфейсом, и не потому, что осуждает пиратство (все серьезные программы для статистического анализа стоят невыносимо дорого для аспирантов и соискателей отечественных ВУЗов; сами же ВУЗы крайне редко озабочиваются покупкой лицензионных копий соответствующих программ, исповедуя принцип «и так все как-то сходит»), а потому, что перевод пунктов меню и подменю в половине случаев некорректен, работа программы нестабильна (часты зависания и «вылеты» на рабочий стол, вероятно, из-за некорректной русификации), русский язык в меню все равно исчезает, начиная с подменю второго уровня вложенности, интерфейс в ряду версий программы самый неудобный и непонятный (уже в следующей версии он был радикально переработан), и, кроме того, знание английской статистической терминологии очень полезно при чтении научных статей на языке оригинала.
|
|
|
Автор рекомендует пользоваться программами Statistica 7.0 (вчетверо меньше по размеру, чем 8.0, при аналогичной базовой функциональности, которая перекрывает 99,9% потребностей обычных соискателей и аспирантов, и общей структуре меню и подменю) и SPSS 19 (идеальна для построения красивых, запоминающихся графиков, позволяет производить какой-никакой ROC-анализ, а также имеет относительно удобный модуль корреляционного анализа). Для ROC-анализа (и только для него) оптимально использование программы MedCalc любой из последних версий.
|
|
|
Понятие о базе данных. Принципы создания и заполнения базы данных
Любой статистический анализ данных, полученных в ходе исследования, начинается с разработки и заполнения базы данных.
Собственно, база данных – совокупность информации, структурированной таким образом, чтобы сделать возможной обработку указанной информации при помощи ЭВМ.
Обычно база данных представляет собой двумерную таблицу, где по горизонтали располагаются т.н. «случаи» (cases), а по вертикали – т.н. «переменные» (variables). Каждый «случай» обычно соответствует одному пациенту, включенному в исследование, каждая «переменная» – это некая характеристика пациента, замеряемая либо иным образом учитываемая в ходе исследования (см. рис. 1).
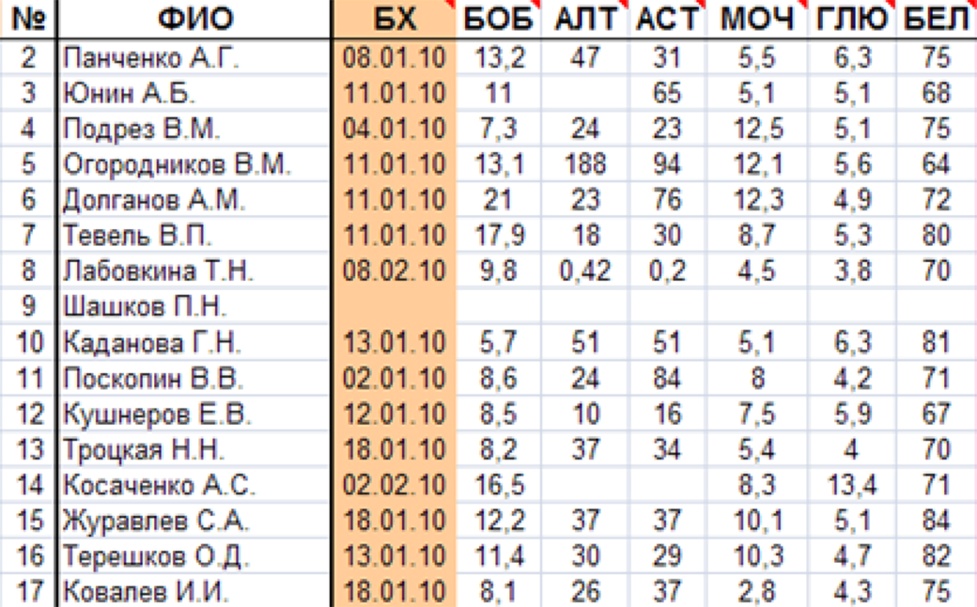
Рис. 1. Образец базы данных, оформленной в виде двумерной таблицы. Строки данной базы соответствуют отдельным пациентам (т.н. случаи), столбцы – важным параметрам, регистрируемым в ходе исследования (т.н. переменные); в представленном случае в качестве переменных выступают данные биохимического анализа крови.
|
|
|
Возможно и иное построение таблицы данных, когда столбцы соответствуют случаям, а строки – переменным, но данное построение неудобно, поскольку обычно количество учитываемых переменных существенно превышает число пациентов, включенных в исследование. Кроме того, статистические программы по умолчанию считают, что данные о переменных содержатся именно в столбцах; таким образом, описанное построение таблицы данных (случаи – по горизонтали, переменные – по вертикали) является стандартом de facto.
База данных может состоять не из одной, а из нескольких связанных таблиц. В этом случае ячейки двумерной таблицы содержат ссылки на другую таблицу (или несколько таблиц). В частности, одни и те же пациенты могут быть включены в состав нескольких таблиц (например, в случае неоднократной их госпитализации в лечебные учреждения; амбулаторный этап наблюдения пациента также может быть оформлен в виде отдельной записи). В этом случае наличие перекрестных ссылок позволяет компьютеру отыскать все данные, имеющиеся на пациента с известными паспортными данными. Ссылки на другие таблицы такого рода (их называют «связанными») обычно имеются в ячейках, однозначно идентифицирующих «случаи» (например, там, где хранится ФИО пациентов и дата их рождения).
|
|
|
Возможно также построение трехмерных таблиц, где, помимо «случаев» (Х) и «переменных» (Y), имеется еще одна координата (Z), обычно – время. Такие таблицы образуют многослойные «сэндвичи», где каждому временному отрезку соответствует свое значение учитываемых переменных для каждого пациента, включенного в исследование.
Компьютерный вариант простейшей базы данных – описанный выше двумерный массив – называется «электронная таблица». Ее создание и заполнение обычно осуществляются при помощи специальных программ – менеджеров электронных таблиц. Наиболее известной и популярной из них (фактически, отраслевым стандартом) является MS Excel всех версий – компонент пакета офисных программ MS Office. К прочим представителям семейства относятся LibreOffice Calc и OpenOffice.org Calc, входящие в состав офисных пакетов LibreOffice и OpenOffice.org, соответственно. Практика показывает, что для подавляющего большинства биомедицинских исследований достаточно базы данных в виде простого двумерного массива, который может быть легко сформирован в MS Excel. Более сложные базы данных обычно требуются для ведения отчетности (финансовой либо медицинской). Для создания и управления базами данных со связанными либо трехмерными таблицами используются т.н. СУБД – системы управления базами данных. Наиболее известная и общеупотребительная из указанных программ – MS Access, также являющаяся компонентом пакета MS Office. Из других СУБД следует отметить FoxPro, Oracle, Paradox, dBase, MySQL. СУБД удобны для автоматической генерации разнообразных отчетов, а также для оперативного структурирования информации, накапливающейся в учреждениях за длительные отрезки времени.
Имеется три типа переменных, которые крайне важно отличать друг от друга:
1. Количественные (числовые) переменные – содержат данные, обязательно выражаемые только числами, причем такие переменные могут быть «непрерывными» (когда их величина в некоторые пределах может принимать любые значения, в т.ч. дробные – рост, вес, артериальное давление и т.п.) и «дискретными» (когда их величина может быть только целочисленной – например, число половых партнеров, возраст (полных лет) и т.п.);
2. Порядковые переменные – представлены описательными (текстовыми) данными, которые могут быть условно ранжированы от наименьшего к наибольшему, что позволяет формализовать эти данные с использованием целочисленных кодов, расположенных по нарастающей; при этом интервал, разделяющий числовые значения кодов, не имеет математического смысла. Типичный пример порядковых переменных – степени тяжести любого заболевания (легкая, средней тяжести, тяжелая, крайне тяжелая, которые обычно кодируются соответственно как «1», «2», «3» и «4»). Еще один пример – уровень устойчивости микроорганизма к антибиотику ( «0» – чувствителен, «1» – умеренно чувствителен, «2» – устойчив). В ряде случаев к порядковым переменным можно относиться как к количественным и обрабатывать их с использованием тех же статистических методов. Простейший случай порядковой переменной – переменная, отражающая наличие либо отсутствие некоего состояния / признака и кодируемая двумя кодами: «0» – нет признака, и «1» – есть признак (например, переменные «инфаркт миокарда» или «пациент получал антибактериальную терапию»). Любая качественная (номинальная, категориальная) переменная, содержащая описательные данные, может быть разложена на несколько порядковых переменных подобного вида, которые, в свою очередь, могут быть подвергнуты полноценной статистической обработке;
3. Качественные (номинальные, категориальные) переменные – представлены текстовыми данными, которые не могут быть ранжированы от наименьшего к наибольшему, поскольку являются чисто описательными и совершенно не связаны между собой. Типичный пример качественной переменной – диагноз заболевания (если число изучаемых диагнозов более одного) или пол пациентов. Как указывалось ранее, качественные переменные могут быть разделены на несколько простейших порядковых, при этом число порядковых переменных равно количеству вариантов значений качественной переменной. Например, при включении в исследование пациентов с 5 различными диагнозами в базе данных естественным образом образуется качественная переменная «диагноз», имеющая 5 возможных значений. Эту переменную необходимо разбить на 5 простых порядковых. Каждая из указанных простых переменных соответствует наличию (либо отсутствию) одного из пяти анализируемых заболеваний. Существует очень ограниченное количество методов, пригодных для статистической обработки качественных переменных, не преобразованных в порядковые.
Качественные и порядковые переменные перед статистической обработкой необходимо формализовать, т.е. представить текстовые признаки в цифровой форме. При этом каждый из описательных признаков, составляющих данные переменные, кодируется определенным числом; именно это число и вносится в соответствующую ячейку таблицы. В случае порядковой переменной цифровые коды должны ранжироваться по нарастанию от наименьшего к наибольшему, причем наименьшее число соответствует отсутствию качественного признака, а наибольшее – его максимальной выраженности; численные интервалы между такими кодами («рангами») должны быть одинаковыми. Качественная же переменная до формализации подвергается разложению на несколько простых порядковых (см. выше).
Существует ряд правил построения электронных таблиц для обеспечения их максимальной совместимости с программами, выполняющими статистическую обработку:
1. Случаи располагаются в строках, переменные – в столбцах (см. выше);
2. Случаи должны быть уникальными, т.е. каждая строка таблицы должна соответствовать одному уникальному пациенту. Соответственно, каждый случай должен иметь уникальный (неповторяющийся) идентификатор (порядковый номер);
3. Заголовки столбцов должны быть уникальными (неповторяющимися), короткими (не длиннее 10-12 символов) и, желательно, набранными латиницей (допустимо употребление цифр, дефисов и знаков подчеркивания);
4. Необходимо четкое разделение всех переменных таблицы на качественные, порядковые и количественные;
5. Значения всех переменных, вносимые в таблицу, должны быть числовыми; символьные значения (вида «да», «нет» и т.п.) не допускаются. В том случае, если переменные являются качественными либо порядковыми (т.е. по природе своей требуют словесного описания), их необходимо формализовать, т.е. разработать схему цифрового кодирования описательных признаков и строго ее придерживаться по ходу заполнения базы;
6. Сложные качественные переменные, для которых число цифровых кодов превышает 2, необходимо разбивать на более простые с вариантами значений «1» (есть данное состояние) и «0» (нет данного состояния);
7. При заполнении переменных, содержащих даты, необходимо придерживаться единого формата представления данных (например, дд/мм/гггг). Аналогично, при внесении в ячейки таблицы цифровых значений необходимо следить за тем, чтобы точность указанных значений была единообразной в пределах переменной (например, количество эритроцитов должно всюду указываться с точностью до второго знака после запятой);
8. По возможности следует избегать пустых ячеек на месте отсутствующих данных; в таких случаях лучше использовать специальные коды, резко отличающиеся от всех возможных значений учитываемого признака (например, 9999);
9. После заполнения электронную таблицу обязательно необходимо проверить на предмет неправильно внесенных данных. Обычно встречающиеся при этом ошибки:
– значения пропущены либо сдвинуты;
– случайное изменение формата ячеек (например, дата или текст вместо числа);
– формат даты не соответствует оговоренному для данной базы;
– значения дат не соответствуют срокам выполнения исследования (вариант: возраст пациентов выходит за рамки, оговоренные для исследования);
– числовые данные результатов обследований явно выходят за возможные пределы колебаний соответствующих параметров;
– не соблюдена оговоренная точность указания результатов замеров (указано больше либо меньше знаков после запятой, чем необходимо);
– не все данные в качественных либо порядковых переменных формализованы (помимо числовых данных, в таблицу внесены текстовые);
– идентификаторы случаев неуникальны (повторяются);
– нарушение принятой схемы кодировки качественных либо порядковых переменных (указаны ошибочные коды).
Как правило, все подобные ошибки легко вычленяются при внимательном неоднократном осмотре электронной таблицы; возможна также автоматизированная проверка при помощи формул и специальных «проверочных» переменных.
Дата добавления: 2019-02-22; просмотров: 193; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!