Метод интерполяций ( иногда экстраполяций)
Данный метод не просто определяет зону нового поиска, но и оценивает величину нового шага. Алгоритм носит название экстраполяционного метода и имеет скорость сходимости большую, чем первые два метода.
Если при поиске по бинарному дереву за каждый шаг массив поиска уменьшался с N значений до N/2 , то при этом методе за каждый шаг зона поиска уменьшается с N значений до корня квадратного из N. Если К лежит между Kn и Km , то следующий шаг делаем от n на величину
(n - m)*(K - Kn)/(Km - Kn)
Скорость экстраполяционнго метода начинает существенно превышать скорость метода половинного деления при больших значениях N.
Если необходимо данные искать в небольшом массиве и искать нужно нечасто, проще воспользоваться методом перебора всех значений массива;
Если массив значений большой и искать данные нужно часто, следует отсортировать массив и воспользоваться методом половинного деления или ‘методом экстраполяций.
При оценке времени, которое затрачивает алгорит на поиск имеют значение две величины. Во-первых, это размерность массива (количество элементов) и, во-вторых, это количество
обращений (то есть, сколько раз нам нужно 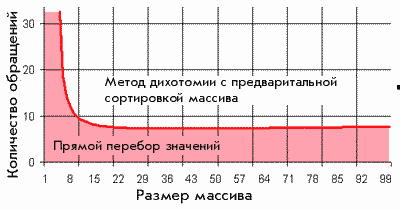 в нем искать).
в нем искать).
Итак, имеем массив размерностью N и проводим М раз в нем поиск.
Количество операций, которые выполнит алгоритм прямого перебора, пропорционально M*N. Метод дихотомии совершит 2М*Log(2)N операции , да еще и время на сортировкку надо прибавить - N*Log(2)N
Итак, имеем два выражения :
T1 = M*N;
T2 = 2М*Log(2)N + N*Log(2)N
При Т1 = Т2 мы находимся на границе, на которой одинаково оптимальны оба алгоритма. Из этого равенства можно получить области в системе координат "Количество обращений - Размерность массива", определяющие оптимальность одного алгоритма относительно другого.
Способы коррекции алгоритмов поиска
До сих пор мы считали, что каждое значение массива с одинаковой вероятностью может оказаться искомым.
Но это утверждение не для всех задач верно.
Динамическийо метод коррекции поиска или метод "Самоорганизующегося" списка. Идея метода проста - когда мы находим нужный элемент, мы перемещаем его в начало списка (начало массива)., В итоге, часто используемые элементы будут расположены довольно близко к началу массива. Таким образом, количество сравнений до удачного поиска будет минимизироваться.
Данный способ, естественно, стоит применять в случае наибольшей вероятности именно удачного поиска.
Похожим методом являеется метод транспозиции. В данном методе найденный элемент переставляется на один элемент к голове списка. Если к этому элементу обращаются часто, то постепенно перемещаясь к началу списка, он скоро окажется в его голове. Этот метод удобен тем, что он эффективен не только в списковых структурах, но и в неупорядоченных массивах, т.к. меняются местами только два рядом стоящих элемента.
Если поиск конкретного элемента производится один раз, то можно воспользоваться динамическим методом "очищаемого" списка. Это не самостоятельный метод поиска, а именно коррекция одного из методов описанных выше. Когда при удачном поиске значения, запись ему соответствующая, удаляется из массива, уменьшая такми образом его размерность.
До сих пор мы считали, что в рассматриваемых задачах вероятность удачного поиска достаточно велика. Представим себе, что поиск поисходит в неком массиве, про который мы точно знаем, что искомые значения скорее всего там не содержатся!
Можно минимизировать количество сравнений, заранее отсекая неудачный поиск, то есть значения ,которых нет в массиве. Предположим, что у нас есть большой массив отсортированных значений. Достаточно перед началом поиска очередного значения проверить, а попадает ли оно в принципе в массив? Но применять этот способ коррекции алгоритма можно только в том случае, если вероятность неудачного поиска достаточно велика. Потому как при большой размерности массива еще и прибавлять сравнение на каждом шаге можно только в том случае, если очередное сравнение скорее всего заменит нам очередной виток поиска.
Оценим, какова должна быть вероятность неудачного поиска, то есть отсутствие искомого значения в массиве, чтобы было выгодно применять эту модификацию алгоритма.
Пусть Р - вероятность того, что искомое значение отсутствует между минимальным и максимальным значением массива. Тогда мы, отсекая сверхэкстремальные значения, в среднем не производим Р*(С - 2) операций, где С - среднее число операций при проведении немодифицированного поиска. В то же время мы вынуждены впустую совершить 2*(1 - Р) операций для сравнения значения с минимальным и максимальным в массиве. Так как мы должны быть в выигрыше, то
Р*(С - 2) > 2*(1 - Р) , следовательно PC -2P + 2P - 2 > 0
РС > 2 , ну и наконец : P > 2/C
Таким образом, приP > 2/Cмы будем в выигрыше. Например, для поиска по бинарному дереву в случае массива с 32 элементами достаточно один раз из четырех задавать сверхэкстремальное значение для поиска, чтобы модифицированный алгоритм работал быстрее.
Дата добавления: 2018-05-02; просмотров: 750; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!