Если одна из задач двойственной пары разрешима, то и другая задача также разрешима; причем экстремальные значения обеих задач равны.
35.Поясните понятия: задача многокритериальной оптимизации, множество допустимых решений, оптимальное решение. Дайте общую математическую формулировку задач многокритериальной оптимизации
Векторная (многокритериальная) оптимизация- направление в теории оптимизации, в котором критерием оптимальности яв-ся вектор с несколькими компонентами (критериями). Пусть X обозначает множество возможных решений, содержащее по крайней мере два элемента. Через Se1X обозначим подмножество множества X, которое называют множеством выбираемых (выбранных) решений. Часто это множество состоит из одного элемента, но в некоторых задачах оно может содержать и большее число элементов. Задача принятия решений состоит в осуществлении выбора, т.е. в нахождении множества Se1X с использованием всей имеющейся в наличии информации. Процесс выбора невозможен без того, кто осуществляет выбор, преследуя свои собственные цели. Человека (или целый коллектив, подчиненный достижению определенной цели), который производит выбор и несет ответственность за его последствия, называют лицом, принимающим решение (ЛПР).
Обычно выбранным (наилучшим) оказывается такое решение, которое наиболее полно удовлетворяет стремлениям, интересами и целям ЛПР. Желание ЛПР достичь определенной цели нередко удается в математических терминах выразить в виде максимизации (или минимизации) некоторой числовой функции, которую называют целевой функцией или критерием. Однако в более сложных ситуациях ЛПР приходится иметь дело не с одной, а сразу с несколькими функциями подобного типа.
|
|
|
Пусть имеется т (т≥2) целевых функций, определенных на множестве X. Они образуют так называемый векторный критерий f = (f1, f2,…,fm), который принимает значения в т -мерном арифметическом пространстве Rm. Это пространство называют критериальным пространством.
Задачу выбора решений, включающую множество возможных решений X и векторный критерий f, называют многокритериальной задачей (или задачей векторной оптимизации).
Ключевую роль в многокритериальной оптимизации играет понятие парето-оптимального решения. Решение х*  X называют парето-оптимальным (оптимальным по Парето, эффективным или неулучшаемым), если не существует другого возможного решения x X, такого, что fi(х)
X называют парето-оптимальным (оптимальным по Парето, эффективным или неулучшаемым), если не существует другого возможного решения x X, такого, что fi(х)  fi(х*) длявсех номеров i = 1, 2,...,т, причем по крайней мере для одного номера j (1, 2,..., т) имеет место строгое неравенство fj(х)≥fj(х*). Другими словами, парето-оптимальное решение не может быть улучшено (в данном случае - увеличено) ни по какому критерию (ни по какой группе критериев) при условии сохранения значений по всем остальным критериям. Множество всех парето-оптимальных решений часто обозначают Pf(X) и называют множеством Парето {множеством Эджворта-Парето) или областью компромиссов.
fi(х*) длявсех номеров i = 1, 2,...,т, причем по крайней мере для одного номера j (1, 2,..., т) имеет место строгое неравенство fj(х)≥fj(х*). Другими словами, парето-оптимальное решение не может быть улучшено (в данном случае - увеличено) ни по какому критерию (ни по какой группе критериев) при условии сохранения значений по всем остальным критериям. Множество всех парето-оптимальных решений часто обозначают Pf(X) и называют множеством Парето {множеством Эджворта-Парето) или областью компромиссов.
|
|
|
36.Сформулируйте условие Парето-оптимальности
Ключевую роль в многокритериальной оптимизации играет понятие парето-оптимального решения. Решение х* X называют парето-оптимальным (оптимальным по Парето, эффективным или неулучшаемым), если не существует другого возможного решения x X, такого, что fi(х) fi(х*) длявсех номеров i = 1, 2,...,т, причем по крайней мере для одного номера j (1, 2,..., т) имеет место строгое неравенство fj(х)≥fj(х*). Другими словами, парето-оптимальное решение не может быть улучшено (в данном случае - увеличено) ни по какому критерию (ни по какой группе критериев) при условии сохранения значений по всем остальным критериям. Множество всех парето-оптимальных решений часто обозначают Pf(X) и называют множеством Парето {множеством Эджворта-Парето) или областью компромиссов.
Заметим, что в частном случае, когда критерий всего один, т.е. т = 1, определение парето-оптимального решения превращается в определение точки максимума функции f, на множестве X. Это означает, что парето-оптимальное решение представляет собой обобщение обычной точки максимума числовой функции.
|
|
|
Если каждый критерий fi трактовать как функцию полезности i-го участника экономики, то к понятию парето-оптимального решения приводит воплощение идеи социальной справедливости, состоящей в том, что для коллектива всех участников более выгодным будет только то решение, которое не ущемляет интересы ни одного из них в отдельности. При этом при переходе от одного парето-оптимального решения к другому если и происходит улучшение (увеличение) одного из критериев, то обязательно это улучшение будет сопровождаться ухудшением (уменьшением) какого-то другого критерия (или сразу нескольких критериев). Таким образом, переход от одного парето-оптимального решения к другому невозможен без определенного компромисса. Отсюда и наименование множества Парето - область компромиссов.
При анализе и решении многокритериальных задач обычно считают выполненной так называемую аксиому Парето, согласно которой в случае выполнения неравенств
fi (x’)≥ fi (x’’) для всех номеров i = 1, 2,...,т, где по крайней мере для одного номера
j (1,2,...,т} имеет место строгое неравенство fi (x’)>fi (x’’), ЛПР из двух данных возможных решений х' и х" всегда отдает предпочтение первому из них.
|
|
|
Аксиома Парето фиксирует стремление ЛПР получить максимально возможные значения по всем имеющимся критериям. Кроме того, она показывает, что из пары произвольных решений, то из них, которое не яв-ся в этой паре парето-оптимальным, из указанной пары никогда выбирать не следует. Так как решения, которые не выбираются из пары, разумно не выбирать и из всего множества возможных решений, то в итоге приходим к так называемому принципу Парето (принципу Эджворта-Парето), в соответствии с которым выбирать (наилучшие) решения следует только среди парето-оптимальных.
38.Опишите алгоритм поиска решений методом анализа иерархий
Рассмотрим пример.
Пусть, известно, что для разработки некоторого нефтяного месторождения в результате анализа его геолого-геофизических и геолого-гидродинамических характеристиках определено три благоприятных технологических варианта разработки: законтурное заводнение (D1), циклическое заводнение (D2), циклическое заводнение в сочетании паротепловой обработкой скважин на всех объектах разработки (D3).
Предположим, что из множества показателей эффективности разработки месторождений нефти и газа руководитель выбрал следующие показатели (критерии):
В1. Экономические показателиС1. Чистый дисконтированный доход. С2. Внутренняя норма рентабельности . СЗ. Срок окупаемости С4. Индекс доходности. B2. Риски.С5. Оправданность выбора технических решений (систем (вариантов) разработки). Сб. Надежность контроля за выработкой запасов . С7. Экономический риск. B3. Охрана окружающей среды и недр .С8. Загрязнение воздуха и воды. С9. Сохранность флоры и фауны.
Руководителю необходимо выбрать лучший вариант разработки, с учетом этого набора этих показателей эффективности.
Для поставленной задачи можно построить следующую иерархию (рис. 7.3).
Комплексная эффективность разработки месторождения
Виды критериев
Критерии
Варианты разработки
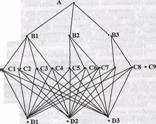 Рис. 7.3
Рис. 7.3
Здесь буквами В обозначены виды критериев (показателей) эффективности разработки месторождений, буквы С обозначают конкретные критерии, буквы D — варианты разработки.
Пусть матрицы парных сравнений (суждений или приоритетов) оказались следующими (табл. 7.11 и 7.12):
Сумма всех элементов матрицы равна 11,33; П - вектор приоритетов.
λmax = (1+0.5+0.33)0.53+(2+1+0.5)0.31+(3+2+1)0.15=2.955 и
ИС= -0.0025, то есть эта матрица яв-ся согласованной. Заметим, что отрицательное значение ИС получается в данном случае в силу приближенности алгоритма вычислений.
1-й уровень
Таблица 7.11
| А | АВ1 | АВ2 | АВЗ | £ по строке | П |
| АВ1 | 1 | 2 | 3 | 6 | 6/11,33 = 0,53 |
| АВ2 | 1/2 | 1 | 2 | 3,5 | 0,31 |
| АВЗ | 1/3 | 1/2 | 1 | 1,83 | 0,15 |
2-й уровень
Таблица 7.12
| B1 | В1С1 | В1С2 | В1СЗ | В1С4 | Σ по строке | П | |||||
| В1С1 | 1 | 1 | 4 | 5 | 11 | 0,38 | |||||
| В1С2 | 1 | 1 | 4 | 5 | 11 | 0,38 | |||||
| В1СЗ | 1/4 | 1/4 | 1 | 4 | 5,5 | 0,19 | |||||
| В1С4 | 1/5 | 1/5 | 1/4 | 1 | 1,65 | 0,05 | |||||
| В2 | В2С5 | В2С6 | В2С7 | Σ по строке | П | ||||||
| В2С5 | 1 | 4 | 2 | 7 | 0,61 | ||||||
| В2С6 | 1/4 | 1 | 1 | 2,25 | 0,19 | ||||||
| В2С7 | 1/2 | 1 | 1 | 2,5 | 0,2 | ||||||
| B3 | ВЗС8 | ВЗС9 | Z по строке | П | |||||||
| ВЗС8 | 1 | 4 | 5 | 0,8 | |||||||
| ВЗС9 | 1/4 | 1 | 1,25 | 0,2 | |||||||
В общей матрице приоритетов второго уровня иерархии (7.10) будет столько столбцов, сколько элементов на предыдущем уровне (в данном случае 3), а строк будет столько, сколько элементов на нижнем уровне (т.е. 9). Эта матрица справа умножается на вектор приоритетов видов критериев: ||П(A,Bi ,Ci)||=
0,38
0,38
0,19
0,05
0,61
0,19
0,2
0,8
0,2
*0,53
0,31
0,15
Вектор приоритетов критериев с учетом приоритета видов критериев по отношению к глобальному критерию будет равен: П (ABi Ci) = [0,2 0,2 0,1 0,03 0,19 0,06 0,07 0,12 0,03] После этого шага составляется 9 матриц сужений (по числу критериев) приоритетов вариантов разработки месторождений (табл. 7.13):
3-й уровень иерархии
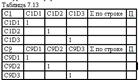 Далее из девяти полученных СППР векторов столбцов приоритетов ею формируется матрица приоритетов третьего уровня иерархии, которая умножается на вектор приоритетов полученный на предыдущем шаге и получается вектор приоритетов вариантов разработки месторождения.
Далее из девяти полученных СППР векторов столбцов приоритетов ею формируется матрица приоритетов третьего уровня иерархии, которая умножается на вектор приоритетов полученный на предыдущем шаге и получается вектор приоритетов вариантов разработки месторождения.
В заключение следует сказать, что если эксперту или руководителю удалось свести задачу выбора лучшего решения к иерархической, то вполне можно использовать метод, описанный в настоящем разделе. Хотя класс задач, сводящихся к методам анализа иерархий достаточно широк (задачи выбора учебного заведения, оценки национального богатства страны, размещения ресурсов и т.п.) существует много проблем, не решаемых этим методом.
Это главным образом задачи, в которых необходимо учитывать взаимную зависимость (взаимное влияние) результирующих факторов друг на друга. В нашем случае это взаимное влияние результатов разработки.
47.Приведите пример моделирования системы массового обслуживания на ЭВМ
Пусть одноканальная СМО с отказами представляет собой один пост ежедневного обслуживания для мойки автомобиля. Заявка – автомобиль, прибывший в момент, когда пост занят, - получает заказ обслуживания. Интенсивность потока автомобилей l=1,0 (автомобиль в час). Средняя продолжительность обслуживания – 1,8 часа. Поток автомобилей и поток обслуживания яв-ся простейшими.
Листинг программы:
L=1; %Лямбда Tc=108;%средняя продолжительность обслуживания
M=1/Tc; %Мю kolvo=30; %Количество повторений опыта
Q=M/(M+L); %относительная пропускная способность
A=L*Q; %абсолютная пропускная способность
P=1-Q; % вероятность отказа N=1/Tc %номинальная пропускная способность
R=N/A; % отношение номинальной к фактической
sum_k1=0; sum_k2=0; sum_k3=0; % time1-общее время обслуживания
time1=0;
for i=1:30
x2=0;%кол-во поступивших заявок x3=0;%кол-во обслуженных заявок
k1=0;%кол-во отказов
for j=1:480
x1=1+floor(59*rand());%поступление заявки
if(x1==1 && time1==0) x2=x2+1; time1=floor(poissrnd(108)); x3=x3+1; end
if(x1==1 && time1>0) x2=x2+1; time1=time1-1; k1=k1+1; end
if(x1>1 && time1>0) time1=time1-1; end
end
sum_k1=sum_k1+k1; sum_k2=sum_k2+x2; sum_k3=sum_k3+x3;
end
sum_k1=floor(sum_k1/30);%сумма отказов
sum_k2=floor(sum_k2/30); sum_k3=floor(sum_k3/30);
disp('количество обслуженных заявок'); disp(x3);
disp('количество поступивших заявок'); disp(x2);
disp('количество отказов'); disp(k1); disp('При 30 опытах: ');
disp('количество обслуженных заявок'); disp(sum_k3);
disp('количество поступивших заявок'); disp(sum_k2);
disp('- количество отказов'); disp(sum_k1);
disp('сред. кол-во обслуж. авт. в час '); disp(sum_k3/8);
37.Дайте общую математическую формулировку метода анализа иерархий
Метод анализа иерархий (МАИ) предложен Т. Саати в конце семидесятых годов прошлого века [7.7]. Основные принципы МАИ основываются на том, что для практических целей система часто рассматривается в терминах ее структуры и функций. В действительности структура и функции между собой тесно связаны. Структура системы позволяет анализировать ее функции, а в процессе функционирования может измениться структура системы. Иерархия яв-ся некоторой абстракцией структуры системы, предназначенной для изучения функциональных взаимодействий ее компонент и их воздействий на систему в целом. Иерархия есть определенный тип системы, особенность которой заключается в том, что элементы системы могут группироваться в связанные множества. Элементы каждой группы находятся под влиянием другой вполне определенной группы элементов и, в свою очередь, оказывают влияние на элементы другой группы. Будем считать, что элементы в каждой группе иерархии (называемой уровнем, кластером) независимы. Заметим, что хотя в этом определении обратная связь не предполагается, тем не менее, многие специалисты считали и считают иерархии важным элементом анализа. Оценка вариантов решений методом анализа иерархий сводится к следующему:
1. Изучаемую систему представляют в виде иерархии, которая изображается графом связей (в простейшем случае типа дерево) между элементами уровней - первый и очень важный этап решения задачи. Нулевой уровень иерархии {фокус иерархии) - глобальный критерий (цель) системы. Следующими уровнями иерархии могут служить: акторы (1- уровень) - участники процесса, действующие силы, организации, коллективы, поведение и предпочтения которых могут воздействовать на результаты (исходы), виды критериев; цели или критерии, определяющие действие акторов; возможные действия акторов - стратегии; альтернативные варианты решений - сценарии прогнозируемого или желаемого будущего, варианты проектов, программ и т.д.
2. Входной информацией для расчетов, выполняемых СППР, служат матрицы парных сравнений приоритетов элементов нижнего уровня иерархии, с точки зрения элементов верхнего (предыдущего) уровня, составляемые экспертами (или руководителями). По этим матрицам СППР рассчитывает вектор относительных приоритетов, являющийся собственным нормированным вектором матрицы суждений, который чаще всего, однако, вычисляется по следующему приближенному алгоритму: в матрице суждений необходимо суммировать элементы каждой строки и нормализовать сумму делением ее на сумму всех элементов матрицы; сумма полученных результатов будет равна единице; первый элемент результирующего вектора будет приоритетом первого объекта, второй - второго и т.д.
Следуя для парных сравнений эффективнее всего использовать 9-балльную шкалу, исходя из которой составляется матрица приоритетов (суждений), хотя при необходимости, могут бить использованы и лингвистические переменные. Эта 9-балльная шкала выглядит следующим образом:
1 - одинаковая значимость (два сравниваемых фактора (объекта) вносят одинаковый вклад в конечный результат); 3 - слабое преобладание (легкое предпочтение отдается 1 объекту); 5 - существенное преобладание; 7 - очевидное преобладание; 9 - абсолютное преобладание; 2, 4, 6, 8 - промежуточные значения преобладания (например, 2 -слабо-существенное преобладание).
Матрица суждений составляется таким образом, что если приоритет i-ro объекта перед j-м есть bij, то приоритет j-го объекта перед i-м - l/bij, a bii=l и bii не равно нулю.
Сложность составления матрицы приоритетов состоит в том, что оценки руководителя могут оказаться несогласованными. Например, сравнивая три объекта Cl, C2, С3 они могут дать следующие противоречивые оценки: C1 = 5С2 , C1= 6С3 ,С2 = 4С3, т.е. С1 = 20С3 , и Q= 6С3.
Для контроля согласованности матриц приоритетов вычисляются две характеристики этой матрицы: индекс согласованности (ИС) и отношений согласованности (ОС):
ИС = 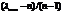
где n- размерность матрицы приоритетов (число сравниваемых объектов);
λmax - наибольшее собственное значение (число) матрицы суждений, которое чаще всего вычисляется по следующему алгоритму, сначала суммируется каждый столбец матрицы суждений, затем сумма первого столбца умножается на величину первой компоненты, рассчитанного вектора приоритетов, сумма второго столбца на вторую и т.д.; затем полученные числа суммируются и получается значение Хтоах.
Можно показать, что при Хтах=п обратносимметрическая матрица, которой яв-ся матрица суждений, яв-ся идеально согласованной.
Индекс согласованности, сгенерированный случайным образом, называется случайным индексом согласованности (СИ). В табл. 7.10 приведены значения СИ в зависимости от числа п столбцов (строк) матрицы суждений.
Отношение ИС к СИ называется отношением согласованности (ОС) ОС=ИС/СИ. Значение ОС меньшее или равное 0.10 считается приемлемым [7.7], если нет, то руководителю необходимо пересмотреть свои приоритеты или даже саму иерархию.
| N | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| СИ | 0.00. | 0.00 | 0.00 | 0.58 | 0.90 | 1.12 | 1.3200 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 1.41 | 1.45. | 1.48 | 1.51 | 1.54 | 1.56 | 1.57 | 1.59 |
3. Из векторов приоритетов, оценивающих влияние элементов i+1 го уровня на каждый связанный с ним элемент i-го уровня (связь фиксируется наличием соответствующей дуги в графе иерархии), образуется матрицу приоритетов, которая умножается справа на вектор приоритетов полученный на i-м уровне иерархии и получается вектор приоритетов i+1-го уровня.
4. Последовательное вычисление приоритетов элементов от верхних уровней к нижним позволяет численно оценить влияние всех включенных в иерархию элементов (акторов, стратегий, видов критериев, критериев, сценариев, действий и т. д.) на возможные исходя (терминальные вершины графа иерархии).
5. Сравнивая полученные приоритеты для элементов последнего уровня можно установить соотношения в их значимости (выгодности, эффективности) с точки зрения руководителя. Если задача состоит в выборе одного из альтернативных решений, то предпочтение следует отдать варианту с наибольшим приоритетом.
51.Опишите функциональные возможности пакета прикладных программ MATLAB как средства моделирования систем
Программа Simulink яв-ся приложением к пакету MATLAB. При моделировании с использованием Simulink реализуется принцип визуального программирования, в соответствии с которым, пользователь на экране из библиотеки стандартных блоков создает модель устройства и осуществляет.
При моделировании пользователь может выбирать метод решения дифференциальных уравнений, а также способ изменения модельного времени (с фиксированным или переменным шагом). В ходе моделирования имеется возможность следить за процессами, происходящими в системе. Для этого используются специальные устройства наблюдения, входящие в состав библиотеки Simulink. Результаты моделирования могут быть представлены в виде графиков или таблиц.
Stateflow - инструмент для численного моделирования систем, характеризующихся сложным поведением. К числу таких систем относятся гибридные системы. Примерами гибридных систем могут служить системы управления, используемые в промышленности (автоматизированные технологические процессы), в быту (сложные бытовые приборы), в военной области (высокотехнологичные виды вооружений), в сфере космонавтики, транспорта и связи. Все эти системы состоят из аналоговых и дискретных компонентов. Поэтому гибридные системы - это системы со сложным взаимодействием дискретной и непрерывной динамики. Они характеризуются не только непрерывным изменением состояния системы, но и скачкообразными вариациями в соответствии с логикой работы управляющей подсистемы, роль которой как правило выполняет то или иное вычислительное устройство (конечный автомат).
В том случае, когда логика работы управляющей подсистемы яв-ся жесткой, а внешние условия относительно стабильны, говорят о трансформационных системах. Для таких систем фазы получения информации, её обработки и выдачи выходных сигналов четко разграничены. На момент обращения к системе все входные сигналы определены. Сигналы на выходах образуются после некоторого периода вычислений. Вычисления производятся по некоторому алгоритму, трансформирующему (преобразующему) входной набор данных в выходной.
В противоположном случае систему относят к классу управляемых событиями или реактивных. Реактивная - это такая динамическая система, которая воспринимает внешние дискретные воздействия и отвечает своими реакциями на эти воздействия. Причем реакции системы различны и сами зависят как от воздействий, так и от состояния, в котором система находится. Основное отличие реактивных систем от трансформационных - в принципиальной непредсказуемости моментов поступления тех или иных воздействий. Эта непредсказуемость - следствие изменчивости условий, в которых такие системы работают.
39.Дайте определение типовых математических схем массового обслуживания, укажите основные соотношения математической схемы процесса обслуживания
Системы массового обслуживания - это такие системы, в которые в случайные моменты времени поступают заявки на обслуживание, при этом поступившие заявки обслуживаются с помощью имеющихся в распоряжении системы каналов обслуживания.
Основные соотношения. Вкачестве процесса обслуживания могут быть представлены различные по своей физической природе процессы функционирования экономических, производственных, технических и других систем, например потоки поставок продукции некоторому предприятию, потоки деталей и комплектующих изделий на сборочном конвейере цеха, заявки на обработку информации ЭВМ от удаленных терминалов и т. д. При этом характерным для работы таких объектов яв-ся случайное появление заявок (требований) на обслуживание и завершение обслуживания в случайные моменты времени, т. е. стохастический характер процесса их функционирования. Остановимся на основных понятиях массового обслуживания, необходимых для использования Q-схем, как при аналитическом, так и при имитационном.
В любом элементарном акте обслуживания можно выделить две основные составляющие: ожидание обслуживания заявкой и собственно обслуживание заявки. Это можно изобразить в виде некоторого i-го прибора обслуживания Пi (рис. 1.1), состоящего из накопителя заявок Hi в котором может одновременно находиться li =  заявок, где LiH — емкость i-го накопителя, и канала обслуживания заявок (или просто канала) Ki. На каждый элемент прибора обслуживания Пi поступают потоки событий: в накопитель Hi — поток заявок wi, на канал Ki —- поток обслуживаний ui.
заявок, где LiH — емкость i-го накопителя, и канала обслуживания заявок (или просто канала) Ki. На каждый элемент прибора обслуживания Пi поступают потоки событий: в накопитель Hi — поток заявок wi, на канал Ki —- поток обслуживаний ui.
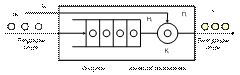
Рис.3.1. Прибор обслуживания заявок
Потоком событий называется последовательность событий, происходящих одно за другим в какие-то случайные моменты времени. Различают потоки однородных и неоднородных событий. Поток событий называется однородным, если он характеризуется только моментами поступления этих событий (вызывающими моментами) и задается последовательностью .{tn} = { 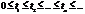 }, где tn — момент наступления n-го события — неотрицательное вещественное число. Однородный поток событий также может быть задан в виде последовательности промежутков времени между n-м и (n-1)-м событиями {τn}, которая однозначно связана с последовательностью вызывающих моментов {tn}, где τn = tn- tn - tn-1 ≥1, to = 0, т. е. τ1 = t1.
}, где tn — момент наступления n-го события — неотрицательное вещественное число. Однородный поток событий также может быть задан в виде последовательности промежутков времени между n-м и (n-1)-м событиями {τn}, которая однозначно связана с последовательностью вызывающих моментов {tn}, где τn = tn- tn - tn-1 ≥1, to = 0, т. е. τ1 = t1.
Потоком неоднородных событий называется последовательность (tn, fn), где tn - вызывающие моменты; fn — набор признаков события. Например, применительно к процессу обслуживания для неоднородного потока заявок могут быть заданы принадлежность к тому или иному источнику заявок, наличие приоритета, возможность обслуживания тем или иным типом канала и т. п.
Рассмотрим поток, в котором события разделены интервалами времени τ1, τ2,..., которые вообще яв-ся случайными величинами. Пусть интервалы τ1, τ2,... независимы между собой. Тогда поток событий называется потоком с ограниченным последействием.
Пример потока событий приведен на рис. 1.2, где обозначено Tj — интервал между событиями (случайная величина); TH — время наблюдения, Tс — момент совершения события.

Рис. 3.2. Схема потока событий
Интенсивность потока можно рассчитать экспериментально по формуле
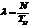 , (3.1) где N — число событий, произошедших за время наблюдения TH. Если Tj=const или определено какой-либо формулой Tj=f(Tj-1), то поток называется детерминированным. Иначе поток называется случайным. Случайные потоки бывают:
, (3.1) где N — число событий, произошедших за время наблюдения TH. Если Tj=const или определено какой-либо формулой Tj=f(Tj-1), то поток называется детерминированным. Иначе поток называется случайным. Случайные потоки бывают:
o ординарными, когда вероятность одновременного появления 2-х и более событий равна нулю;
o стационарными, когда частота появления событий постоянная;
o без последействия, когда вероятность не зависит от момента совершения предыдущих событий.
Поток событий называется ординарным, если вероятность того, что на малый интервал времени 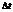 , примыкающий к моменту времени t, попадает больше одного события Р>1 (t, ), пренебрежительно мала по сравнению с вероятностью того, что на этот же интервал времени попадает ровно одно событие Р1 (t, ), т. е. Р1 (t, ) >> Р>1 (t, ). Если для любого интервала событие
, примыкающий к моменту времени t, попадает больше одного события Р>1 (t, ), пренебрежительно мала по сравнению с вероятностью того, что на этот же интервал времени попадает ровно одно событие Р1 (t, ), т. е. Р1 (t, ) >> Р>1 (t, ). Если для любого интервала событие
Р0 (t, ) +Р1 (t, ) + Р>1 (t, )=1 (3.2)
как сумма вероятностей событий, образующих полную группу и несовместных, то для ординарного потока событий
Р0 (t, ) +Р1 (t, ) 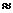 1, Р>1 (t, )=0( ), где 0( ) - величина, порядок малости которой выше, чем , т. е.
1, Р>1 (t, )=0( ), где 0( ) - величина, порядок малости которой выше, чем , т. е.
lim [0( )/ ]=0.
Стационарным потоком событий называется поток, для которого вероятность появления того или иного числа событий на интервале времени τ зависит лишь от длины этого участка и не зависит от того, где на оси времени 0t взят этот участок. Рассмотрим на оси времени t ординарный поток событий и найдем среднее число событий, наступающих на интервале времени , примыкающем к моменту времени t. Получим
0×Р0 (t, ) +1×Р1 (t, )= Р1 (t, ) (3.3)
Тогда среднее число событий, наступающих на участке времени в единицу времени, составит [Р1 (t, )]/ . Рассмотрим предел этого выражения при →0. Если этот предел существует, то он называется интенсивностью (плотностью) ординарного потока событий lim [Р1 (t, )]/ =λ(t). Интенсивность потока может быть любой неотрицательной функцией времени, имеющей размерность, обратную размерности времени. Для стационарного потока его интенсивность не зависит от времени и представляет собой постоянное значение, равное среднему числу событий, наступающих в единицу времени λ(t)= λ=const.
40.Дайте характеристику метода статистического моделирования систем на ЭВМ
. Статическое моделирование на ЭВМ. Моделирование дискретных и непрерывных случайных величин.Статистическое моделирование. Для реализации статистического моделирования на ЭВМ прибегают к методу статистических испытаний (метод Монте-Карло). Метод статистических испытаний применяют при моделировании случайных процессов, которые невозможно или трудно описать аналитически.
Алгоритм метода статистических испытаний: 1)- разыгрывается случайное явление с помощью некоторой процедуры, которая даёт случайный результат 2)- проводится большое количество реализаций 3)- полученные результаты обрабатываются методами теории вероятности и рассчитываются оценки искомых величин
Метод статистических испытаний - это метод математического моделирования случайных величин, где каждый случайный фактор моделируется с помощью розыгрыша. Недостаток метода - необходимость проведения большого количества испытаний, чтобы получить результат с заданной точностью. При статистическом моделировании систем на ЭВМ имитация любых случайных процессов сводится к генерированию равномерно распределенных на [0;1] случайных чисел и их последующему функциональному преобразованию. Для получения (генерации) такой СВ используют генераторы случайных чисел. Выделяют 3 способа генерации: аппаратный (физический); табличный (файловый); алгоритмический (программный) - на рекуррентных формулах. Наиболее распространен программный. При использовании программного метода получают т.н. псевдослучайные величины, т.к. рекуррентная формула связывает значения соседних членов некоторой последовательности, она позволяет шаг за шагом определить любой член последовательности, если известны ее первые члены. Если каждый цикл работы генератора (псевдослучайных чисел) начинается с одними и теми же исходными данными (начальными значениями), то на выходе получаются одинаковые последовательности чисел.
Моделирование дискретных случайных величин.
1. Моделирования события. Если случайное число меньше вероятности события, то событие наступило; если случайное число больше или равно вероятности события, то событие не наступило.
2. Моделирование дискретно-распределительных случайных величин. Если случайное число Ri попало в интервал, то случайная величина приняла значение Pi.
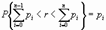
где p0=0.
Моделирование непрерывных случайных величин.
Для разыгрывания непрерывных случайных величин применяют метод обратных функций.
СВ Х может быть задана либо функцией распределения F(x), либо функцией вероятностей (плотность вероятности) f(x).
Функция распределения устанавливает вероятность того, что непрерывная СВ X примет значение, не большее х:
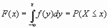 . Функция плотности вероятности устанавливает вероятность того, что случайная величина примет значение из интервала [a;b]:
. Функция плотности вероятности устанавливает вероятность того, что случайная величина примет значение из интервала [a;b]:
 .
.
Отсюда два правила:
1. Для того чтобы разыграть возможное значение xi непрерывной СВ Х, зная ее функцию распределения F(x) надо выбрать случайное число ri, приравнять его функции распределения и решить относительно xi полученное уравнение F(xi)=ri.
Пример: найдем явную формулу для разыгрывания непрерывной СВ Х, распределенной равномерно в интервале (a, b), зная ее функцию распределения F(x)=(x-a)/b-a) (a<x<b).
Решение: Приравниваем заданную функцию распределения случайному числу ri:
(xi-a)/b-a)=ri
xi=(b-a)ri+a.
2. Для того чтобы разыграть возможное значение Xiвеличины X, зная её плотность вероятности f(X) надо выбрать случайное число ri, приравнять его к функции распределения и решать относительно 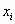 полученное уравнение:
полученное уравнение:
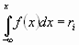 или
или 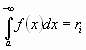
, где а - наименьшее возможное конечное значение величины X.
Пример: найдем явную формулу для разыгрывания непрерывной СВ Х, распределенной равномерно в интервале (a, b), зная ее функцию плотности f(x)=1/(b-a).
Решение: Выбираем случайное число ri и решаем уравнение

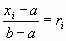 хi = (b-a)ri + a.
хi = (b-a)ri + a.
50.Перечислите известные инструментальные средства моделирования систем
В настоящее время коми, промышленность предлагает целый ряд разнообразных средств мод-я, позволяющих не только моделировать сложные динамич. системы, но и проводить с ними эксперименты.
Наиболее полное исследование общих систем проблем получ-ся в рез-те моделирования объекта с помощью совр. технологии реализованных в специализированных вычислит, пакетах или пакетах визуального моделирования. В них пользователю предоставляется возможность описывать моделируемую систему преимуществ в визуальной форме. Например: графич. представляя как структуру системы, так и ее поведение.
Из множества существующих пакетов визуального моделирования особый интерес, вызывают универсальные пакеты, неориентированные на определенную узко специальную область (физика, химия) или опред. типы моделей, а позволяющих моделировать принадлежащие различным прикладным областям сложные динамические системы.
Не смотря на то, что современные универсальные пакеты визуального моделирования обладают рядом общих свойств. Они позволяют строить из блоков функциональные иерархические схемы и доставляют пользователю схожие библиотеки численных методов, средства визуализации поведения и наборы анимационных возможностей, поддерживают технологию ООП. Все же их можно разделить на 3 группы:
1. Пакеты, использующие язык блочного мод-я.
2. Пакеты, использующие язык физического моделирования.
3. Пакеты, ориентированные на использование схем гибридного автомата.
1. Пакеты, использующие язык блочного мод-я.
Пакеты используют графический язык иерархических блок-схем. Блок высшего уровня иерархии собир-ся из некоторого набора стандартных блоков, созданных раннее разработчиками пакета, либо использованы самим пользователем, соединенных функциональными однонаправленными связями.
К достоинствам этого подхода следует отнести простоту создания не очень сложных моделей, даже неподготовленным пользователям. В то же время при создании сложных моделей приход-ся строить многоуровневые громосткие схемы, неотражающие естеств. структуры моделируемая система, что осложняет процесс моделирования.
К наиболее известным представителям относятся: подсистема Simulink пакета MATLAB, пакет EASY5 SystemBuild пакета (MATRIX) и др.
2. Пакеты, использующие язык физического моделирования.
Пакеты позволяют при создании моделей использовать неориентированные и потоковые связи, пользователь может сам определять новые классы блоков. Непрерывная составляющая поведения элемент, блока, задается системой алгебра диф. уравнений и формул. Дискретная составляющая задается описанием дискретных событий, при возникновении которых могут вып-ся мгновенные присваивания переменным новые значения. Подход очень удобен и естественен для описания типовых блоков физических систем.
Недостатком яв-ся необходимость символьных преобразований, что резко снижают описание гибридного поведения, а также необходимость численного решения большого числа алгебраических уравнений, что значительно услажняет задачу автоматического получения достоверного решения. К наиболее простейшим относятся: Dymola, Omola, OmSim, Smile, Modelica.
3. Пакеты, ориентированные на использование схем гибридного автомата.
Группа включает в себя пакеты, основанные на использовании схемы гибридного автомата. Использование карты состояний при описании переключ-я состояний, а также непосредственные описания поведений системы с системами алгебра -диф. уравнений, предоставдяет большие возможности в описании гибридного поведения со сложной логикой переключения.
Недостатки: избыточность описаний, при моделировании чистых непрерывных систем. Пример: пакеты Shibt, Model Visin Studium.
41.Опишите способы генерации последовательности случайных чисел, используемые при моделировании систем на ЭВМ
На практике в большинстве случаев применяются программные методы получения случайных чисел. на самом дел'е случайные последовательности, получаемые по некоторому алгоритму, яв-ся псевдослучайными. это происходит из-за того, что связь между значениями в последовательности, получаемой программным путем, обычно все-таки существует. данное обстоятельство приводит к тому, что на каком-то этапе генерируемая последовательность чисел начинает повторяться — «входит в период». рассмотрим несколько наиболее известных и пригодных для практического использования программных методов генерации псевдослучайных величин (все же, понимая смысл выражения, будем по привычке и для удобства называть их случайными).
конгруэнтный метод генерации последовательности случайных чисел
конгруэнтный метод генерации последовательности случайных чисел получил широкое распространение. он описан во многих источниках, но конкретных рекомендаций по его использованию на платформе intel автор не встретил. попытаемся устранить этот недостаток. в основе этого метода генерации последовательности случайных чисел лежит понятие конгруэнтности. по определению, два числа а и в конгруэнтны (сравнимы) по модулю м в случае, если существует число к, при котором а-в=км, то есть если разность а-в делится на м, и числа а и в дают одинаковые остатки от деления на м. например, числа 85 и 5 конгруэнтны по модулю 10, так как при делении на 10 дают остаток 5 (при к=1). в соответствии с этим методом каждое число в этой последовательности получается исходя из следующего соотношения:
хn+1=(ахn+с) mod m, где n > 0. (1)
при задании начального значения хо, констант а и с данное соотношение однозначно определяет последовательность целых чисел x,, составленную из остатков от деления на m предыдущих членов последовательности, в соответствии с соотношением (1). величина этих чисел не будет превышать значение т. если каждое число этой последовательности разделить на т, то получится последовательность случайных чисел из интервала 0.1.1'. но не спешите подставлять в это соотношение какие-либо значения. основная трудность при использовании этого метода — подбор компонентов формулы. в зависимости от значения с различают два вида конгруэнтного метода — мультипликативный (с=0) и смешанный (с не равно 0).
мультипликативный конгруэнтный метод генерации последовательности случайных чисел
мультипликативный конгруэнтный метод задает последовательность неотрицательных целых чисел xj (xj<m), получаемых по формуле:
хn+1=ахn(mod m). (2)
на значения накладываются ограничения:
· хо — нечетно;
· а=52р+1 (р=0, 1, 2, ...) или a=2m+3 (m=3, 4, 5, ...) — обе эти записи означают, что младшая цифра а при представлении а в восьмеричной системе счисления должна быть равна 3 или 5 (проще говоря, остаток от деления а/8 должен быть равен 3 или 5);
· m=2 (1>4).
при соблюдении этих ограничений, длина периода будет равна m/4.
смешанный конгруэнтный метод генерации последовательности случайных чисел
соотношение смешанного конгруэнтного метода выглядит так: xn+1=(axn+c) mod m, где n > 0. при правильном подборе начальных значений элементов кроме увеличения периода последовательности случайных чисел уменьшается корреляция (зависимость) получаемых случайных чисел.
на значения накладываются ограничения:
· х0>0;
· а=21+1, где 1>=2;
· с>0 взаимно просто с m (это выполнимо, если с — нечетно, а т=2р, где (р>=2)
· m=2р (р>=2) и т кратно 4.
аддитивный генератор случайных чисел
генератор, формирующий очередное случайное число в соответствии с отношением (3), называется аддитивным:
xn+1=(xn+xn-k) mod m. (3)
в трехтомнике кнута [5] обсуждаются подобные генераторы и рекомендован следующий вариант формулы (3):
xn+1=(xn-24+xn-55) mod m.(4)
здесь n > 55, m=21, хо, ..., х54 — произвольные числа, среди которых есть и нечетные. при этих условиях длина периода последовательности равна 21-1 (255-1). для генерации первых 55 случайных чисел можно использовать один из рассмотренных выше генераторов. возьмем датчик линейной (смешанной) конгруэнтной последовательности случайных чисел (с > 0).
программа генерации высокослучайных двоичных наборов
для процесса генерации требуются два значения одинаковой размерности — y и с. значение y будет первым в последовательности случайных чисел. значение с играет роль маски, в соответствии с которой впоследствии будет производиться операция «исключающее или». генерация очередного случайного числа происходит в два этапа. на первом этапе значение y сдвигается влево на один разряд. при этом нас интересует содержимое выдвинутого бита. его значением устанавливается флаг eflags.cf. на втором этапе, если cf=1, то корректируем значение y= =y xor с и сохраняем y; в противном случае сохраняем сдвинутое значение в качестве очередного числа последовательности.
этот датчик хорош, когда его используют для получения одиночных случайных значений, а не всей последовательности сразу. поэтому в этой программе отсутствует цикл, характерный для предыдущих программных датчиков, и ее удобно оформить в виде процедуры или макрокоманды. в заключение данной темы — высказывание джорджа марсальи, которое приводит кнут : «генератор случайных чисел во многом подобен сексу: когда он хорош — это прекрасно, когда он плох, все равно приятно». возможно, экспериментируя с примерами данного раздела, вы испытали подобное чувство.оценка качества последовательности производится по определенным критериям, подробное рассмотрение которых не яв-ся предметом данной книги, но все же требует упоминания. в большинстве случаев для быстрой оценки качества работы генератора случайной последовательности достаточно использовать следующие критерии.
· длина периода и длина апериодичности. под длиной периода понимается длина максимальной, не содержащей самой себя, числовой цепочки в последовательности случайных чисел. длина апериодичности — длина подинтервала последовательности случайных чисел, в пределах которого не встречаются одинаковые значения.
· равномерность последовательности псевдослучайных чисел. этот критерий означает вероятность попадания значений, генерируемых датчиком случайных чисел, в каждый из m подинтервалов, на которые можно разбить весь интервал значений, генерируемых данным датчиком случайных чисел.
· стохастичность последовательности псевдослучайных чисел. этот критерий означает определение вероятности появления единиц (нулей) в определенных п разрядах генерируемых датчиком случайных чисел.
· независимость элементов псевдослучайной последовательности. этот критерий определяет степень корреляции (зависимости) двух случайных величин в сгенерированной последовательности. при проведении оценки по этому критерию можно рассматривать любые, а не только рядом стоящие случайные величины последовательности.
42.Опишите, что представляют собой конгруэнтные процедуры генерации последовательностей
На практике в большинстве случаев применяются программные методы получения случайных чисел. на самом дел'е случайные последовательности, получаемые по некоторому алгоритму, яв-ся псевдослучайными. это происходит из-за того, что связь между значениями в последовательности, получаемой программным путем, обычно все-таки существует. данное обстоятельство приводит к тому, что на каком-то этапе генерируемая последовательность чисел начинает повторяться — «входит в период». рассмотрим несколько наиболее известных и пригодных для практического использования программных методов генерации псевдослучайных величин (все же, понимая смысл выражения, будем по привычке и для удобства называть их случайными).
 конгруэнтный метод генерации последовательности случайных чисел
конгруэнтный метод генерации последовательности случайных чисел
конгруэнтный метод генерации последовательности случайных чисел получил широкое распространение. он описан во многих источниках, но конкретных рекомендаций по его использованию на платформе intel автор не встретил. попытаемся устранить этот недостаток. в основе этого метода генерации последовательности случайных чисел лежит понятие конгруэнтности. по определению, два числа а и в конгруэнтны (сравнимы) по модулю м в случае, если существует число к, при котором а-в=км, то есть если разность а-в делится на м, и числа а и в дают одинаковые остатки от деления на м. например, числа 85 и 5 конгруэнтны по модулю 10, так как при делении на 10 дают остаток 5 (при к=1). в соответствии с этим методом каждое число в этой последовательности получается исходя из следующего соотношения: хn+1=(ахn+с) mod m, где n > 0. (1)
при задании начального значения хо, констант а и с данное соотношение однозначно определяет последовательность целых чисел x,, составленную из остатков от деления на m предыдущих членов последовательности, в соответствии с соотношением (1). величина этих чисел не будет превышать значение т. если каждое число этой последовательности разделить на т, то получится последовательность случайных чисел из интервала 0.1.1'. но не спешите подставлять в это соотношение какие-либо значения. основная трудность при использовании этого метода — подбор компонентов формулы. в зависимости от значения с различают два вида конгруэнтного метода — мультипликативный (с=0) и смешанный (с не равно 0).
Дата добавления: 2018-05-09; просмотров: 533; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!