Разработка алгоритма
Первая программа является наиболее простой, поэтому начнем с неё. Совершенно очевидно, что первая программа должна работать по алгоритму, показанному на рисунке 1.1.
В данной блок-схеме под f(x) понимается функция (1.1), под g(sgm) понимается некоторая функция, которая возвращает случайное число, подчиняющееся нормальному распределению, с заданной дисперсией sgm.
Генерация случайного значения в данной задаче (как будет показано в следующем разделе) основана на центральной предельной теореме, т.е. случайное число получается суммой большого числа случайных чисел с равномерным распределением.
Общий алгоритм работы второй программы показан на рисунке 1.2. Блоки прямого хода, обратного хода и заполнение исходной матрицы со свободным вектором, для экономии места, представим в нотации Найси-Шнайдермана (так называемые структурограммы [1, стр.286]). На рисунке 1.3 показана струкутрограмма алгоритма заполнения исходной матрицы и свободного вектора, а на рисунке 1.4 показана структурограмма метода Гаусса. В структорограмме рисунка 1.3 под массивом Y{} понимается файл с точками. Так же следует обратить внимание на то, что, хотя нумерация элементов массивов и идет с нуля, следует передавать размер массива натуральным числом. Запись вида A{ a i,j=0} m x m подразумевает двумерный массив размером m x m, заполненный при передаче нулевыми элементами. Индексация элементов в массивах при такой записи всегда от 0 и до m-1.
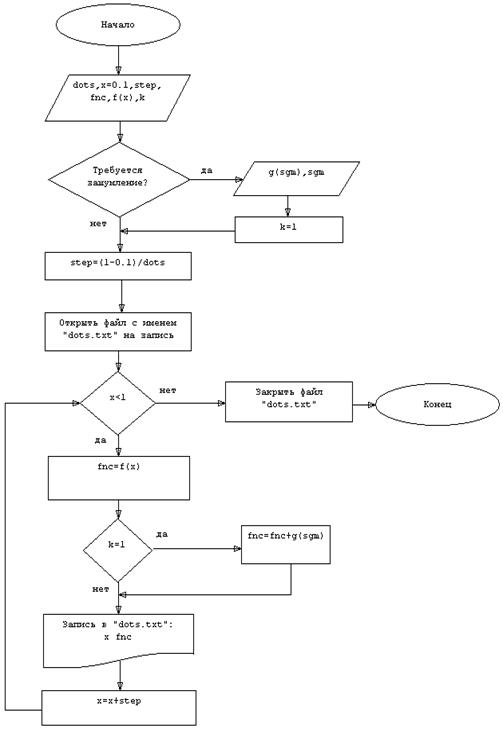
Рисунок 1.1 Алгоритм работы программы создания точек

Рисунок 1.2 Алгоритм работы программы аппроксимации
| # Под m здесь понимается реальный размер, как это принято в математике. Индексация многомерных массивов начинается с нуля и заканчивается m-1. | ||||||
| Ввод A{ a i,j=0} m x m, b{bi = 0}0… m-1, Y{xi, yi}0…n | ||||||
| для i от 0 | ||||||
| для k от 0 | ||||||
| для j от k | ||||||
| ak, j = ak, j + j k (x i) × j j (x i) | ||||||
да | нет | |||||
| aj, k = ak, j | ||||||
| до m-1 | ||||||
| b k = b k + j k (x i) × y i | ||||||
| до m-1 | ||||||
| до n | ||||||
| Вывод A{ a i,j} m x m, b{bi }0… m-1 |
Рисунок 1.3 Подготовка массивов для обработки
| # Под m здесь понимается реальный размер, как это принято в математике. Индексация многомерных массивов начинается с нуля и заканчивается m-1. | |||||
| Ввод A{ a i,j} m x m, a{ai}0… m-1, b{bi = 0}0… m-1 | |||||
| для k от 0 | |||||
| для i от k+1 | |||||
| W = ai, k / ak, k | |||||
| для j от k | |||||
| ai, j = ai, j – W × ak, j | |||||
| до m-1 | |||||
| bi = bi – W× b k | |||||
| до m-1 | |||||
| до m-2 | |||||
| W=1 | |||||
| для i от 0 | |||||
| W = W× ai, i | |||||
| до m-1 | |||||
да | нет | ||||
| для i от m-1 | |||||
| s=0 | |||||
| для j от i | |||||
| s=s+ ai, j ×a j | |||||
| до m-1 | |||||
| a i = (b i – s) / ai, i | |||||
| до 0 | |||||
| Вывод a{ai}0… m-1 | |||||
Рисунок 1.4 Структурограмма метода Гаусса
Запись вида b{bi = 0}0… m-1 подразумевает вектор (или одномерный массив), заполненный при передаче нулевыми значениями. Снизу справа определяется индексация элементов в массиве.
Структурограммы легко переводятся на процедурные языки программирования и также легко читаются.
Программирование
Ниже представлены листинги первой и второй программы. Файл с исходным кодом первой программы называется «dots_creator.cpp», а файл с исходным кодом второй – «approximation.cpp».
// file “dots_creator.cpp”
//------------------------------------------------------
#include <vcl.h>
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
#pragma hdrstop
// global variables
double disp;
// prototypes
double func(double x,int flag);
double nois(double sigma);
// functions
double func(double x, int flag)
{
double w;
int i;
w=x*x;
w=w+w*x+1/x+log10(x);
if(flag)
w+=nois(disp);
return w;
}
double nois(double sigma)
{
double s;
int j;
s=0.;
for(j=0;j<12;j++) s+=rand()/(double)RAND_MAX;
s-=6;
s*=sqrt(sigma);
return s;
}
//------------------------------------------------------
#pragma argsused
int main(int argc, char* argv[])
{
FILE *fp;
double x,step,fnc;
int anr, dots,stime;
char cmd[2];
long ltime;
printf("f(x)=1/x+log10(x)+x^2+x^3\n");
printf("This function will be solved on interval from 0.1 to 1\n");
printf("How many dots do you need?: ");
while(1)
{
scanf("%d",&dots);
if(dots>0)
break;
printf("It must be a positive number. Try again: ");
}
printf("With nois? (y/n): ");
scanf("%s",cmd);
if(cmd[0]=='n' || cmd[0]=='N')
anr=0;
else
{
anr=1;
printf("Input a value of the dispersion: ");
scanf("%lf",&disp);
}
if((fp=fopen("dots.txt","wt"))==NULL)
{
printf("Failure: creating of the file was abortive\n");
return -1;
}
ltime=time(NULL);
stime=(unsigned) ltime/2;
srand(stime);
step=(1.-0.1)/dots;
fprintf(fp,"%d\n",dots);
for(x=0.1; x<1.; x+=step)
fprintf(fp,"%.16e %.16e\n", x, func(x,anr));
fclose(fp);
return 0;
}
//------------------------------------------------------
// file “approximation.cpp”
//------------------------------------------------------
#include <vcl.h>
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <conio.h>
#include <alloc.h>
#pragma hdrstop
// global variables
int flag=0;
// prototypes
double **mrx_crt(int m, int n);
void mrx_del(double **mrx_tmp,int m);
void refresh(double **tmpmas,int m,int n);
int approx(double **tmpmas,int m,double **vecA,double **vecB);
double func(double x,int num);
void outmrx(double **tmp_mrx, int m, int n);
// functions
double func(double x,int num)
{
switch(num)
{
case 0: if(x!=0.)
return 1/x;
else
flag=1;
break;
case 1: return log10(x);
case 2: return x*x;
case 3: return x*x*x;
default: break;
}
return 0.;
}
int approx(double **tmpmas,int m,double **vecA,double **vecB)
{
int i,j,k;
double W,s;
for(k=0;k<m-1;k++)
{
for(i=k+1;i<m;i++)
{
W=tmpmas[i][k]/tmpmas[k][k];
for(j=k;j<m;j++)
tmpmas[i][j] -= W*tmpmas[k][j];
vecB[i][0] -= W*vecB[k][0];
}
}
W=1.;
for(i=0;i<m;i++)
W*=tmpmas[i][i];
W=floor(fabs(W));
if(W==0.)
return 1;
for(i=m-1;i>=0;i--)
{
s=0;
for(j=i;j<m;j++)
s += tmpmas[i][j]*vecA[j][0];
vecA[i][0]=(vecB[i][0]-s)/tmpmas[i][i];
}
return 0;
}
void refresh(double **tmpmas,int m,int n)
{
int i,j;
for(i=0;i<m;i++)
for(j=0;j<n;j++)
tmpmas[i][j]=0.;
}
double **mrx_crt(int m, int n)
{
double **mrx_tmp;
int i,j;
mrx_tmp=(double **)farmalloc(m*sizeof(double *));
if(mrx_tmp!=NULL)
{
for(i=0;i<m;i++)
{
mrx_tmp[i]=(double *)farmalloc(n*sizeof(double));
if(mrx_tmp[i]==NULL)
{
for(j=i-1;j>=0;j--)
farfree(mrx_tmp[j]);
farfree(mrx_tmp);
mrx_tmp=NULL;
break;
}
}
}
return(mrx_tmp);
}
void mrx_del(double **mrx_tmp, int m)
{
int i;
if(mrx_tmp!=NULL)
{
for(i=0;i<m;i++)
if(mrx_tmp[i]!=NULL)
farfree(mrx_tmp[i]);
farfree(mrx_tmp);
}
}
void outmrx(double **tmp_mrx, int m, int n)
{
int i,j;
for(i=0;i<m;i++)
{
for(j=0;j<n;j++)
{
printf("%18.16lf",tmp_mrx[i][j]);
}
printf("\n");
}
}
//------------------------------------------------------
#pragma argsused
int main(int argc, char* argv[])
{
FILE *fp;
double **buff=NULL;
double **vecA=NULL, **vecB=NULL;
double arg, fcn,sum=0.;
int m=4,k,j,dots,shift;
if((buff=mrx_crt(m,m))==NULL)
{
printf("Program failure\n");
getch();
return -1;
}
if((vecA=mrx_crt(m,1))==NULL)
{
mrx_del(buff,m);
printf("Program failure\n");
getch();
return -1;
}
refresh(vecA,m,1);
if((vecB=mrx_crt(m,1))==NULL)
{
mrx_del(buff,m);
mrx_del(vecA,m);
printf("Program failure\n");
getch();
return -1;
}
refresh(vecB,m,1);
refresh(buff,m,m);
if((fp=fopen("dots.txt","rt"))==NULL)
{
mrx_del(buff,m);
mrx_del(vecA,m);
mrx_del(vecB,m);
printf("Not found the process file\n");
getch();
return -1;
}
fseek(fp,0L,SEEK_SET);
fscanf(fp,"%d",&dots);
while(feof(fp)==0)
{
fscanf(fp,"%lf%lf",&arg,&fcn);
for(k=0;k<m;k++)
{
for(j=k;j<m;j++)
{
buff[k][j]+=func(arg,k)*func(arg,j);
if(k!=j)
buff[j][k]=buff[k][j];
}
if(flag)
break;
vecB[k][0]+=func(arg,k)*fcn;
}
if(flag)
break;
}
fclose(fp);
if(flag)
printf("Happened breakpoint: problems with computing of the function\n");
else
{
if(approx(buff,m,vecA,vecB))
{
printf("Happened breakpoint: may be too little dots or Gauss method is inapplicable for this function\n");
printf("Your sample is %d dots\n",dots);
}
else
{
printf("Sample: %d dots\n",dots);
printf("Ratios:\n");
outmrx(vecA,m,1);
}
}
mrx_del(buff,m);
mrx_del(vecA,m);
mrx_del(vecB,m);
getch();
return 0;
}
//------------------------------------------------------
Первая программа построена на следующих «самостоятельных» функциях (не считая функцию main):
- Функция double func(double x,int flag);
- Функция double nois(double sigma).
Функция func возвращает значение функции (1.1). В качестве параметров функции нужно передавать значение аргумента и параметр flag, указывающий о необходимости зашумления значения возвращаемого результата. Зашумление будет происходить, если flag будет иметь ненулевое значение. Так как диапазон аргументов фиксирован, то в теле функции не предусмотрен возврат ошибок, связанных с вычислением значений функции.
Функция nois возвращает нормальную случайную величину с дисперсией, задаваемой sigma. Генерация случайного числа происходит с помощью генератора псевдослучайных чисел rand(), который возвращает числа с равномерным распределением. Исходное число, которое функция rand() использует для генерации последовательности, устанавливается один раз в теле main() с помощью функции srand(), которая использует для этого системное время.
В первой программе предусмотрено ветвление алгоритма рисунка 1.1, когда пользователь может решать зашумлять результат или нет. Для этого пользователь должен вводить по запросу латинскую букву y или n. Для простоты, в программе идет слежение только на отрицательный ответ, поэтому фактически для утвердительного ответа пользователь может использовать любой символ, кроме ‘ n ’ и ‘ N ’. Также предусмотрена простая защита на ввод отрицательного числа точек: если пользователь вводит отрицательное или нулевое число, то программа запросит число точек снова.
Так же в программе есть строка, не предусмотренная алгоритмом. Первым значением в файл записывается число точек, введенное пользователем. Так как это число ни на что не влияет в дальнейшем, то его можно считать дополнительным бонусом. Присутствие этого числа предусмотрено во второй программе.
При удачном завершении программы, она закрывается и в каталоге с программой должен появиться файл «dots.txt». При неудачном завершении, не связанным с созданием файла, файл тоже должен появиться. При этом он может быть пуст или в нём может быть только значение числа точек. Ошибка, связанная с созданием файла, перехватывается. Функция main возвращает 0 при удачном завершении и -1 при всех перехватываемых ошибках.
Вторая программа построена на следующих «самостоятельных» функциях:
- double **mrx_crt(int m, int n);
- void mrx_del(double **mrx_tmp,int m);
- void refresh(double **tmpmas,int m,int n);
- int approx(double **tmpmas,int m,double **vecA,double **vecB);
- double func(double x,int num);
- void outmrx(double **tmp_mrx, int m, int n).
Хотя по заданию размеры всех массивов предопределены и фиксированы, в данной реализации работа с массивами несколько унифицирована.
Функция mrx_crt возвращает указатель на двумерный массив размером m на n. Подразумевается, что функция вызывается корректно и параметры функции – натуральные числа. Функция выделяет память под массив в глобальной динамической памяти. В случае неудачи возвращает нулевой указатель NULL.
Функция mrx_del освобождает динамическую память, выделенную функцией mrx_crt. Функции необходимо передавать указатель на двумерный массив и количество строк этого массива. Подразумевается, что функция вызывается корректно и в её параметрах действительно указатель на двумерный массив с натуральным и реальным числом указателей на строки.
Функция refresh обнуляет все значения двумерного массива размером m на n. Подразумевается, что функция вызывается корректно и в её параметрах действительно указатель на двумерный массив с реальным размером. Функция не перехватывает ошибку, когда ей передают нулевой указатель. Необходимость данной функции обусловлена строкой «Ввод» в приведенных выше структурограммах.
Функция approx выполняет поиск параметров эмпирической формулы. Функции необходимо передавать указатель на двумерный массив формулы (1.5), количество строк массива и указатели на два вектора – vecA и vecB. Двумерный массив и свободный вектор должны быть подготовлены перед передачей согласно алгоритму рисунка 1.3. Вектор vecA специально может быть не подготовлен; именно в него запишутся параметры эмпирической формулы. Подразумевается, что функция вызывается корректно и указатели действительно на существующие массивы реального размера, так как такие ошибки не перехватываются. Данная функция целиком соответствует структурограмме рисунка 1.4. В случае удачи функция возвращает 0, а в vecA хранится результат, в противном случае функция возвращает -1. В любом случае следует помнить, что после вызова однозначно меняется структура передаваемого двумерного массива и свободного вектора.
Функция func соответствует эмпирической формуле (1.1). Функции нужно передавать аргумент и номер субфункции из (1.3). Можно передавать номера от 0 до 3, в противном случае func возвращает 0. Внутри предусмотрен перехват ошибки деления на ноль, при возникновении которой глобальная переменная flag принимает значение 1.
Функция outmrx выполняет вывод двумерного массива размером m на n. Функции передается указатель на массив и его реальные размеры. Подразумевается, что функция вызывается корректно и в неё действительно передаётся реальный указатель на массив и его реальные размеры.
Для простоты, во второй программе не предусмотрен «отлов» ошибки, когда файл пуст или в нем единственная строка. Ситуация, когда файла нет, перехватывается и выводится соответствующее сообщение. Алгоритм рисунка 1.3 выполняется внутри функции main. Функция main возвращает 0 в случае удачи и -1 при всех перехватываемых ошибках. В случае удачи на экран будут выведены параметры эмпирической формулы. Вектора в данной реализации создаются как двумерные массивы.
Анализ результатов
Для начала создадим файл с пятьюдесятью точками без зашумления. На рисунке 1.5 показана работа программы.
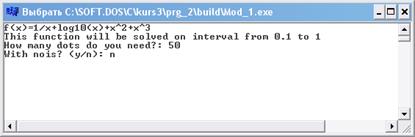
Рисунок 1.5 Создаём 50 точек без шума
Файл с точками будет иметь вид, показанный на рисунке 1.6.

Рисунок 1.6 Файл с точками
Теперь запускаем вторую программу. Так как выборка незашумленная, а эмпирическая формула совпадает с законом, по которому эта выборка получена, то параметры эмпирической формулы должны быть равны 1. На рисунке 1.7 видно, что это с достаточной точностью так.
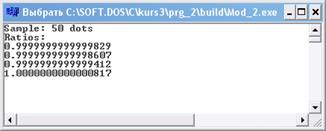
Рисунок 1.7 Результат работы второй программы
Теперь будем зашумлять результат. В таблице 1 приведены результаты работы второй программы при различных дисперсиях шума. На рисунках 1.9, 1.10 и 1.11 показаны формы эмпирических формул. Для наглядности они показаны вместе с графиком функции (1.1). Так как выборка случайна, то параметры будут меняться от запуска к запуску.
Таблица 1
| Значение дисперсии | Объем выборки | Значения параметров эмпирической формулы |
| 0,05 | 0,9522 | |
| 0,6394 | ||
| 0,6479 | ||
| 1,4488 | ||
| 0,1 | 1,1237 | |
| 1,8473 | ||
| 1,1806 | ||
| 0,6560 | ||
| 0,5 | 1,3681 | |
| 4,5206 | ||
| 5,6668 | ||
| -4,9306 |
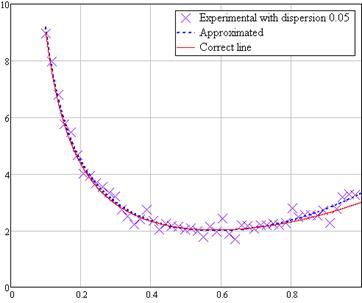
Рисунок 1.9 Аппроксимация случайной выборки с дисперсией 0,05
На графиках хорошо видно, что наиболее удачно аппроксимация прошла при дисперсии 0,1. В других случаях большое отклонение объясняется малым объемом выборки.
Продемонстрируем случай, когда аппроксимация не произойдет. Для этого попробуем обработать выборку из шести точек. Результат работы второй программы показан на рисунке 1.12.
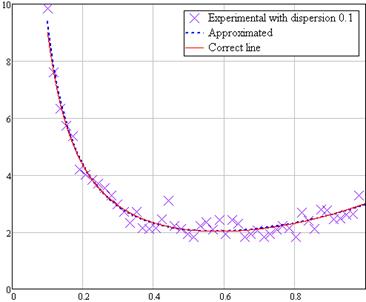
Рисунок 1.10 Аппроксимация случайной выборки с дисперсией 0,1

Рисунок 1.11 Аппроксимация случайной выборки с дисперсией 0,5
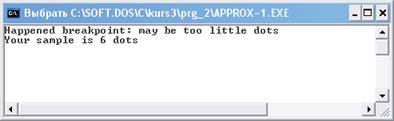
Рисунок 1.12 Аварийный останов при выполнении прямого хода
Дата добавления: 2015-12-17; просмотров: 22; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!