КОДЫ БЧХ, ИСПРАВЛЯЮЩИЕ ДВЕ ОШИБКИ
Nbsp;
В.О. ОСИПЯН
Э Л Е М Е Н Т Ы
Т Е О Р И И П Е Р Е Д А Ч И И Н Ф О Р М А Ц И И
К Р А С Н О Д А Р 2 0 0 4

МИНИСТЕРСТВО ОБЩЕГО
И ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
РОССИЙСКОЙ ФЕДЕРАЦИИ
КУБАНСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
В . О . О С И П Я Н
Э Л Е М Е Н Т Ы
Т Е О Р И И П Е Р Е Д А Ч И И Н Ф О Р М А Ц И И
Учебное пособие
Краснодар 2 0 0 4
УДК 519.45
Элементы теории передачи информации : Учеб. пособие / В.О.Осипян;
Кубан. гос. ун-т. Краснодар, 1998. 37 с. ISBN 5-230-21822-3.
В пособии рассмотрены теоретические и практические вопросы основ теории передачи информации в целом. Адресовано студентам факультета прикладной математики специальности 010200, а также студентам других специальностей, интересующимся вопросами представления, надёжного хранения и эффективной обработки информации.
Печатается по решению редакционно-издательского совета
Кубанского государственного университета.
Рецензенты: кафедра прикладной математики (Кубанский государ- ственный технологический университет);
Н. Г. Колесников, проф. ( Кубанский государственный аграрный университет )
ISBN 5-230-21822-3 Ó Кубанский государственный
университет, 2004
ВВЕДЕНИЕ
Задача передачи, хранения и обработки информации в оптимальным заранее заданном смысле (например, для передачи информации с максимально возможной скоростью, для надёжного хранения информации, для представления информации в сжатом виде и т. д. ) в наше время при резком увеличении объёмов информации занимает особое место. Решение указанной задачи непосредственно связано с теорией передачи информации, так как хранение и обработка информации есть не что иное как передача информации во времени.
Данное учебное пособие написано на основе материалов лекций и практических занятий, которые в течение ряда лет читались автором в Кубанском государственном университете. Автор исходил из предположения, что студенты знакомы с основами дискретной математики и линейной алгебры. Дополнительные сведения из теории вероятностей можно найти в соответствующих источниках.
Пособие состоит из трёх глав. В первой главе приводится построение простых и составных полей Галуа - алфавит для дискретных логических и вычислительных устройств.
Вторая глава посвящена вопросам кодировании и передачи информации при наличии помех. Рассматриваются различные способы кодирования информации и сами коды, обнаруживающие и исправляющие канальные ошибки.
В третьей главе приводятся основные требования к представлению и передаче информации в каналах связи.
Приведённые в конце каждого параграфа задачи предназначены для понимания самого материала пособия.
АЛФАВИТ ДИСКРЕТНЫХ УСТРОЙСТВ. КОНЕЧНЫЕ ПОЛЯ
При изучении вопросов представления, хранения и переработки информации в качестве алфавита для дискретных логических и вычислительных устройств используется некоторое конечное поле или поле Галуа, которое состоит из конечного числа элементов в отличии от бесконечных полей. На практике чаще всего в качестве поля Галуа применяется поле, состоящее из двух элементов - 0 и 1.
1. 1. ПРОСТОЕ ПОЛЕ ГАЛУА GF( P )
Пусть Р простое число и * - произвольная арифметическая операция над целыми числами из Z по модулю Р. Тогда
GF( P ) = í 0 , 1 , 2 , . . . , Р - 1ý
образует поле Галуа или конечное поле порядка Р, т. е. поле состоящее из Р элементов с операциями сложения и умножения по модулю Р. Здесь Р называется характеристикой поля GF( P ).
 Если Р = 2, то мы имеем наименьшее конечное поле с двумя элементами 0 и 1: GF(2) = í 0 , 1 ý, что и чаще всего является алфавитом для реальных дискретных и логических устройств. Приведём ещё один пример конечного поля GF( 5 ) = í 0 , 1 , 2 , 3 , 4 ý с соответствующими таблицами сложения и умножения ( вычитание и деление неявно определяются этими же таблицами ): + 0 1 2 3 4 * 1 2 3 4
Если Р = 2, то мы имеем наименьшее конечное поле с двумя элементами 0 и 1: GF(2) = í 0 , 1 ý, что и чаще всего является алфавитом для реальных дискретных и логических устройств. Приведём ещё один пример конечного поля GF( 5 ) = í 0 , 1 , 2 , 3 , 4 ý с соответствующими таблицами сложения и умножения ( вычитание и деление неявно определяются этими же таблицами ): + 0 1 2 3 4 * 1 2 3 4
0 0 1 2 3 4 1 1 2 3 4
1 1 2 3 4 0 2 2 4 1 3
2 2 3 4 0 1 3 3 1 4 2
3 3 4 0 1 2 4 4 3 2 1
4 4 0 1 2 3
Очевидно, для любого отрицательного целого числа х по модулю Р имеем х = Р + х ( mod P ), причём можно считать что - х меньше Р.
Так, например, если Р = 5, * - означает умножение, то 13 * 6 = 3 и 14*6 = 4, если * - деление, а - 3 = 2 по модулю 5.
Элемент a ¹ 0 поля GF( P ) называется примитивным элементом поля, если все его ненулевые элементы могут быть представлены в виде степени элемента a. Так, например, a = 2,3 являются примитивными для поля
GF( 5 ).
Арифметика конечных полей ничем не отличается от арифметики бесконечных полей ( например R,Q) за исключением того, что все операции в конечных полях GF( Р ) выполняются по модулю Р.
1.1.1. Составить таблицы сложения и умножения для поля GF( 7 ).
1.1.2. Определить противоположные и обратные элементы поля GF( 7 ).
1.1.3. Найти все примитивные элементы полей GF( 7 ) и GF( 13 ).
1.1.4. Доказать,что каждый ненулевой элемент поля GF(Р) имеет обратный элемент.
1.1.5. Определить число примитивных элементов поля GF( Р ).
1.1.6. Доказать, что для произвольных двух элементов
а, bÎGF( Р ) имеет место равенство ( а + b) Р = а Р+ bР.
1.1.7. Доказать, что ( Р - 1 ) ! = - 1.
1.1.8. Доказать, что если f ( x ) = a 0 x n+ a 1 x n - 1 + . . . + a n ,a n ÎGF( Р ), то f ( х Р ) = ( f ( х ) ) Р .
1.1.9. Доказать, что корнями уравнения х Р - х = 0 являются все элементы поля GF( Р ).
1.1.10. Найти число N P ( a x + b ) всех линейных функций у = а х + b
в GF( Р ).
1.1.11. Найти число N P (( a x + b ) / ( с х + d)) всех дробно - линейных функций у = (а х + b ) / ( с х + d ) в GF( Р ).
1.1.12. Определить число N P ( a d - b c = k ) в GF( Р ) , где k Î GF( Р ).
1.1.13. Найти число решений N P ( х 1+ х 2+ . . . + х n= k ) уравнения
х 1+ х 2+ . . . + х n= k в GF( Р ), где k Î GF( Р ).
1.1.14. Доказать, что х Р - х =F1( х ) FР ( х ), где F1( х ) и FР ( х ) произведения всех простых над GF( Р ) полиномов степеней 1 и Р соответственно.
1.1.15. Определить число ІP(n)простых над GF( Р ) полиномов степени n. Доказать, что ІP(n)³ 1.
1.1.16. Разработать алгоритм построения простого над GF( Р ) полиномов заданной степени в явном виде.
1. 2. СОСТАВНОЕ ПОЛЕ ГАЛУА GF( Р n )
Пусть f ( x ) = x n + a 1 x n - 1 + . . . +a n - простой над полем GF( Р ) полином степени n (над каждым полем Галуа существует простой полином любой заданной степени ). Тогда
GF( Рn ) = íb0 x n - 1 + b1 x n - 2 +. . . +b n - 1 |b i Î GF( Р ) ý
образует поле Галуа или конечное поле порядка Рn, т.е. поле, состоящее из Рn элементов с операциями сложения и умножения по двойному модулю
f ( x ) и Р. Здесь Р также называется характеристикой поля GF( P ).
В данном построении поля Галуа GF( Рn ) элементы поля представлены в виде полиномов над GF( P ) степени не выше n - 1 и
x n = ( Р - a 1 ) x n - 1 + . . . + ( Р - a n ).
Так, например, если Р = 2, f ( x ) = x 3 + х + 1, то элементы поля GF(2 3 )
в полиномиальном представлении имеют вид b0x2 + b1x + b2, где b i ÎGF( 2 ) и x 3 = х + 1.



 Полиномиальное Векторное Целочисленное Степенное
Полиномиальное Векторное Целочисленное Степенное
представление представление представление представление

0 0 0 0 0 0
1 0 0 1 1 х 0
х 0 1 0 2 х 1
х + 1 0 1 1 3 х 3
х 2 1 0 0 4 х 2
х 2 + 1 1 0 1 5 х 6
х 2 + х 1 1 0 6 х 4
х 2 + х + 1 1 1 1 7 х 5
Соответствующие таблицы сложения и умножения ( вычитание и деление неявно определяются этими же таблицами ) имеют вид:
 |
+ 0 1 х х + 1 х 2 х2 + 1 х2 + х х2 + х +1
0 0 1 х х + 1 х2 х2 + 1 х2 + х х2 + х +1
1 1 0 х + 1 х х2 + 1 х2 х2 + х +1 х2 + х
х х х + 1 0 1 х2 + х х2 + х +1 х2 х2 + 1
х + 1 х + 1 х 1 0 х2+х +1 х2 + х х2+ 1 х2
х 2 х2 х2 + 1 х2 + х х2+х+1 0 1 х х +1
х 2 + 1 х2+1 х2 х2+х+1 х2+х 1 0 х+1 х
х 2 +х х2+х х2+х+1 х2 х2+1 х х+1 0 1
х2 +х +1 х2+х+1 х2+х х2+1 х2 х+1 х 1 0
 * 1 х х + 1 х 2 х2 + 1 х2 + х х2 + х +1
* 1 х х + 1 х 2 х2 + 1 х2 + х х2 + х +1
1 1 х х + 1 х 2 х2 + 1 х2 + х х2 + х +1
х х х2 х2+х х+1 1 х2+х+1 х2 +1
 х+1 х+1 х2+х х2+1 х2+х+1 х2 1 х
х+1 х+1 х2+х х2+1 х2+х+1 х2 1 х
х2 х2 х+1 х2 +х+1 х2+х х х2+1 1
 х2+1 х2+1 1 х2 х х2+х+1 х+1 х2+х
х2+1 х2+1 1 х2 х х2+х+1 х+1 х2+х
х2+х х2+х х2+х+1 1 х2+1 х+1 х х2
х2+х+1 х2+х+1 х2+1 х 1 х2+х х2 х+1
Аналогично определяется примитивный элемент поля GF( Рn ). При этом, полином, корнем которого является примитивный элемент поля
GF( Рn ), называется примитивным полиномом. Так, например, для конечного поля GF( 2 3 ) элемент х является примитивным элементом.
Пусть q = P n, где Р - простое, а n - произвольное натуральное число, тогда можно объединить приведённые два случая построения конечных полей в случай поля GF(q ).
1.2.1. Построить поле Галуа GF( 3 2).
1.2.2. Построить таблицы сложения и умножения для полей GF(8) и GF(9).
1.2.3. Доказать, что для любых двух элементов a, bÎGF( q ) и любого натурального числа m = Р k имеет место равенство:
( a ± b ) m = a m ± bm.
1.2.4. Доказать, что корнями уравнения х q - х = 0 являются все элементы поля GF( q ).
1.2.5. Определить число примитивных элементов поля GF( q ).
1.2.6. Доказать, что два поля Галуа с одним и тем же числом элементов изоморфны.
1.2.7. Доказать, что х q - х = П F i ( x ), где F i ( x ) - произведение всех
i |n
простых над GF( Р ) полиномов степени i.
1.2.8. Доказать, что над каждым полем GF( q ) существует примитивный полином любой положительной степени.
2. КОДИРОВАНИЕ ИНФОРМАЦИИ
Информация в широком смысле означает сведения, данные, сообщение, известие и т.д. Как правило, информацию можно представить в виде последовательностей символов или знаков некоторого алфавита. Это так называемый алфавит источника информации. Рассмотрим основные принципы кодирования информации для передачи, хранения и обработки в каналах связи.
2. 1. ОСНОВНЫЕ ПОНЯТИЯ. ПРИМЕРЫ КОДОВ
При кодировании информации, то есть при переходе от одного способа представления информации к другому, последовательности из символов источника по некоторому правилу отображаются в последовательности символов канала связи. Таким образом, кодом называется правило, описывающее однозначное соответствие (кодирование) символов алфавита источника символам (или словам) алфавита канала связи (помимо основного значения слова ”code”- ”кодекс”, ”свод законов”, начиная с середины XIX в. оно означало книгу, в которой словам естественного языка сопоставлены группы цифр или букв).
Пусть А = {a1,a2,...,am}, B={0,1,2,..,p-1}, p ³ 2 алфавиты источника сообщений и канала связи (в частности p=2) соответственно.Тогда общую схему передачи дискретной информации (СПДИ) можно представить в виде:
шум
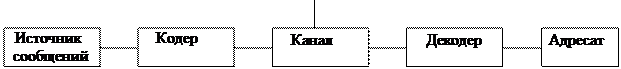 |
u=u1u2 ...uk x=x1x2...xn x'= x1'x2 '... xl ' u=u1u2 ...uk
Здесь u=u1u2 ...uk - так называемое информационное слово, ukÎA, x=x1x2...xn- кодовое слово, xnÎB, x '= x1'x2 '... xl ' - искажённое слово под воздействия шума (для простоты изложения предполагаем, что xl1 Î B, хотя на практике возможно случай когда xl1 Ï B, для конкретного или для всех l. Кодовое слово х иначе называют сигналом (изменение некоторой физической величины во времени, обеспечивающее передачу информации, называется сигналом, например, для радио сигналами являются электромагнитные колебания). В дальнейшем множество всех кодовых слов также назовём кодом.
Кодирование назовём побуквенным или блочным, если каждой букве или соответственно каждому блоку из А ставится в соответствие некоторое слово из букв В.
Основная задача теории кодирования заключается в оптимальном в некотором заранее заданном смысле (например, для защиты информации, для сжатия информации, для передачи информации с максимально возможной скоростью, для надёжного хранения информации и т.д.) передаче, хранении и обработки информации.
Кодирование называется р-ичным кодированием, если | В | = р. В данном разделе рассматриваются лишь двоичные кодирования, т.е. р=2,
В=í 0,1 ý. Приведём некоторые примеры.
1. Пусть А=í0 , 1 , 2 , 3 , . . .ý, В=í 0,1 ý. Рассмотрим кодирование С множества натуральных чисел, при котором числу i = 0 ставится в соответствие кодовое слово х = 0, а числу i ³ 1 - такое кодовое слово
х = х1 х2 . . . хm, хm Îí 0,1 ý, х1 = 1,
что m
å х j 2 m - j = k . ( 1 )
j = 1
Так, например, числу i = 13соответствует кодовое слово х = 1101 длины m = 4.
Очевидно, данное кодирование С представляет собой перевод натуральных чисел в двоичную систему счисления и является примером неравномерного кодирования, так как кодовые слова имеют разные длины.
2. Рассмотрим пример равномерного кодирования С k первых 2 k натуральных чисел.
Числу i=0 сопоставим кодовое слово у = 00...0 длины k, а каждому числу i ³ 1 - кодовое слово у = 0 k - m х 1 . . . х m, где х 1 , . . . , х m определяются соотношением ( 1 ).
Так, например, при k = 6 ( 0 £ i<2 6 ) числу i =13 сопоставляется кодовое слово х=001101.
Данное кодирование С k представляет собой перевод натуральных чисел в двоичную систему счисления с помощью k цифр и является примером равномерного кодирования, так как кодовые слова имеют равные длины.
3. Код С 0 с проверкой на четность.
Каждому информационному слову u=u1 u 2 ...u k , u kÎ í 0,1 ý сопоставим кодовое слово x=x 1 x 2 . . . x n , n = k +1, для которого
 x n = x 1 + x 2 + . . . + x k , x i=u i , i = 1 , n ,
x n = x 1 + x 2 + . . . + x k , x i=u i , i = 1 , n ,
где + - сложение по модулю 2.
Так, например, при n=3 имеем следующие кодовые слова С 0, все слова которого содержат чётное число единиц:

 u 1 u 2 u 3 x 1 x 2 x 3 x 4
u 1 u 2 u 3 x 1 x 2 x 3 x 4
0 0 0 0 0 0 0
0 0 1 0 0 1 1
0 1 0 0 1 0 1
0 1 1 0 1 1 0
1 0 0 1 0 0 1
1 0 1 1 0 1 0
1 1 0 1 1 0 0
1 1 1 1 1 1 1
4. Код С 1 с повторениями.
При данном способе кодирования сообщений информационный символ u i повторяется n раз ( обычно n нечётно ).
Так, например, если u iÎ í0,1ý, то код С 1 состоит всего лишь из двух кодовых слов длины n:
С 1 = í 0 0 . . . 0 , 1 1 . . . 1ý.
5. Код Wn Варшамова.
Пусть В = í 0 , 1 , . . . , р - 1ý - алфавит канала, a - произвольное целое число, n - длина кодового слова х = х1х2 . . .х n , х nÎ В.
Множество Wn всех слов х = х1х2 . . .х n , для которых выполняется сравнение
n
W = å i x i º a( mod n + 1),
i = 1
образует код Варшамова, т.е. n
Wn = í х1х2 . . .х n | W = å i x i º a( mod n + 1), х nÎ В ,a ÎZ ý.
i = 1
Так, в частности, при р =3, n = 4, a = 0 из указанного сравнения получаем код W4 , состоящих из 17 следующих кодовых слов:
0 0 0 0 1 1 1 1 0 2 1 2
1 0 0 1 2 1 2 0 0 2 2 0
0 1 1 0 0 0 2 1 2 2 2 2
1 2 0 0 2 0 0 2 2 1 1 2
2 0 1 0 0 1 0 2 1 2 2 1
2 2 0 1 1 0 2 2
Код W4 является 3 -ичным равномерным нелинейным кодом.
6. Код М Морзе.
Для кода М алфавитом А сообщений служат буквы немецкого алфавита и десятичные цифры, а алфавитом канала является В = í . , _ , L ý, где L - пустой символ . Код М является примером побуквенного кодирования.
Так, например, букве А соответствует кодовое слово . _ , а цифре 6 - слово _ . . . . . и т.д. Код М также является неравномерным кодом. Если установить дополнительное соответствие
 . 0 1,
. 0 1,
 _ 0 1 1,
_ 0 1 1,
L 0 0 0 ,
то код М можно рассматривать как двоичный неравномерный код.
Из приведённых выше примеров следует, что С k , С 0 , С 1 ,Wn являются равномерными кодами, а С и М - неравномерными. Все они, кроме Wn, двоичные коды.
В процессе хранения ( передачи информации во времени ), передачи и обработки информации могут возникнуть ошибки ( искажение сигналов в каналах под воздействием шума ), и для того, чтобы уменьшить или исключить канальные ошибки вовсе, необходимо представить информацию в таком виде (т.е. выбрать подходящий способ кодирования ), чтобы она была устойчивой к различным канальным ошибкам. Коды, которые противостоят против канальных ошибок, называются помехоустойчивыми кодами.
Рассмотрим основные виды преобразований кодовых слов ( сигналов ), называемых канальными ошибками.
І . Симметричные ошибки. Это такие ошибки, при которых вероятности изменения каждого канального символа равны между собой. Тогда соответствующий канал называется симметричным каналом. Примером такого канала является двоичный симметричный канал ( ДСК ):
0 1 - р 0



р р
 1 1 - р 1
1 1 - р 1



 Здесь с вероятностьюр ( 0 £ р £ 0.5) двоичный символ 0 переходит в двоичный символ 1:í 0 1ý, а символ 1 - в 0:í1 0 ý.Ошибки указанного типа í 0 1 , 1 0 ý иначе называют аддитивными ошибками или ошибками типа замещения.
Здесь с вероятностьюр ( 0 £ р £ 0.5) двоичный символ 0 переходит в двоичный символ 1:í 0 1ý, а символ 1 - в 0:í1 0 ý.Ошибки указанного типа í 0 1 , 1 0 ý иначе называют аддитивными ошибками или ошибками типа замещения.

 Симметричные ошибки типов выпадения ( или стирания ) и вставки имеют соответственно вид:í0 L , 1 Lý , íL 0 , L 1ý , где L - пустой символ.
Симметричные ошибки типов выпадения ( или стирания ) и вставки имеют соответственно вид:í0 L , 1 Lý , íL 0 , L 1ý , где L - пустой символ.
ІІ . Асимметричные ошибки. Это такие ошибки при которых вероятности изменения разных канальных символов не равны между собой. Тогда соответствующий канал называется асимметричным каналом.
 Так, например, при асимметричной ошибке типа í 1 0 ý происходит замена 1 на 0 с некоторой вероятностьюр, но не наоборот. Такие ошибки возникают в результате размыканий в канале, ибо при размыкании сигнал может лишь исчезнуть.
Так, например, при асимметричной ошибке типа í 1 0 ý происходит замена 1 на 0 с некоторой вероятностьюр, но не наоборот. Такие ошибки возникают в результате размыканий в канале, ибо при размыкании сигнал может лишь исчезнуть.
Аналогично можно рассматривать асимметричные ошибки видов:
 í 0 1ý , í1 0 ý , í0 L ý , í1 Lý , íL 0 ý , íL 1ý.
í 0 1ý , í1 0 ý , í0 L ý , í1 Lý , íL 0 ý , íL 1ý.
ІІІ . Арифметические ошибки вида + 2i ( -2i ). Это такие ошибки, при которых числовое значение искажённого сигнала на 2i больше ( соответственно меньше ) числового значения самого сигнала. Такие ошибки могут возникнуть при выполнении арифметических и логических операций, выполняемых в ЭВМ.
Таким образом, необходимо на основании характеристик канала выбрать такой способ кодирования, чтобы вероятность искажения передаваемого сообщения была бы меньше наперёд заданной величины.
2.1.1. Построить соответствующие 3-ичные коды, аналогично кодам С и С k . _
2.1.2. Построить код С 0 с проверкой на нечётность длины n.
2.1.3. Построить р - ичный код С 1 с повторениями длины n.
2.1.4. Построить двоичный код Варшамова W5.
2.1.5. Построить 3 - ичный код Морзе.
2.1.6. Разработать алгоритмы декодирования кодов С , С k и W n.
2.1.7. Определить мощность двоичного кода Варшамова W n.
2. 2. ЛИНЕЙНЫЕ КОДЫ. СПОСОБЫ ИХ ЗАДАНИЯ
Пусть q = Р n и GF( q ) - конечное поле в векторном представлении его элементов, а
GF n ( q ) = í х 1 х 2 . . . х n | х n ÎGF( P ) ý
- множество всех вектoров х = х 1 х 2 . . .х n длины n. Если х = х 1 х 2 . . .х n ,
у = у 1 у 2 . . . у n ÎGF n (q), a Î GF( P ), то
х + у = ( х 1 + у 1 )( х 2 + у 2 ) . . . (х n + у n )
и
a х = a х 1 a х 2 . . . a х n
- сумма двух векторов ( слов ) и умножение на скаляр a соответственно ( здесь и далее все операции производятся по модулю Р ).
Расстоянием Хэмминга d ( х , у ) между двумя векторами х = х 1 х 2. . .х n
и у = у1 у2 . . . уn назовём число позиций, в которых они различаются.
Весом Хэмминга W ( х ) вектора х = х 1 х 2 . . .х n назовём число ненулевых компонент х n .
Так, например, d ( 1 1 0 1 , 0 1 1 0 ) = 3 , W ( 1 1 1 0 ) = 3.
Очевидно, что d ( х , у ) = W ( х - у ) и d ( х , у ) удовлетворяет следующим условиям:
1. d ( х , у ) ³ причём d ( х , у ) = 0 при х = у;
2. d ( х , у ) = d ( у , х );
3. d ( х , у ) £ d ( х , z ) + d ( z , у ).
Таким образом, GF n ( q ) представляет собой метрическое пространство с метрикой d ( х , у ) Хэмминга.

 Рассмотрим наиболее важные в практическом отношении случаи векторного пространства GF n ( 2 ) и двоичного симметричного канала. Последнее означает, что ошибки в ДСК могут быть лишь типа í 0 1 , 1 0ý.
Рассмотрим наиболее важные в практическом отношении случаи векторного пространства GF n ( 2 ) и двоичного симметричного канала. Последнее означает, что ошибки в ДСК могут быть лишь типа í 0 1 , 1 0ý.
Линейным [ n , k ] - кодом С [ n , k ] назовём подпространство размерности k пространства GF n ( 2 ). Другими словами, линейный [ n , k ] - код представляет собой множество векторов длины n над GF (2), называемыми кодовыми словами, такое, что сумма двух произвольных кодовых слов также является кодовым словом, и произведение любого кодового слова на элемент поля GF (2) тоже является кодовым словом. Очевидно, в любом линейном коде нулевое слово 0 = 0 0 . . . 0 есть кодовое слово.
Так, например, если n = 3, то
С [ 3 , 2 ] = í 0 0 0 , 0 1 1 , 1 0 1 , 1 1 0ý
- подпространство размерности 2 пространства
GF 3( 2 ) = í 0 0 0 , 0 0 1 , 0 1 0 ,0 1 1 , 1 0 0 , 1 0 1 , 1 1 0 , 1 1 1 ý ,
следовательно, С [ 3 , 2 ] линейный [ 3 , 2 ] - код. В самом деле С [ 3 , 2 ] образует пространство :

 ___+ 0 0 0 0 1 1 1 0 1 1 1 0
___+ 0 0 0 0 1 1 1 0 1 1 1 0
0 0 0 0 0 0 0 1 1 1 0 1 1 1 0
0 1 1 0 1 1 0 0 0 1 1 0 1 0 1
1 0 1 1 0 1 1 1 0 0 0 0 0 1 1
1 1 0 1 1 0 1 0 1 0 1 1 0 0 0 .
Теперь рассмотрим ещё один способ задания линейного кода.
Пусть u=u1u2 ...uk - информационное слово, т.е. слово, которому соответствует один символ из алфавита А - источника передачи информации, x=x1x2...xn - соответствующее переданное по ДСК кодовое слово ( или сигнал ), n ³ k , х ' = х 1х 2 . . . х i '. . . х j'. . . х n - принятое, в общем случае искажённое в позициях i, . . ., j слово.
Слово e = х - х ' = х + х ' = е 1е 2 . . . е n - есть так называемое шумовое слово, для которого
ì 0 , если в i - й позиции нет ошибки;
е i = í
î 1 , если в i - й позиции есть ошибка.
Итак, если е = 0 0 . . . 0, то х ' = х , т.е. переданное слово принято без ошибок, а при е ¹ 0 0 . . . 0 принятое слово х ' = х + е содержит ошибку. Таким образом, шум - это всего лишь некоторый двоичный вектор и такая трактовка вопроса передачи информации достаточно упрощает математическое описание обнаружения и исправления канальных ошибок в системах связи.
Для линейного способа кодирования информации применяется следующее общее правило: если u=u1u2 ...uk - информационное слово, то для кодового слова x=x1 x2 ... xn считается, что
 хi = u i , х k + i = f i ( х 1 х 2 . . . х k ) , i = 1 , n - k , ( 2 )
хi = u i , х k + i = f i ( х 1 х 2 . . . х k ) , i = 1 , n - k , ( 2 )
 где f i ( х 1 х 2 . . . х k ) , i = 1 , n - k - некоторые линейные функции. Соотношения (2) называются проверочными соотношениями.
где f i ( х 1 х 2 . . . х k ) , i = 1 , n - k - некоторые линейные функции. Соотношения (2) называются проверочными соотношениями.
Числоr = n - k называется числом проверочных, или избыточных, или же контрольных символов, а сами символы х k + 1 , . . . , х n- проверочными, или избыточными, или же контрольными символами. Таким образом, для построения линейных помехоустойчивых кодов приходится внести r дополнительных символов в кодовые слова и тем самым уменьшить скорость передачи информации R =k / n , где k - число информационных символов, n - длина кодового слова.
 Пусть
Пусть
f i ( х 1 х 2 . . . х к ) = h i 1* x 1 + h i 2* x 2+ . . . + h i k* x k , i = 1 , r ,
где h i k ÎGF( 2 ).Тогда из проверочных соотношений ( 2 ) имеем :
h i 1* x 1 + h i 2* x 2+ . . . + h i k* x k + x k + i = 0 , i = 1 , r . ( 3 )
Матрица H = ( h i j )rn размерности ( r xn) из коэффициентов (3 ) - так называемая проверочная матрица и имеет вид:


 h 1 1 h1 2 . . . h 1 k 1 0 . . . 0 0
h 1 1 h1 2 . . . h 1 k 1 0 . . . 0 0
h 2 1 h 2 2 . . . h 2 k 0 1 . . . 0 0
H = . . . = ( A | E r ),
h r 1 h r 2 . . . h r k 0 0 . . . 0 1
где A- двоичная матрица размерности (r ´ k), а E r - единичная матрица размерности ( r ´ r). Её применяют на практике для декодирования информации.
Линейным [ n , k ] - кодом с проверочной матрицей H назовём множество всех двоичных слов x=x 1 x 2 . . . x n таких, что H х т = 0 т.е.
С [ n , k ] = í х | H х т = 0 ý .
Итак, мы имеем более простой способ задания линейного С [ n , k ] кода с помощью проверочной матрицы. Данный способ задания линейного кода зависит только от проверочной матрицы.
Так, например, пусть при n = 6 , к = 3 и r = 3
х 4 = х 1 + х 2 , х 1 + х 2 + х 4 = 0 ,
х 5 = х 1 + х 3 , или х 1 + х 3 + х 5 = 0 ,
х 6 = х 2 + х 3 , х 2 + х 3 + х 6 = 0 .
Тогда проверочная матрица H линейного [ 6 , 3 ] - кода С[ 6 , 3 ] имеет вид:


 1 1 0 1 0 0
1 1 0 1 0 0
H = 1 0 1 0 1 0 ,
0 1 1 0 0 1
а все его кодовые слова можно найти из указанных выше проверочных соотношений следующим образом в виде кодовой книги:


 u1 u2 u3 х1 х2 х3 х4 х5 х6
u1 u2 u3 х1 х2 х3 х4 х5 х6
0 0 0 0 0 0 0 0 0
0 0 1 0 0 1 0 1 1
0 1 0 0 1 0 1 0 1
0 1 1 0 1 1 1 1 0
1 0 0 1 0 0 1 1 0
1 0 1 1 0 1 1 0 1
1 1 0 1 1 0 0 1 1
1 1 1 1 1 1 0 0 0
или как С[ 6 , 3 ] = í х | H х т = 0 ý .
Таким образом,
С[ 6 , 3 ] =í000000,001011,010101,011110,100110,101101,110011,111000 ý.
Очевидно, если некоторое слово х = х1х2х3 х4х5х6 Î С[ 6 , 3 ] , то H х т = 0,
в противном случае H х т ¹ 0.
Рассмотрим ещё один способ задания линейного кода - с помощью порождающей матрицы.
Пусть С линейный [ n , k ] - код, т.е. подпространство размерности k
пространства GF n ( 2 ). Тогда в этом подпространстве С существует базис b 1 ,b 2 , . . . b k , с помощью которого можно получить все кодовые слова линейного кода С.
Матрица G размерности ( k ´ n), строками которой являются базисные векторы b 1 ,b 2 , . . . b k, называется порождающей матрицей линейного кода С. Говорят также, что код С представляет собой пространство строк порождающей матрицы G.
Другими словами, если u=u1u2 ...uk - информационное слово, то х = u G - кодовое слово.
Можно доказать,что если проверочная матрица H линейного [ n , k ]- кода С имеет вид ( A | E r ), то порождающая матрица этого же кода представляется в виде G = (E к | - А кт ) ( в двоичном случае - А = А ).
Так, например, для линейного кода С[ 6 , 3 ] порождающая матрица G имеет вид :

 1 0 0 1 1 0
1 0 0 1 1 0
G= 0 1 0 1 0 1 ,
0 0 1 0 1 1
а базисные векторы - b 1 = 1 0 0 1 1 0 , b 2 = 0 1 0 1 0 1, b 3 = 0 0 1 0 1 1.
Для определения кодового слова соответствующему, например, информационному слову u = 1 0 0 , имеем:

 1 0 0 1 1 0
1 0 0 1 1 0
х= u G = ( 1 0 0 ) 0 1 0 1 0 1 = 1 0 0 1 10 ,
0 0 1 0 1 1
что в самом деле принадлежит коду С[ 6 , 3 ] .
Таким образом, мы описали ещё один способ задания линейного [n, k ]- кода с помощью порождающей матрицы, что применяется на практике при кодировании информации линейными кодами.
2.2.1. Пусть х = х 1х 2 . . .х n , у = у 1 у 2 . . . у n ÎGF(2 n ). Установить связь между расстояниями Хэмминга d Х ( х , у ) и Евклида d Е ( х , у ) .
2.2.2. Доказать, что для расстояния Хэмминга выполняется неравентво треугольника d ( х , у ) £ d ( х , z ) + d ( z , у ).
2.2.3. Найти все подпространства пространства GF3 (2 ).
2.2.4. Доказать, что H х' т = 0 тогда и только тогда, когда шумовое слово равно нулю.
2.2.5. Построить пример нелинейного кодирования.
2.2.6. Для фиксированной длины n определить наименьшее число избыточных символов.
2.2.7. Определить скорости передачи информации для кодов: С , С 0, С1, Сk , С[ 6 , 3 ] , М , W n .
2.2.8. Как иначе можно задать проверочную матрицу H ?
2.2.9. Построить все линейные коды длины не более семи .
2.2.10. Построить проверочную матрицу кодов С 0, С 1.
2.2.11. Доказать, что если H = ( A | E r ) , то G = (E к | - А кт ).
2.2.12. Найти все базисы линейного С[ 6 , 3 ] - кода.
2.2.13. Построить троичный линейный код длины 13.
2.2.14. Доказать, что G H т = 0 .
2.2.15. Построить проверочную и порождающую матрицы для линейно- го [ n , n - 1] - кода.
2.2.16. Доказать, что d ( х , у ) = d ( х + z , у + z ) = W ( х + у ).
2.2.17. Пусть W ( х ) = W ( у ) = w . Доказать, что d ( х , у ) - чётное число .
2.2.18. Для векторов х и у определим их произведение:
х * у = х 1 у 1 , х 2 у 2 , . . . , х n у n .
Показать, что тогда W ( х + у ) = W ( х ) + W ( у ) - 2 W ( х * у ) .
2.2.19. Разработать алгоритм декодирования линейных блочных кодов.
2. 3. СВОЙСТВА ЛИНЕЙНОГО КОДА. КОДЫ ХЭММИНГА
Пусть С линейный [ n , k ] - код с проверочной матрицей H размерности
( n - k ) ´ n . Если все строки матрицы H линейно независимы , то число кодовых слов ( т .е . мощность кода ) равно ½ В ½k , где В - алфавит канала. Далее, если х , у Î С и aÎ В , то х + у , a х также принадлежат линейному коду С, так как
H ( х + у )т = H хт + H ут = 0 , H (aх )т = a Hхт = 0 .
Обозначим через d С минимальное расстояние линейного кода С, т.е.
d С = min í d ( х , у ) ½ х , у Î С , х ¹ у ý .
Линейный код С длины n, размерности k и с минимальным расстоянием d С ( или же с кодовым расстоянием d С = d ) назовём также линейным
[ n , k , d ] - кодом.
Рассмотрим простой способ нахождения минимального расстояния линейного двоичного кода, а именно, кодовое расстояние линейного двоичного кода равно минимальному весу ненулевых кодовых слов, т.е.
d С = min í W ( х ) ½ х Î С , х ¹ 0 ý ,
так как
d С = min í d ( х , у )½х , у Î С , х ¹ у ý = min í W ( х + у )½ х , у Î С, х¹у ý=
= min í W (z )½ z Î С, z ¹0 ý .
Код с кодовым расстоянием d может исправлять [(d - 1 ) / 2 ] ошибок. Если d чётное, то код может одновременно исправлять (d - 1 ) / 2 ошибок и обнаруживать d / 2 ошибок. Таким образом, для построения оптимальных кодов необходимо учитывать его эффективность, т.е. скорость передачи информации и максимальность кодового расстояния для заданных параметров n и k.
Так, например, для кода С 0 с проверкой на чётность R = k / ( k + 1 ), а d С = 2 , т.е. его скорость высокая, а корректирующая возможность очень низкая, он обнаруживает всего лишь одну ошибку. И наоборот, для кода С1 с повторениями R = 1 / n , а d С = n , т.е. он достаточно высокой корректирующей возможностью, но с низкой скоростью.
Для построения линейного [ n , k , d ] - кода длины n размерности k с заданным расстоянием d и с проверочной матрицей H необходимо и достаточно, чтобы любые d - 1 столбцов матрицы H были линейно независимы и в то же время нашлись бы d линейно зависимых столбцов. Причём, если С - [ n , k , d ] - код, то n - k ³ d - 1 , т.е. d £ n - k + 1 ( Граница Синглтона ) и указанные выше свойства справедливы для линейных кодов над любым конечным полем.
А для обнаружения и исправления ошибок в каналах связи необходимо воспользоваться равенством:
S = H x ' т = å e i H i = H a + H b + . . . + H c ,
i
где H i - i - й столбец матрицы H , i - номер ошибочной позиции принятого слова x ' , так как если x ' = х + e , то S = H x ' т = H ( x + e ) т = H e т.
Слово S т называется синдромом принятого слова x '.
Теперь рассмотрим класс двоичных линейных кодов , которые обнаруживают и исправляют одну симметрическую ошибку.
Двоичный код Хэмминга H r. Для любого r ³ 2 двоичный код Хэмминга H r длины n = 2 r - 1 имеет проверочную матрицу H r , столбцы которой состоят из всех ненулевых двоичных векторов длины r, причём каждый вектор встречается в матрице H один раз, т.е.
 0 0 . . . 1 1
0 0 . . . 1 1
0 0 . . . 1 1
 H r = . . . = 1 , 2 , . . . , 2 r - 1 .
H r = . . . = 1 , 2 , . . . , 2 r - 1 .
0 1 . . . 1 1
1 0 . . . 0 1
Кодовое расстояние кода H r равно 3 , так как любые два столбца её проверочной матрицы H r линейно независимы, и существуют 3 линейно зависимых столбца, следовательно, код Хэмминга обнаруживает и исправляет одну симметрическую ошибку. Данный код представляет собой линейный [2 r - 1 , 2 r - r - 1 , 3 ] - код.
В случае, когда длина кода Хэмминга не равна 2 r - 1 , то r определяется как наименьшее целое решения неравенства
n < 2 r - 1 ,
а проверочная матрица H r' соответствующего кода Хэмминга длины n<2 r-1
получается из проверочной матрицы H r путём исключения любых её 2 r-1- - n столбцов.
Так, например, двоичный [7 , 4 , 3 ] - код Хэмминга имеет следующую проверочную матрицу:
 0 0 0 1 1 1 1
0 0 0 1 1 1 1
H 3 = 0 1 1 0 0 1 1 = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ,
1 0 1 0 1 0 1
а [6 , 3 , 3 ] - код - матрицу ( из H 3 исключим, например, последний столбец ):
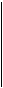 0 0 0 1 1 1
0 0 0 1 1 1
H 3' = 0 1 1 0 0 1 = [ 1 , 2 , 3 , 4 , 5 , 6 ] .
1 0 1 0 1 0
Приведём способ построения новых кодов из заданных на примере кодов Хэмминга и кодов проверки на чётность в результате чего кодовое расстояние и длина нового кода увеличиваются на единицу. Это так называемый расширенный [n + 1 , n - r , 4 ] - код Хэмминга с проверочной матрицей:
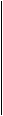
 1 1 . . . 1
1 1 . . . 1
0
H r + 1 = .
H r . .
.
0
Два кода называются эквивалентными, если они отличаются только перестановкой символов в кодовых словах. Так, например, коды
А 1= í0 0 0 0, 0 0 1 1, 1 1 0 0, 1 1 1 1ý , А 2= í0 0 0 0, 0 1 0 1, 1 0 1 0, 1 1 1 1ý
являются эквивалентными [ 4 , 2 , 2 ] - кодами.
Если В(n , d) - максимальная мощность некоторого линейного [n, k, d ]-
- кода длины n с кодовым расстоянием d, то для кодов Хэмминга она определяется формулой 2 r - r - 1
В(n , 3 ) = 2 ,
а его эффективность, т.е. его скорость передачи информации - формулой:
R = (2 r - r - 1 ) / (2 r - 1) .
2.3.1. Доказать, что код с кодовым расстоянием d может исправлять
[(d - 1 ) / 2 ] ошибок, причём если d чётное, то он может одновременно исправлять (d - 1 ) / 2 ошибок и обнаруживать d / 2 ошибок.
2.3.2. Доказать, что если H - проверочная матрица линейного кода длины n , то код имеет минимальное расстояние d тогда и только тогда, когда любые d - 1 столбцов матрицы H линейно независимы, но найдутся d линейно зависимых столбцов.
2.3.3. Доказать, что если i , j , . . . , k - номера ошибочных позиций принятого слова x ' некоторого линейного кода с проверочной матрицей H, то S = H x '= H i + H j + . . . + H k , где H i - i- й столбец матрицы H.
2.3.4. Доказать, что кодовое расстояние кодов Хэмминга равно 3 .
2.3.5. Доказать, что кодовое расстояние расширенных кодов Хэмминга равно 4 .
2.3.6. Выписать все кодовые слова кода H 3 .
2.3.7. Построить проверочную матрицу [13 , 10 , 3 ] - кода Хэмминга над полем GF( 3 ).
2.3.8. Доказать, что если С - двоичный линейный код и слово а Ï С , то
С U ( а + С ) также является двоичным линейным кодом.
2.3.9. Доказать, что если С является [n , k , d ]- кодом над полем GF( Р ),
то множество всех слов GFn ( Р ) можно разбить на непересекающиеся смежные классы : GF n ( Р ) = С U ( а 1 + С ) U ( а 2 + С ) U . . . U ( а t + С ) , где t = P n - k - 1 .
2.3.10. Доказать, что коды С и а + С являются эквивалентными для любого слова а.
2.3.11. Построить порождающую матрицу кода H r и, используя её, показать, что каждое ненулевое кодовое слово имеет вес не менее 3 .
2.3.12. Доказать, что код Хэмминга является совершенным кодом ( код называется совершенным, если он покрывает всё пространство ).
2.3.13. Доказать, что если С - [n , k , d ]- код , то d £ n - k + 1 ( Граница Синглтона ).
2.3.14. Определить значение величины В( n , d ) для любого линейного кода.
2.3.15. Разработать алгоритмы кодирования и декодирования для линейных [n , k , d ]- кодов.
2.3.16. Разработать алгоритмы кодирования и декодирования для линейных кодов Хэмминга.
2.3.17. Доказать, что код Хэмминга обнаруживает и исправляет одну симметрическую ошибку на примере H 3.
2.3.18. Определить веса всех кодовых слов (спектр весов) кода H r .
2. 4. ЦИКЛИЧЕСКИЕ КОДЫ
Важнейшим частным случаем линейных кодов являются циклические коды, которые допускают простую техническую реализацию и могут быть использованы для изучения, поиска и построения других не менее эффективных в практическом отношение кодов.
Линейный код С называется циклическим, если любой циклический сдвиг кодового слова также является кодовым словом , т.е. если с0с1. . . сn -1
принадлежит С, то и сn -1с0 . . . сn -2 принадлежит С.
Для описания циклических кодов сопоставим каждому кодовому слову с0с1. . . сn -1 Î GF n ( P ) полином степени n -1 :
с ( х ) = с 0 + с1 х + . . . + сn -1 х n -1 .
Тогда сумме двух кодовых слов будет соответствовать полином, представляющий сумму соответствующих им поиномов ( все вычисления здесь и ниже по модулю Р ). Причём сумма полиномов равна полиному, соответствующему некоторому кодовому слову. Однако произведение полиномов, каждый из которых имеет степень не больше n - 1, в общем случае не соответствует кодовому слову длины n, так как его степень может быть больше n - 1.
Так, например, код
С =í0 0 0 , 0 1 1 , 1 0 1 , 1 1 0ý
является циклическим кодом длины 3 и его кодовым словам соответствуют полиномы:
0 , х + х 2 , 1 + х 2 , 1 + х .
Сумме кодовых слов 1 0 1 и 1 1 0 соответствует слово 0 1 1 , которому соответствует полином с ( х ) = х + х 2 , а произведению этих же слов не соответствует кодовое слово. Поэтому нам необходимо такое представление произведения полиномов, а именно по модулю полинома х n - 1, при котором результату будет соответствовать также полином степени не больше
n - 1.
В самом деле, если кодовому слову с 0с1. . . сn -1 соответствует полином
с ( х ) = с 0 + с1 х + . . . + сn -1 х n -1,
то циклическому сдвигу сn -1с0 . . . сn -2 будет соответствовать полином
х с ( х ) = с 0х + с1 х 2 + . . . + сn -1 х n = с n -1 + с 0 х + с1 х 2+ . . .
+ сn -2 х n -1+ сn -1 ( х n -1) = сn -1 + с 0 х + . . . + с n -2 х n -1
по модулю х n -1 .
Таким образом, умножению полинома с ( х ) на х соответствует циклическому сдвигу кодового слова.
Приведём практический способ построения циклического кода с помощью так называемого порождающего полинома.
Пусть
g ( x ) = g0 + g1 x + . . . + gr xr
некоторый делитель полинома х n - 1 степени r ³ 1 - порождающий полином циклического кода длины n. Рассмотрим множество всех полиномов f(x) степени не выше n - 1 которые делятся на g( x ), т.е. множество полиномов с ( х ) = f ( x ) g ( x ). Каждому такому полиному
с ( x ) = с 0 + с1 х + . . . + сn -1 х n -1
сопоставим слово его коэффициентов с0с1. . . сn-1 и обозначим через С множество всех таких слов.
Покажем, что С является циклическим кодом длины n размерности n - r с порождающим полиномом g ( x ), причём сообщение f ( x ) кодируется словом с ( х ) = f ( x ) g ( x ).
Пусть с0с1. . . сn - 1 и d0d1 . . . dn - 1 - два произвольных слова из С, которым соответствуют полиномы
с 1( x ) = с 0 + с1 х + . . . + сn -1 х n -1 = f 1( x ) g ( x )
и
с 2( х ) = d0 + d1 х + . . . + dn - 1 х n -1 = f 2( x ) g ( x ) .
Тогда полином
с 1( x )+с 2( х ) = ( с 0+d0 ) + ( с1+d1 )х + . . . + ( сn -1+dn - 1 )х n -1=
= g ( x ) (f 1( x )+f 2 ( x )),
которому соответствует слово (с0+d0) (с1+d1). . .(сn -1+dn - 1), также делится на g(x) и, следовательно,( с0+d0 )( с1+d1). . .( сn -1+dn-1) принадлежит С, т.е. С - линейный код.
Далее, если с0с1. . . сn - 1 Î С, то его циклический сдвиг сn -1с0 . . . сn -2 также принадлежит С, в чём легко убедиться.
Так, например, полином g ( x ) = 1 + х + х 3 над GF(2) порождает циклический код длины 7 с минимальным расстоянием 3, что представляет собой двоичный [7 , 4 , 3 ] - код Хэмминга.
Если
g ( x ) = g0 + g1 x + . . . + gr xr
 порождающий полином циклического кода С, то матрица
порождающий полином циклического кода С, то матрица


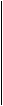 g0 g1 . . . gr 0 . . . 0 g(x) 0 . . . 0
g0 g1 . . . gr 0 . . . 0 g(x) 0 . . . 0
0 g0 g1 . . . gr 0 . . . 0 0 хg(x) 0 . . . 0
G = . . . = . . .
0 . . .0 g0 g1 . . . gr 0 . . . 0хn - r - 1 g(x)
представляет собой порождающую матрицу циклического кода С, так как С - пространство строк матрицы G.
С другой стороны, для декодирования циклического кода С, определим проверочный полином и проверочную матрицу соответственно как:
h( x ) = (x n - 1) / g( x ) = h 0 + h 1x + . . . + h kx k , h k ¹ 0 , h kÎ GF(P) ,



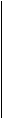
 0 0 . . . 0 h k . . . h 2 h 1 h 0 0 0. . .0 h(x)
0 0 . . . 0 h k . . . h 2 h 1 h 0 0 0. . .0 h(x)
H = 0 h k . . . h 2 h 1 h 0 0 0 хh(x) 0
. . . = . . .
h k . . . h 2 h 1 h 0 0 0 . . . 0 х n - k - 1 h(x) 0 0 . . .0
Таким образом, мы имеем основные способы задания циклических кодов.
Ранее рассмотренные коды Хэмминга H r в самом деле суть циклические коды с порождающими полиномами g ( x ) равными примитивным полиномам полей Галуа. А для определения всех порождающих полиномов, в общем случае, необходимо иметь разложение полинома x n - 1 на простые множители над полем Галуа, что является особым вопросом исследования. Так, например,если
x n - 1 = g 1( x ) g 2( x ) . . . g m( x ),
над GF(q), то можно получить 2m различных порождающих полиномов
g( x ) и столько же циклических кодов.
2.4.1. Найти все делители полинома х 7 - 1 над GF(2).
2.4.2. Нормированный полином М( х ) с коэффициентами из GF(Р) наименьшей степени, для которого Мa(a) = 0 , a Î GF(q) называется минимальным полиномом элемента a. Доказать, что:
а ) Мa( х ) неприводим над GF(Р);
б ) степень минимального полинома примитивного элемента поля
GF(q) равна n ( такой полином называется примитивным );
в ) Мa( х ) = Мaр ( х ).
2.4.3. Найти все примитивные полиномы заданной степени поля GF(Р).
2.4.4. Определить порождающий полином циклического[ 15 , 11 , 3 ]- кода Хэмминга H 4.
2.4.5. Разработать алгоритмы кодирования и декодирования циклических кодов.
2.4.6. Доказать, что если h ( x ) делится на хТ - 1, то минимальное расстояние не может быть больше чем n / Т.
2.4.7. Код С называется реверсивным, если для произвольного слова
с0с1. . . сn -1 Î С следует, что сn -1 . . .с1с0 Î С. Доказать, что циклический код реверсивен тогда и только тогда, когда все элементы, обратные корням его порождающего полинома, также являются корнями порождающего полинома.
2.4.8. Доказать, если - 1 равна некоторой степени q по модулю n, то каждый циклический код над GF(q) длины n реверсивен.
2.4.9. Доказать, что x n - 1 имеет n различных корней над GF(q).
2.4.10. Циклотомический класс С s по модулю n над GF(q) определяется как множество:
С s = { s , sq ,sq2, . . . , sqms - 1 } ,
где sqms º s (mod n ) , ( q , n ) = 1. Доказать, что
х n - 1 = П М s ( х ) ,
s
где s пробегает всё множество представителей по модулю n.
2.4.11. Определить проверочный полином для кода Хэмминга H 3 .
2.4.12. Доказать, что код Хэмминга H r является циклическим кодом с порождающим полиномом g (x)=Мa (х), где a- примитивный элемент поля GF(q).
2.4.13. Построить наименьший циклический код, содержащее слово
0 0 1 1 0 1 0.
2.4.14. Разработать алгоритм разложения полинома х n - 1 над GF(q).
2.4.15.Определить минимальное расстояние циклического кода длины n.
КОДЫ БЧХ, ИСПРАВЛЯЮЩИЕ ДВЕ ОШИБКИ
Рассмотримкласс двоичных циклических кодов, которые обнаруживают и исправляют любые t - кратные ошибки. Это так называемые коды Боуза-Чоудхури-Хоквингема ( или, кратко, коды БЧХ ).
Здесь опишем обобщение кодов Хэмминга, позволяющее исправлять две ошибки с помощью проверочной матрицы Hr кода Хэмминга Hr .
Пусть n = 2 r - 1 - длина кода Хэмминга, r - число проверочных символов кодовых слов Hr ,
Hr = [ 1 , 2 , 3 ,..., 2 r - 1]
- проверочная матрица размерности ( r ´ 2 r - 1 ) кода Hr.
Построим проверочную матрицу Hr' обобщённого кода Хэмминга, исправляющего две ошибки, путём добавления ещё r строк к проверочной матрице Hr кода Хэмминга следующим образом:

 1 2 3 . . . 2 r - 1
1 2 3 . . . 2 r - 1
Hr' = f(1) f(2) f(3) . . . f(2 r - 1) ,
где f(i) - некоторая функция, отображающая r - мерные вектора в r - мерные вектора.
Допустим, что произошли две ошибки - на позициях i и j. Нам необходимо выбрать функцию f(i) так, чтобы декодер по синдрому S принятого слова x' мог найти i и j.


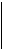
 Так как i + j к 1
Так как i + j к 1
S = H'x'T = Hi' + H'j = f(i) + f(j) = к 2 ,
то для обнаружения двух ошибок необходимо декодеру решить систему уравнений:
ì i + j = к 1 ,
í
î f(i) + f(j) = к 2 .
Можно проверить, что при выборе функции f(i) = i3 система имеет ровно два решения i и j.
В самом деле при f(i) = i 3 имеем: ì i + j = k 1 ,
í
î i3 + j3 = k 2 ,
откуда при к 1 ¹ 0 находим, что
ì i + j = k 1 ,
í
î i * j = k21 + к 2 / к 1 ,
т.е. i и j являются корнями уравнения
Z 2 + k 1 Z + k21 + к 2 / к 1 = 0.
Таким образом, проверочная матрица Hr' искомого кода принимает вид:

 1 2 3 . . . 2 r - 1
1 2 3 . . . 2 r - 1
Hr' = 1 3 2 3 3 3 . . . (2 r - 1) 3 ,
а его параметры - n = 2 r - 1 , k = n - 2 r , d = 5.
Заметим, что для операций над r - мерными векторами удобно интерпретировать каждый двоичный вектор как некоторый двоичный полином степени не больше r - 1, а сами операции выполнять над соответствующими полиномами по модулю неприводимого над GF(2) полинома М(х) степени r. Тогда результат любой операции будет полином степени не выше r - 1, и которому будет соответствовать r - мерный вектор.
В частности, при r = 3, М( х ) = х 3 + х + 1 двоичный код БЧХ длины 7, исправляющий две ошибки, имеет проверочную матрицу:
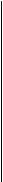
 0 0 0 1 1 1 1
0 0 0 1 1 1 1
0 1 1 0 0 1 1
1 0 1 0 1 0 1
Hr' = 0 0 1 1 1 1 0
0 1 0 0 1 1 1
1 1 0 1 0 1 0
Здесь
a 0 a 1 a 2 a 0х 2 + a 1х + a 2 ,
т.е. каждому 3 -мерному вектору сопоставлен полином 3-й степени и все операции выполнены по модулю М( х ) = х 3 + х + 1 в поле GF(2).
На практике для построения проверочной матрицы Hr' кода БЧХ необходимо воспользоваться степенными представлениями элементов полей Галуа. Так, например, проверочной матрице H3 кода H3 соответствует матрица
H3 = [ 1 a a 2 a 3 a 4 a 5 a 6 ] ,
а проверочной матрице H3' кода БЧХ -
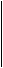
 1 a a 2 a 3 a 4 a 5 a 6
1 a a 2 a 3 a 4 a 5 a 6
H3' = ,
1 a3 a 6 a 2 a 5 a a 4
где a Î GF(2 3) - корень уравнения a 3 + a + 1 = 0.
В общем случае можно доказать, что таким образом построенный код
БЧХ является циклическим кодом с порождающим полиномом
g ( x ) = М a ( х ) М a 3 ( х ) ,
где М a ( х ) и М a 3( х ) - минимальные полиномы элементов a и a 3 соответственно.
2.5.1. Найти степенные представления элементов поля GF(2 4) и построить соответствующую проверочную матрицу кода БЧХ.
2.5.2. Определить все примитивные полиномы поля GF(2 4).
2.5.3. Разработать алгоритм декодирования кодов БЧХ.
2.5.4. Доказать, что коды БЧХ являются циклическими кодами.
2.5.5. Доказать, что код БЧХ с порождающим полиномом
g ( x ) = М a ( х ) М a 3( х ) имеет кодовое расстояние равное 5.
2.5.6. Найти все корни полинома g ( x ) = М a ( х ) М a 3( х ).
2.5.7. Построить троичный код БЧХ, исправляющий две ошибки.
2.5.8. Построить двоичный код БЧХ, исправляющий более двух ошибок.
2.5.9. Определить кодовое расстояние циклического кода по порождающему полиному g ( x ).
2.5.10. Пусть g (x) имеет d корней a , a2 , . . . , ad - 1. Установить связь между d и минимальным расстоянием кода БЧХ с порождающим полиномом g ( x ).
2. 6. НЕЛИНЕЙНЫЕ КОДЫ. КОДЫ АДАМАРА
Для каждого линейного кода С и произвольных двух его кодовых слов х , у сумма х + у также кодовое слово, что не всегда выполняется для нелинейных кодов, хотя в большинстве случаев нелинейные коды более эффективные , чем соответствующие линейные коды .
Назовём ( n , M , d ) - кодом множество из М слов длины n ( в алфавите GF(q), в частности здесь рассмотрим алфавит GF(2) ) такое, что для любых двух слов х ¹ у d(х , у) ³ d и d является наибольшим числом с таким свойством.
Из данного определения следует, что двоичный линейный [ n , k ,d ] - код является ( n , 2 k, d ) - кодом ( круглые скобки используются для кода, который может быть или не быть линейным ).
Будем говорить, что два ( n , M , d ) - кода эквивалентны, если один может быть получен из другого перестановкой n символов и добавлением фиксированного слова.
Скорость передачи для нелинейного кода определяется как
R = log q M / n ,
что сводится к равенству
R = к / n ,
если код линеен.
Многие нелинейные коды строятся с помощью матриц Адамара. Это матрица H n размерности n ´ n из элементов ± 1, такая, что
H n HТn = n Е ,
где Е -единичная матрица размерности n ´ n . Другими словами, скалярное произведение произвольных двух различных строк H n в поле действительных чисел равно нулю. Так, например,

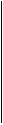 1 1 1 1
1 1 1 1
1 -1 1 -1
H 4 = 1 1 -1 -1 .
1 -1 -1 1
Матрица Адамара H n называется нормализованной матрицей, если её первый столбец и первая строка состоят из одних единиц ( как в матрице H 4). Если существует матрица Адамара H n порядка n, то n равно 1 или 2 или делится на 4 (наименьший порядок, для которого матрица Адамара ещё не построена равен 268 на 1977 г.).
Для построения матриц Адамара можно воспользоваться следующим способом. Пусть H n и H m - две матрицы Адамара порядков n и m соответственно. Тогда существует матрица Адамара H nm порядка nm, для чего необходимо каждый элемент матрицы H n заменить матрицей H m , умноженная на этот элемент. Так, например, из матрицы

 1 1
1 1
H2 = 1 -1
можно получить матрицу H 4 , а из H 4 - матрицу Адамара H 8 :
 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
1 -1 1 -1 1 -1 1 -1
1 1 -1 -1 1 1 -1 -1
1 -1 -1 1 1 -1 -1 1
H 8 = 1 1 1 1 -1 -1 -1 -1 .
1 -1 1 -1 -1 1 -1 1
1 1 -1 -1 -1 -1 1 1
1 -1 -1 1 -1 1 1 -1
Эти матрицы Адамара называются матрицами Сильвестра.
Назовём две матрицы Адамара эквивалентными, если одна может быть получена из другой перестановками строк и столбцов и умножением строк и столбцов на - 1.
Теперь перейдём к рассмотрению кодов Адамара.
Пусть H n - нормализованная матрица Адамара порядка n. Если все элементы +1 заменить на 0, а элементы - 1 заменить на 1, то H n превратится в двоичную матрицу Адамара Аn. Так как строки H n ортогональны, то любые две строки матрицы Аn совпадают в n / 2 позициях и различаются в n / 2 позициях, и поэтому расстояние Хэмминга между ними равно n / 2.
Матрица Аn позволяет построить следующие три кода Адамара:
I. ( n - 1, n , n / 2 ) - код Аn, состоящий из строк матрицы А n с выкинутым первым столбцом ( этот столбец состоит из одних нулей ).
Так, например, при n = 4 имеем:
А 4 = í0 0 0 , 1 0 1 , 0 1 1 , 1 1 0 ý.
II. ( n - 1 , 2 n , n / 2 ) - код В4 , состоящий из слов кода А n и их дополнений.
При n = 4 имеем:
В4 = í 000 , 101 , 011 , 110 , 111 , 010 , 100 , 001 ý.
III. ( n , 2- n , n / 2 ) код С n , состоящий из строк матрицы А n и их дополнений.
При n = 4 имеем:
С4 = í0000, 0101, 0011, 0110, 1111, 1010, 1100, 1001 ý.
В частности, если n = 2 r, то все три кода Адамара А n , Вn и Сn являются линейными. В остальных случаях, коды получаемые из матриц Адамара Н n (n ¹2r), чаще всего являются нелинейными.
2.6.1. Доказать, что если n порядок матрицы Адамара, n ¹ 1 , 2, то n делится на 4.
2.6.2. Пусть u 1,u 2, . . . , u n , n = 2m, обозначают различные двоичные m- векторы. Доказать, что H n= ( h i j ) , где h i j = ( - 1 )Ui Uj является матрицей Адамара.
2.6.3. Построить коды Адамара А 8 , В8 и С8 .
2.6.4. Установить корректирующие возможности кодов А n , Вn и Сn .
2.6.5. Определить скорости кодов А n , Вn и Сn .
2.6.6. Построить матрицу Адамара порядка n = Pm + 1, где Р - простое число.
2.6.7. Построить матрицы Адамара порядков 92, 116 и 172.
2.6.8. Построить коды Адамара для n = 92, 116 и 172.
2.6.9. Построить новые оптимальные коды на основе кодов Адамара
путём их склеивания.
2.6.10. Построить матрицу Адамара порядка 12n и соответствующие коды Адамара.
2.6.11. Определить, при каких n коды Адамара нелинейны.
2. 7. ГРАНИЦЫ МОЩНОСТИ КОДОВ
Задача определения точного числа кодовых слов с заданными параметрами весьма сложная. Поэтому для определения оптимальности того или иного кода на практике необходимо получить соответствующие оценки относительно мощности кодов.
Рассмотрим основные нижние и верхние границы относительно мощности двоичных кодов, т.е. когда алфавит канальных символов представляет собой поле Галуа GF( 2 ).
Итак, пусть С некоторый двоичный ( n , M , d ) - код, т.е. код длины n, мощности M и с минимальным расстоянием d. Обозначим через В ( n , d ) и M ( n , d ) максимальные мощности линейного и нелинейного (или линейного ) кодов соответственно длины n с минимальным расстоянием d. Эти величины фактически определяют скорость передачи информации с помощью данного кода и его корректирующие возможности.
Код С назовём оптимальным, если он имеет максимальную мощность среди всех кодов с той же корректирующей способностью и с теми же параметрами.
В общем случае имеет место неравенство
В ( n , d ) £ M ( n , d ) £ 2 n ,
т.е. оптимальные коды необходимо искать среди нелинейных кодов, где меньше всего порядка, в отличие от линейных кодов.
Так, например, код с проверкой на чётность С0 длины n имеет мощность В ( n , 2 ) = 2 n - 1 и является оптимальным.
В силу того, что
M ( n , 2 t ) = M ( n - 1 , 2 t - 1 ) ,
мы в дальнейшем рассмотрим лишь коды с минимальным нечётным расстоянием d = 2 t + 1.
I. Граница сферической упаковки ( граница Хэмминга ). Если существует двоичный код длины n, исправляющий t ошибок и содержащий
M ( n , 2 t + 1) кодовых слов, то должно выполняться неравенство
t
M ( n , 2 t + 1) £ 2 n / å C ni .
i = 0
В самом деле, если х 1 , х 2 , . . . , х M ( n , 2 t + 1) - все кодовые слова оптимального кода, для которых d ( x i , x j ) ³ 2 t + 1 , i ¹j, то сферы радиуса t с центрами в кодовых словах не пересекаются ( сферой радиуса t с центром х i называется множество всех слов х таких, что d ( x , х i ) £ t ). Так как объём Vn t одной сферы равен Vn t = 1 + C n1 + . . . + C nt , то
M ( n , 2 t + 1) Vn t £ 2 n ,
откуда и следует граница Хэмминга:
t
M ( n , 2 t + 1) £ 2 n / å C ni .
i = 0
Для кодов Хэмминга имеем t = 1, следовательно,
В ( n , 3 ) £ 2 n / ( n + 1 ).
Если же n = 2 r - 1, то имеет место равенство:
В ( n , 3 ) = 2 n / ( n + 1 ),
т.е. код Хэмминга длины n = 2 r - 1 также является оптимальным.
Код, мощность которого достигается границе Хэмминга, называется совершенным кодом или же плотно упакованным кодом.
В этом смысле код Хэмминга является совершенным кодом при n =2 r - 1. В общем случае для существования совершенного кода длины n, с кодовым расстоянием d = 2 t + 1 необходимо выполнение равенства
1 + C n1 + . . . + C nt = 2 r ,
где r - некоторое натуральное число. Так, например, при n = 23 имеем:
1 + C123 + С223 + C323 = 211 ,
т.е. t = 3, что соответствует совершенному коду G23 Голея [ 23 , 12 , 7 ], исправляющего три или менее число ошибок.
II. Граница Гильберта. Имеет место неравенство
t
M ( n , 2 t + 1) ³ 2 n / å C ni .
i = 0
Построим код с кодовым расстоянием d = 2 t + 1. Пусть х 1 - произвольное первое кодовое слово из GFn (2). Далее к коду добавим новое слово х 2, лежащее вне шара радиуса 2 t с центром в х 1. На следующем шаге в качестве очередного нового кодового слова выберем х 3, не принадлежащее шарам радиуса 2 t, описанным вокруг х 1 и х 2 соответственно. Процедура завершается после того, когда уже выбраны х 1 , х 2 , . . . , х S слов и имеет место неравенство
S Vn2 t ³ 2 n ,
или
S ³ 2 n / Vn2 t ,
где Vn2 t - объём шара радиуса 2 t. Но мощность оптимального кода не меньше мощности таким образом построенного кода, следовательно,
t
M ( n , 2 t + 1) ³ 2 n / å C ni ,
i = 0
что и соответствует нижней границе Гильберта.
Так, например, для кода Хэмминга длины n = 2 r - 1, имеем
В ( n , 3 ) ³ 2 n + 1 / ( n 2 + n + 2 ).
III. Граница Варшамова-Гильберта. Если выполняется неравенство
1 + C n - 11 + . . . + C n - 1d - 2 < 2 r ,
то существует двоичный линейный код длины n с минимальным расстоянием по крайней мере d, имеющий не более чем r проверочных символов.
Идея получения этой границы сводится к построению проверочной матрицы H размерности ( r´n ) , любые d - 1 столбцов которой линейно независимы.
IV. Граница Плоткина. Для любого ( n , M , d ) - кода С при n < 2 d справедливо неравенство
М( n , d ) £ 2 [ d / (2d - n) ].
Доказательство этой границы предоставляется читателю.
V. Граница Джонсона. Если M( n , d , w ) мощность оптимального равновесного кода длины n, с минимальным расстоянием d и веса w, то имеет место неравенство
М( n , 2d , w ) £ [ dn / (w 2 - wn + dn)]
при условии , что знаменатель положителен (код называется равновесным веса w, если все его слова имеют один и тот же вес w ).
2.7.1. Доказать, что М( n , d ) £ t /d +1, где t - общее число единиц кода.
2.7.2. Пусть s и t число нулевых и единичных разрядов соответственно для кодов С и С +1. Доказать, что
a ) (s - n) / (n - d) + 1 £ M(n , d) £ t / d + 1;
b ) (t - n) / (n - d) + 1 £ M(n , d) £ s / d + 1.
2.7.3. Доказать, что n - 1
а ) M(n , d) £ n å C kn - 1 / d + 1;
k = d - 1
n
b ) M(n , d) £ n å C kn - 1 / d + 1.
k = d
2.7.4. Доказать, что код С0 является оптимальным.
2.7.5. Упаковать все слова [ 7 , 4 , 3] - кода в пространстве GF7(2).
2.7.6. Определить число кодовых слов веса 3 кода Hr.
2.7.7. Определить число кодовых слов веса 4 расширенного кода Hr+1.
2.7.9. Доказать границу Варшамова - Гильберта для поля GF(q):
d - 2
å (q - 1) C in - 1 < q r .
i = 0
2.7.10. При каких n и t число M ( n , 2 t + 1) есть степень двойки.
2.7.11.Оптимальны ли коды (10, 38, 4), (11, 72, 4), (12, 144, 4) ?
Дата добавления: 2019-02-13; просмотров: 666; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!