Лекция № 6. Анализ данных. Управление данными
Цель: дать самое общее представление о понятиях корреляции, регрессии, а также познакомиться с описательной статистикой.
План:
1. Основы анализа данных.
2. Методы сбора, классификации и прогнозирования. Деревья решений. Обработка больших объёмов данных.
3. Методы и стадии Data Mining. Задачи Data Mining. Визуализация данных.
Основы анализа данных.
В этой лекции мы рассмотрим некоторые аспекты статистического анализа данных, в частности, описательную статистику, корреляционный и регрессионный анализы. Цель данной лекции - дать самое общее представление о понятиях корреляции, регрессии, а также познакомиться с описательной статистикой. Примеры, рассмотренные в лекции, намеренно упрощены.
Существует большое разнообразие прикладных пакетов, реализующих широкий спектр статистических методов, их также называют универсальными пакетами или инструментальными наборами. В Microsoft Excel также реализован широкий арсенал методов математической статистики, реализация примеров данной лекции продемонстрирована именно на этом программном обеспечении.
Описательная статистика
Описательная статистика (Descriptive statistics ) - техника сбора и суммирования количественных данных, которая используется для превращения массы цифровых данных в форму, удобную для восприятия и обсуждения.
Цель описательной статистики - обобщить первичные результаты, полученные в результате наблюдений и экспериментов.
|
|
|
Корреляционный анализ
Корреляционный анализ применяется для количественной оценки взаимосвязи двух наборов данных, представленных в безразмерном виде. Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине. Коэффициент корреляции, всегда обозначаемый латинской буквой r, используется для определения наличия взаимосвязи между двумя свойствами.
Связь между признаками (по шкале Чеддока) может быть сильной, средней и слабой. Тесноту связи определяют по величине коэффициента корреляции, который может принимать значения от -1 до +1 включительно. Критерии оценки тесноты связи показаны на таб 7.
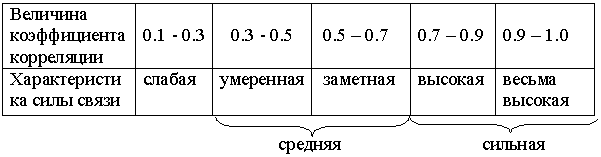
Таблица7- Количественные критерии оценки тесноты связи
Коэффициент корреляции Пирсона
Коэффициент корреляции Пирсона r, который является безразмерным индексом в интервале от -1,0 до 1,0 включительно, отражает степень линейной зависимости между двумя множествами данных.
Показатель тесноты связи между двумя признаками определяется по формуле линейного коэффициента корреляции:
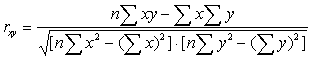
где x - значение факторного признака;
y - значение результативного признака;
n - число пар данных.
Парная корреляция - это связь между двумя признаками: результативным и факторным или двумя факторными.
|
|
|
Варианты связи, характеризующие наличие или отсутствие линейной связи между признаками:
· большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) - наличие прямой линейной связи;
· малые значения одного набора связаны с большими значениями другого (отрицательная корреляция) - наличие отрицательной линейной связи;
· данные двух диапазонов никак не связаны (нулевая корреляция) - отсутствие линейной связи.
В качестве примера возьмем набор данных А (таблица 8.1). Необходимо определить наличие линейной связи между признаками x и y.
Для графического представления связи двух переменных использована система координат с осями, соответствующими переменным x и y. Построенный график, называемый диаграммой рассеивания, показан на рис. 8.2. Данная диаграмма показывает, что низкие значения переменной x соответствуют низким значениям переменной y, высокие значения переменной x соответствуют высоким значениям переменной y. Этот пример демонстрирует наличие явной связи.
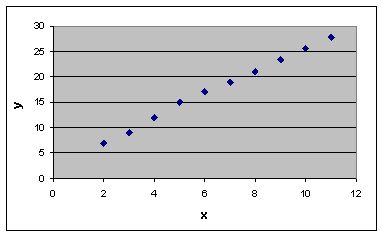
Рисунок 4- Диаграмма рассеивания
Таким образом, мы можем установить зависимость между переменными x и y. Рассчитаем коэффициент корреляции Пирсона между двумя массивами (x и y) при помощи функции MS Excel ПИРСОН (массив1;массив2). В результате получаем значение коэффициент корреляции равный 0,998364, т.е. связь между переменными x и y является весьма высокой. Используя пакет анализа MS Excel и инструмент анализа "Корреляция", можем построить корреляционную матрицу.
|
|
|
Любая зависимость между переменными обладает двумя важными свойствами: величиной и надежностью. Чем сильнее зависимость между двумя переменными, тем больше величина зависимости и тем легче предсказать значение одной переменной по значению другой переменной. Величину зависимости легче измерить, чем надежность.
Надежность зависимости не менее важна, чем ее величина. Это свойство связано с представительностью исследуемой выборки. Надежность зависимости характеризует, насколько вероятно, что эта зависимость будет снова найдена на других данных.
С ростом величины зависимости переменных ее надежность обычно возрастает.
Регрессионный анализ
Основная особенность регрессионного анализа: при его помощи можно получить конкретные сведения о том, какую форму и характер имеет зависимость между исследуемыми переменными.
Дата добавления: 2019-02-12; просмотров: 1162; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!