Method://host.domain/path/filename
где method- одно из значений, перечисленных ниже:
· http - файл на World Wide Web сервере;
· news - группа новостей телеконференции Usenet;
· telnet - выход на ресурсы сети Telnet;
· ftp – файл на FTP – сервере.
host.domain – доменное имя сервера в сети Интернет;
path –путь к файлу на сервере;
filename –имя файла.
Пример: http://support.vrn.ru/archive/index.html
См. далее https://lektsii.org/8-96077.html
Поисковые информационные технологии. Организация поиска информации.
Принципы работы поисковой системы рассмотрим на примере информации от фирмы Google.
Как информация упорядочена в Google Поиске
Чтобы пользователи могли быстро найти нужные сведения, наши роботы собирают информацию на сотнях миллиардов страниц и упорядочивают ее в поисковом индексе.
Основы Google Поиска
При очередном сканировании наряду со списком веб-адресов, полученных во время предыдущего сканирования, используются файлы Sitemap, которые предоставляются владельцами сайтов. По мере посещения сайтов робот переходит по указанным на них ссылкам на другие страницы. Особое внимание он уделяет новым и измененным сайтам, а также неработающим ссылкам. Он самостоятельно определяет, какие сайты сканировать, как часто это нужно делать и какое количество страниц следует выбрать на каждом из них.
Владельцы сайтов могут при помощи инструментов для веб-мастеров указывать, как именно следует сканировать их ресурс, в частности, предоставлять подробные инструкции по обработке страниц, запрашивать их повторное сканирование, а также запрещать сканирование, используя файл robots.txt. Google не увеличивает частоту сканирования отдельных ресурсов за плату. Владельцам всех сайтов доступны одинаковые инструменты, позволяющие обеспечить высокое качество результатов поиска по их страницам.
|
|
|
Поиск информации с помощью сканирования
Интернет похож на библиотеку, которая содержит миллиарды изданий и постоянно пополняется, но не располагает централизованной системой учета книг. Чтобы находить общедоступные страницы, мы используем специальное программное обеспечение, называемое поисковыми роботами. Роботы анализируют страницы, а также переходят по ссылкам на них так же, как это делают пользователи. После этого они отправляют сведения об обработанных ресурсах на серверы Google.
Систематизация информации с помощью индексирования
Во время сканирования наши системы обрабатывают материалы страниц так же, как это делают браузеры, и регистрируют данные по ключевым словам и новизне контента, а затем создают на их основе поисковый индекс.
Поисковой индекс Google содержит сотни миллиардов страниц. Его объем – больше 100 млн ГБ. Он напоминает страницу с оглавлением книги, так как в нем есть отдельная запись по каждому слову на всех проиндексированных страницах. Во время индексирования данные по странице добавляются в записи по всем словам, которые она содержит.
|
|
|
Построение Сети Знаний — более современный способ определить интересы пользователей по сравнению с сопоставлением ключевых слов. Для этого мы упорядочиваем не только данные по страницам, но и другие типы информации. В настоящее время Google Поиск позволяет найти нужный фрагмент текста в миллионах книг из крупнейших библиотек, узнать расписание общественного транспорта, а также изучить данные общедоступных источников, таких как сайт Всемирного банка.
Принципы работы алгоритмов Google Поиска
Чтобы пользователи за доли секунды получали не бесконечные списки адресов, а актуальные и релевантные результаты, системы ранжирования Google упорядочивают сотни миллиардов страниц в поисковом индексе.
Эти системы ранжирования состоят из наборов алгоритмов, которые, благодаря постоянной оптимизации Google Поиска, всё более точно определяют, что интересует пользователей и какие результаты следует показать.
Ряд способов, позволяющих возвращать пользователям подходящие сведения при помощи алгоритмов Google Поиска см.:
|
|
|
https://www.google.com/search/howsearchworks/algorithms/
Поиск информации в Интернете
Для поиска информации в обычно используются три способа (См. Рис.1). Первый из них - поиск по адресу. Он применяется, когда пользователю известен адрес информационного ресурса, содержащего необходимую ему информацию. При организации поиска информации по адресу (форма адреса - IP, доменный или URL - в этом случае значения не имеет) пользователю достаточно просто ввести адрес ресурса в соответствующее поле браузера – программы, предназначенной для обеспечения доступа к сетевым ресурсам.

Рис. 1. Способы поиска информации в гипертекстовых базах данных
Второй – поиск с помощью навигации по гиперсвязям. При использовании этого вида поиска случае пользователь сначала должен получить доступ к серверу, связанному с соответствующей БД. После этого можно найти документ, используя гиперссылки. Очевидно, что этот способ удобен, когда адрес ресурса неизвестен пользователю.
Для использования в качестве исходной точки для поиска при реализации этого способа предназначены Web-порталы - серверы, предоставляющие прямой доступ к некоторому множеству серверов, включая установленные на них информационные ресурсы, а также Web-приложения, которые реализуют Web-сервисы, соответствующие назначению портала. Доступные через портал серверы могут относиться к определенной системе (например - корпоративной) или различным системам и быть специально подобраны по видовому, тематическому или другим признакам документов и данных, содержащихся на их сайтах.
|
|
|
Обычно порталы совмещают в себе разнообразные функции с целью удержать клиента как можно дольше. Доминирующим сервисом портала является сервис справочной службы: поиск, рубрикаторы, финансовые индексы, информация о погоде и т.д. Если Web-сайты в большинстве случаев представляют собой наборы статических Web-страниц, то порталы являются совокупностями программных средств и заранее неструктурированной информации, которую эти средства превращают в структурированные данные по запросу конкретных пользователей.
Третий способ поиска предполагает использование поисковых серверов Интернета. Поисковыми серверами называют выделенные хост - компьютеры, в которых размещаются базы данных ресурсов Интернета. Пользовательский интерфейс такого сервера имеет поле для ввода ключевых слов, описывающих тему, интересующую пользователя (См. Рис. 2).

Рис.2. Вид окна поискового сервера системы Яндекс
Эти слова сервер воспринимает как информационный запрос, в соответствии с которым он осуществляет поиск ресурсов и представляет список найденных документов пользователю.
Очевидно, что при реализации этого способа возможны ошибки как 1-го (пропуск цели), так и 2-го рода (информационный шум). Следует упомянуть, что различаются две группы поисковых серверов: поисковые машины и предметные каталоги. Их отличие обусловлено способом создания и последующего пополнения базы данных ресурсов Интернета, которой данный сервер осуществляет информационный поиск. Так, поисковые машины имеют в своем составе специальную программу - поисковый робот. Она осуществляет постоянный мониторинг сети, собирает информацию с Web- страниц, индексирует их и фиксирует их поисковый образ в своей базе данных.
В предметных каталогах база данных о документах Интернета формируется «вручную» специалистами-редакторами. Поскольку в Интернете отсутствует единое администрирование, постольку его информационные ресурсы постоянно меняются. В нём могут появляться новые и исчезать существующие документы. Частота обновления информации в документах для разных сайтов различна: для некоторых — это несколько раз в час, для некоторых — раз в сутки, день, месяц и т.д. Поэтому очень важно понимать, что при использовании информационно-поисковых систем для нахождения информации в Интернете, поиск осуществляется не на реальном пространстве документов Сети, а в некоторой модели, содержание которой может значительно отличаться от действительного содержания Интернет в момент проведения поиска.
По степени охвата индексируемых ресурсов поисковые системы можно разделить на две группы: международные и русскоязычные. Первые индексируют все опубликованные в Интернете документы подряд. Вторые индексируют ресурсы, расположенные в доменных зонах с преобладанием русского языка. Список наиболее популярных систем приведен в Табл. 1.
Табл. 1. Наиболее популярные поисковые системы
| Международные | Русскоязычные |
| Яндекс (44,4 % Рунета) | |
| Yahoo! | Rambler (10,6 % Рунета) |
| Bing | Mail.ru (7,3 % Рунета) |
| MSN | Nigma (0,5 % Рунета) |
| AltaVista | Gogo.ru (0,3 % Рунета) |
| Ask | Aport (0,2 % Рунета) |
Примечание: Рунет – это русскоязычная часть Интернета, составляющая домены с именами ru и рф.
Необходимо упомянуть, что существует особая категория поисковых серверов – метапоисковые системы. Их принципиальное отличие от поисковых машин и предметных каталогов состоит в том, что у них отсутствует собственная индексная база данных, и поэтому они, получив запрос пользователя, перенаправляют его сразу к нескольким поисковым серверам (См. Рис. 3).
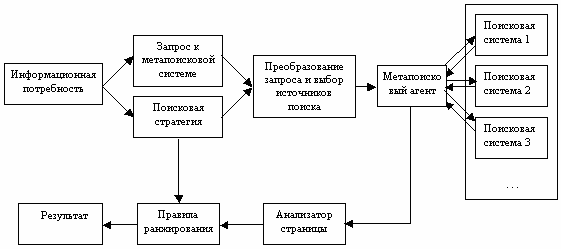
Рис. 3. Схема работы метапоисковой системы
Возможность одновременного использования нескольких поисковых серверов по одному запросу является очевидным преимуществом метапоисковых систем. В настоящее широкое применение время нашла система Metabot.ru, интерфейс которой представлен на Рис. 4. Эта система позволяет использовать для поиска ресурсов как международные, так и русскоязычные поисковые серверы.
Рис.4. Окно метапоисковой системы Metabot.ru
Дата добавления: 2019-01-14; просмотров: 382; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!