Дополнительно про язык Python
Язык программирования Python. Основы.
Цель - систематизация знаний для закрепления, консервации и лучшего понимания. А также отбрасывание всего этого. Предполагается уже наличие знакомства с программированием. Для читателей, не знакомых с программированием, можно обратиться, например, к уже написанным моим пособиям - по с++ или pascal abc. Здесь я не буду отвлекаться на мелочи - только краткая выжимка.
1-5 июня 2018, Казань
Автор: Кисмур Мусин
* Многие материалы могут быть копированы и отредактированы с других источников, в частности с некоторых интернет-сайтов. Здесь в основном лишь проводится систематизация и собирания самого важного и интересного на начальном этапе в одну кучу.
________________________________________________________________________
Среда программирования и суть языка
Есть несколько способов писать программы на питоне, мы остановимся на одном из них: будем использовать среду IDLE. С помощью неё мы сможем компилировать наш код на питоне в код, который может быть исполнен вычислительной машиной.
Данную среду можно скачать здесь по ссылке у меня:
https://yadi.sk/d/WEVPDaXb3WpNdm
Устанавливаем как обычную программу, оставляя всё по умолчанию. У тебя установится сразу и компилятор, и среда IDLE. В этой среде мы будем учиться писать программы.
После установки среду IDLE можно найти по следующему пути на компьютере:
C:\Users\Муся Мусс\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Python 3.6
|
|
|
Где вместо "Муся Мусс" у тебя имя пользователя твоего компьютера. Папка Appdata или Roaming обычно скрыта - нужно в настройках компьютера (в зависимости от версии виндовса это может быть по-разному - загугли) разрешить видеть скрытые папки на компьютере.
Далее скопируй оттуда ярлык IDLE и вытащи его на рабочий стол, чтобы было удобно. У меня этот файл называется IDLE (Python 3.6 32-bit). Остальные файлы можешь пока не трогать.
Вообще же питон можно легко и бесплатно скачать на их официальном сайте:
https://www.python.org
Скачивать тут:
https://www.python.org/downloads/
Ты можешь скачать там самую последнюю версию и выбрать свою операционную систему - есть не только для виндовса, но и для линукса, мака и т.п. У меня по ссылке выше версия 3.6.2 и я буду компилировать и проверять всё на её примере. Но для новичка разница между версиями всё равно будет непонятна и незаметна - поэтому можно изучить этот вопрос позже, когда ты освоишь основы питона. В данном случае мы изучаем python 3.
* Особые отличия имеют лишь питоны версий 2 (с двойки) и 3. Некоторые предпочитают писать на старой версии питона по своим причинам. На том же официальном сайте можно скачать питон версии 2.7. На момент 1 июня 2018 самые последние версии это 2.7.15 и 3.6.5.
|
|
|
Python (питон, пайтон) - высокоуровневый язык программирования. Является одним из самых распространённых и востребованных в мире на 2018-й год - на его примере как раз можно и высокоуровневый язык рассмотреть. О его сфере применения ниже.
Особенности высокоуровневого языка в том, что в нём меньше возможностей, мы можем делать лишь какие-то поверхностные вещи. Не можем работать с памятью, например - как в с++ или чистом си, тут нет указателей и подобного дерьма. Также высокоуровневые языки медленнее низкоуровневых. Но это о минусах. В чём же плюсы? В том что они проще и для пережившего низкоуровневые языки, многое покажется халявой и радостью, типа на царских таких правах. Здесь нужно писать меньше кода, можно программировать быстрее и проще. Главной особенностью является динамическая типизация, т.е. тут переменная не имеет чётко закреплённого типа данных - ты просто пишешь например х=5 и компилятор автоматически определяет что ты создал целое число. Можно легко переходить между типами данными встроенными функциями. Также гораздо проще и быстрее работа с массивами. Впрочем, о тонкостях дальше.
Высокоуровневые языки используются там, где нам не так важна скорость работы программы, но зато важна скорость разработки - насколько быстро мы пишем программы. На таких языках пишут обычно что-то поверхностное и прикладное - где не надо лезть в работу запчастей компьютера, памяти и всё такое. И где не нужна высокая производительность.
|
|
|
Популярные сферы использования питона:
- веб программирование (сайты и интернет сервисы, чат боты, обмен данными и т.п)
- машинное обучение, нейронные сети, искусственный интеллект
- визуальные новеллы (движок RenPy) и подобные картинистые игры - где мало движений и взаимодействий каких-то - но зато быстрее можно написать (просто скрипты команды по сути простые и чтобы ничего лишнего как в си-подобных языках)
- для обучения программирования на самом простом уровне для школьников каких-то тоже сойдёт, чтобы просто увлечься темой (питон легче выучить чем например с++, более доступен)
Всё, что связано с интернетом, сетевыми (веб) технологиями - там обычно простые скриптовые высокоуровневые языки, в том числе и питон. Из высокоуровневых это наверное самый популярный и интересный, поэтому тут мы именно им и займёмся. Низкоуровневые используют для разработки игр, где нужно много движений, взаимодействий персонажей. Или для операционных систем. Это уже си-подобные языки. Обычно это связано не с интернетом, а просто работа с самим компьютером, памятью и т.п. или, как говорят - работа с железом.
|
|
|
Ещё одной особенностью является что в более низкоуровневых языках типа с++ (со статической типизацией) очень легко ошибиться и потом где-то получить ошибку - или, как говорят - выстрелить себе в ногу. Например, выйти за границы массива или перегрузить оперативную память и заставить компьютер зависнуть. В питоне и подобных языках все подобные вещи блокируются, тут труднее сделать что-то против памяти. Всё как бы зашито под чёрным ящиком и ты не можешь туда залезть. Чёрный ящик - это как раз язык си или нечто подобное. Но тебе лезть туда уже не нужно - ты спокойно орудуешь лишь с поверхностными высокоуровневыми инструментами. Это как ты водишь машину и тебе необязательно знать что творится под капотом. Просто осваиваешь элементарные навыки вождения, правила дорожного движения и т.п - это как раз питон. А быть механиком, крутить гайки - это примерно уровень языка си и ему подобных, здесь от тебя это не требуется, это уже разные специализации.
Переходить с с++ на питон очень легко, а вот обратно (если ты знаешь только питон и хочешь теперь выучить с++) гораздо сложнее, многое может смутить. Например, статическая типизация, трудности работы с массивами и т.п. Язык с++ хоть уже и не высокоуровневый, но при этом и достаточно не низкоуровневый - что-то посередине. В более низкоуровневых типа чистого си гораздо больше заморочек, поэтому лучше именно с++ сначала учить, а не си. Тем более что когда ты перейдёшь к объектно-ориентированному программированию, с си всё равно придётся перейти на с++ (т.к. в чистом си нет ООП, это с++ как раз служило такой модернизацией). На примере с++ ты можешь изучить все основные концепции программирования и дальше легко и с радостью, с интересом переходить на любой другой язык - как ниже уровнем, так и выше. А в питоне ты изучишь лишь половину концепций, а вторая половина останется под капотом и чёрным ящиком, её ты пропустишь - но эта вторая половина пригодится при работе с более низкоуровневыми языками. В питоне и ему подобных ты можешь быть сильно избалован высокоуровневостью и от этого понимать многие программируемые вещи лишь очень поверхностно. Поэтому желательно сначала учить именно с++, а потом например питон. Но если тебе плохо даётся программирование, логика, с математикой тоже особо никогда не дружил - можно начинать из питона, это такой простой и доступный вариант практически для всех. Чтобы хотя бы что-то изучить, основы какие-то в программировании. А потом перейти на что-то более сложное (если на то будет желание), чтобы доучить незатронутые концепции типа организации памяти, ссылочных типов данных, более глубокий переход на типы данных и т.п. Чтобы в случае чего, имея лишь простые средства, ты мог написать нужные тебе высокоуровневые функции (которые в питоне уже встроены как естественные) и использовать их где тебе нужно.
Теперь коротко о статической и динамической типизации - потому что это наверное самое главное и ключевое отличие - и чтобы далее ты понимал как на питоне это использовать. Статическая типизация (в с++ и pascal abc например) при создании переменной (ячейки памяти) ты обязательно должен указывать тип данных, который будет в этой ячейке храниться - целое число (int, integer), вещественное (float, double), символ (char, character), строка (string), логическая переменная (bool, boolean) или что-то другое. В динамической типизации тип данных указывать не нужно - он определяется автоматически. Но чтобы не было ошибок и путаниц, нужно быть внимательным - не нужно например складывать число и строку или что-то подобное. Поэтому всегда держи в голове и понимании, какого типа данных используемые твои переменные - этот тип данных не пишется, но ты должен понимать его - он подразумевается, скажем так.
Также в динамической типизации ты можешь легко объединять разные типы данных в одно. Например, массив тут может содержать и числа, и строки, и даже подмассивы - это не важно. Полиморфизм тут встроен в язык естественным путём, ты легко можешь в цикле перечислять разные типы данных. В статической типизации в массивы заносятся только данные одного типа, для разных типов заводят структуры или классы, а с полиморфизмом тут всё гораздо куда сложнее.
Также в динамической типизации массив тоже является типом данных и ты легко можешь выводить их (массивы), складывать и т.п. обычными функциями или арифметическими действиями.
Ну и ещё в динамической типизации тут в питоне у нас строка и символ одно и тоже (нет разделения на char и string), поэтому ты спокойно можешь проводить между ними взаимные операции. И строка тут тоже является массивом символов (строк из 1 символа по сути)
А теперь приступаем к основам питона.
________________________________________________________________________
Ввод и вывод данных
В питоне для ввода и вывода данных не нужны заголовочные файлы, начало-конец, главные функции и прочее добро - мы просто может спокойно написать функцию вывода. Просто программа будет состоять из одной строки, в которой мы пишем:
print("Привет")
Функция print выводит текст. Текст заключается в двойные кавычки. Точка запятой в конце НЕ ставится. Новое действие мы пишем обязательно на новой строке. Конец действия у нас тут помечается не точкой с запятой, а именно переходом на новую строку. Точку запятой можно, однако, использовать, для разделений нескольких действий на одной строке - но это не рекомендуется.
Данная простая программа выведет слово "Привет" (без кавычек) на экран в консоли. Теперь давайте научимся компилировать или интерпретировать и получать результат. Нужно запустить этот вытащенный на рабочий стол файл IDLE. У тебя сразу откроется окно с такими надписями:
Python 3.6.2 (v3.6.2:5fd33b5, Jul 8 2017, 04:14:34) [MSC v.1900 32 bit (Intel)] on win32
Type "copyright", "credits" or "license()" for more information.
>>>
Можно уже сразу писать программу, вот прям где этот курсор-каретка стоит, ничего создавать не надо. Это просто интерпретатор - но тут можно написать только одну строку и нажать ENTER, тебе сразу выйдет результат. Подходит для быстрых и коротких арифметических действий.
Чтобы же писать полноценные многострочные программы, делаем следующее:
1. Создаём новый файл: file -> new file (создастся файл с именем untitled)
2. Пишем там программу (предыдущее окно, кстати, можно уже закрыть)
3. Сохраняем файл: file -> save as (или run -> run module F5 -> OK to save)
4. Пишем имя файла, подтверждаем сохранение (сначала можно выбрать папку куда сохранять - на рабочий стол например)
5. Если уже нажимал run module и только потом сохранял, то программа запустится в новом окне интерпретатора. Иначе надо нажать run module или просто F5.
На рабочем столе (или куда ты там сохранял) появится файл с расширением .py - на него можно нажать и откроется консольное окно, где уже выведется и быстро вылетит.
*
Можно выводить несколько строк подряд, например:
print("Первая строка")
print("Вторая строка")
и т.д.
Русские символы тоже перевариваются, проблем с этим не возникает. Переход на новую строку автоматически происходит при функции print(). Но можно сделать переход строки в самом тексте специальной командой \n (она идёт как обычный текст). Например:
print("первая строка\nвторая строка")
Или можно использовать пропуск строки при выводе просто оставив так:
print("\n")
* Для знакомых с java или pascal - в питоне println() не работает, нет такой функции!
Теперь как вводить данные. Для этого есть функция input(). Тип переменной, напомню, вводить не надо - по умолчанию у тебя создастся строка.
Например, сделаем так:
s= input()
Всё, ты запросил ввод строки, которая будет сохраняться в ячейку памяти, которую ты назвал s. Можно ввести именно число - для этого сразу после ввода нужно перевести в вещественный формат, например так:
a= float(input())
И у тебя будет переменная с именем a, где хранится вещественное число. Они тут пишутся типом float. Типа double в питоне НЕТ! Целочисленный тип указывается как int, например a= int(input())
Вот пример программы, где мы вводим целое число, а выводим его удвоенное значение:
a= int(input())
print(2*a)
Чтобы консоль после выполнения программы в конце не вылетала, можно в последней строчке программы запросить ввод переменной, используя это вместо паузы. Например, написать s=input(). Ты что-нибудь введёшь, нажмёшь ENTER и консоль теперь уже только тогда закроется.
Объявлять числа и строки с начальным значением просто например так:
a= 5 (целое)
a= 5.0 (вещественное)
a= "муська" (строка)
Для пустой строки можем использовать:
s=""
Также можно объявлять логические переменные:
a= True
b= False
Или вот так делать:
a= 5
c= a<0 (т.к. a=5, 5<0 это ложь - поэтому в значение переменной [с] попадёт ложь, т.е. False)
Если мы напишем print(c), то выведет False
Напоследок отметим, что регистр тут важен. Если написать Print("текст"), то выйдет ошибка. Нужно обязательно маленькими буквами писать print. И с именами переменных то же самое.
* Вот пример данной ошибки:
Traceback (most recent call last):
File "C:/Users/Муся Мусс/Desktop/test.py", line 1, in <module>
Print("киса")
NameError: name 'Print' is not defined
* В консоли выведет то же самое, т.е. текст ошибки.
Если в качестве текста мы хотим вывести кавычки, то вместо " пишем \" (аналогично и с другими проблемными символами)
В программе можно оставлять пустые строки, это ни на что не влияет - просто делает код более читабельным и наглядным.
Для комментирования используем символ #, а далее сам текст. Комментируемый текст никак не влияет на работу программы и нужен для программистов, чтобы они понимали что в данном участке кода находится - потому что спустя время даже свой код бывает трудно разобрать, ибо забываешь что, где, как и почему. Поэтому комментирование стоит использовать. Ну и для командного программирования тоже - если одну программу редактирует несколько человек - в комментариях пишутся пояснения друг для друга.
Стандартное комментирование из двух слэшей (//) как в с++ или паскале тут не работает! Выдаст ошибку. Также многострочное из си-подобных типа /* */ тоже в питоне не работает.
Строку можно выводить не только в двойных кавычках, но и в одинарных - разницы никакой не замечено.
________________________________________________________________________
Арифметика чисел и строк
Арифметика тут стандартная:
a + b (сложение)
a - b (вычитание)
a * b (умножение)
a / b (деление)
Но вот тут особенности:
a // b (целочисленное деление - т.е. с обрезанием дробной части в результате)
a % b (остаток)
a ** b (степень)
Примеры:
19:5= 3.8 или 3 целых, 4 в остатке. Поэтому в питоне будет:
19/5= 3.8
19//5= 3
19%5= 4
Со степенью:
2 ** 5 = 32, т.к. 2*2*2*2*2 (5 двоек перемножается) = 32 или иначе 2^5= 32
Пример программы, которая меняет местами 2 числа без создания 3-й переменной:
x1= float(input()) # например 5 ввели
x2= float(input()) # например 7
x1= x1 + x2 # x1=12, x2=7
x2= x1 - x2 # x1=12, x2= 5
x1= x1 - x2 # х1=7, х2= 5 (всё, поменяли местами)
Теперь строки. Их можно складывать и тогда строки таким образом совмещаются или, иначе говоря, происходит конкатенация.
s1= "stroka"
s2= "244"
print(s1+s2) # выведет stroka244
Умножение на натуральное число (скаляр) копирует строку нужное количество раз. Например:
s= "строка"
print(3*s) # будет строкастрокастрока
Перевод строки s в число t:
t= int(s)
# если s состоит из цифр
Перевод числа t в строку s:
s= str(t)
Узнать длину строки s:
L= len(s)
# длина строки - это количество символов в строке
Строку можно использовать как массив символов. Например, есть строка s= "муська". Тогда по буквам будет s[0]= "м", s[1]= "у" и т.д. Ниже программа, где мы вводим строку, заменяем в ней первую букву на А и выводим только 1-ю и 5-ю букву через пробел. Нумерация в массивах начинается с нуля.
s= input()
s[0]= "А"
print(s[0] + " " + s[4])
Можно выводить и длинные кусочки слов, а не только одну букву, например:
print(s[3:6]) # выведет с 3-й (по нумерации массивов, т.е. с 4-й) включительно по 6-ю (7-ю фактически) невключительно.
Вывести только со 2-й буквы (по нумерации массивов) до конца:
print(s[2:])
# фактически, первые 2 буквы не выводим тут, а далее выводим
Вывести только до 4-й буквы (фактически) включительно:
print(s[:4])
А вот тут более продвинутая строковая арифметика. Мы из слова выделяем только первые 3 буквы и последние 3, а далее удваиваем этот кусок и заносим вместо старого слова.
s= 2 * (s[:3] + s[(len(s)-3):])
Пример: было КОШКАГУЛЯЕТ, стало КОШЯЕТКОШЯЕТ
// Можно сравнить тут, насколько гораздо более громоздко это бы было в с++ (если не прописать заранее упрощающие строковые функции)
int stringsize= 0;
while(s[stringsize]!='\0') stringsize++; // определяем сколько символов в строке
string a= ""; // заводим промежуточную строку
for(int i=0; i<3; i++) a+= s[i] // первые 3 символа
for(int i= (stringsize-3); i<stringsize; i++) a+= s[i] // последние 3 символа
s= a + a; // удвоение
На этом примере видна разница между среднеуровневым языком (с++) и высокоуровневым (питон). Неплохая мотивация изучать питон дальше, согласись. В среднеуровневых языках типа с++ можно прописать упрощающие функции заранее, конечно - но в питоне все эти упрощения уже встроены на автомате, от программиста не требуется никаких предварительных телодвижений, он уже на всём готовеньком.
Арифметика у нас производится только с данными одного типа, поэтому если ты хочешь добавить к строке s некое число x и использовать это как строку, то нужно сначала число х перевести в строку и далее можно складывать. Как например ниже:
s= s + str(x)
Или можно сократить это: s+= str(x) - т.е. мы к строке s приплюсовываем str(x)
Теперь сравнения - они стандартные как в математике:
> больше
>= больше или равно
< меньше
<= меньше или равно
== равно (не путать с присваиванием!)
!= не равно
Строки являются неизменяемым видом данных, т.е. мы не можем для строки s написать что-то типа s[1]='м' чтобы изменить её вторую букву. Для замены используется метод replace. Например:
s= 'муся'
s.replace('м','у')
print(s) # выведет 'ууся'
Метод strip() обрезает пробелы в строке в её начале и в конце. Пример:
s= ' кис '
s.strip() - будет строка 'кис'
________________________________________________________________________
Условия
Теперь посмотрим, как сделать типа при одном условии выполняется это, а при другом нечто другое. Например, рассмотрим решение квадратного уравнения - на его примере всё достаточно наглядно.
Напомню, как решать квур. Пусть дано a*x*x + b*x + c = 0, где a,b,c - известные нам числа (вещественные, т.е. типа float), а x- неизвестное. Результат зависит от выражения b*b - 4*a*c, которое мы назовём дискриминантом и обозначим отдельной переменной discr. Если дискриминант меньше нуля, то выведем текст что вещественных корней нет. Если равен нулю, то выведем 1 корень. Если больше нуля, то 2 корня. Только уже сами корни выводим, а не текст.
Сначала вводим коэффициенты:
a= float(input())
Аналогично b,c. Далее считаем дискриминант:
d= b*b - 4*a*c
Теперь вот условия. Они записываются так:
if d<0 :
print("Вещественных корней нет")
else :
print("Корни есть")
Важные моменты:
1. Тут if - если, else - иначе. Есть также промежуточный оператор elif (т.е. else if), который мы встретим дальше.
2. После оператора условия пишется само условие, можно без скобок.
3. После условия обязательно двоеточие.
4. Далее что выполняется при нашем условии - чтобы программа это поняла, обязательно делается отступ (табуляция). Эта табуляция и показывает, где у нас открывается и закрывается условие. Таким образом программа выглядит очень наглядной. Табуляция тут обязательна.
5. Вместо табуляции может быть 4 пробела - и только именно так! Ну или табуляция должна именно 4 пробела делать, если пишешь код в каком-нибудь блокноте - это можно в настройках блокнота отрегулировать.
Теперь ниже я представлю всю программу полностью скриншотом как в IDLE выглядит для большего понимания, при этом добавим ещё условие чтобы уравнение считалось только если a не равно нулю (иначе ведь оно уже не квадратное), а также вывод комплексных чисел вместо сообщения "корней нет"
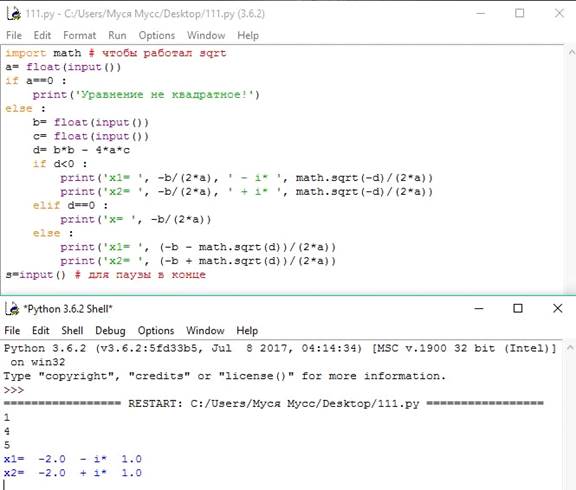
Теперь конкретнее некоторые возможно непонятные моменты:
1. Арифметический корень числа x выполняется функцией math.sqrt(x). Но чтобы эта функция работала, нужно в начале программы написать import math - таким образом мы подключаем математическую библиотеку, которая по умолчанию не встроена.
2. Чтобы вывести и строку и числа, эти разнородные элементы в функции print() разделяются запятой.
3. Комплексные числа - это когда ещё учитываем числа вида a + b*i, где a,b - вещественные числа, а символом i мы обозначаем корень из -1.
На этом простом примере можно понять как работают условия. Но это ещё не всё. Условия можно объединять логическими операциями И, ИЛИ. А также использовать отрицание НЕ. В питоне это пишется так:
И - and
ИЛИ - or
НЕ - not
Пример: if (a>=2 and a<=7). Кстати, в питоне возможны и двойные неравенства, т.е. это условие можно заменить на if (2 <= a <= 7)
Также в if или elif в качестве условия у нас может булевая (логическая переменная, принимающая истину или ложь), например:
a= int(input())
poz= a>0 # булевая
if poz :
делаем что-то там
else :
делаем что-то другое
Блок else необязательный, его может не быть. Когда закончили блок с if, отступ нужно прекратить - это покажет компилятору что блок с if закончился.
Ещё немного про булевые значения. Если число равно нулю, то его можно считать ложью, т.е. if (x) значит то же самое что if (x!=0), т.е. если х имеет какое-то ненулевое значение. Аналогично со строкой - пустая строка это ложь, непустая - истина.
*
Сокращающее условие. Конструкцию такого типа:
if x :
y= 2
else :
y= 3
Можно записать в более сжатом виде: y=2 if x else 3
________________________________________________________________________
Циклы
Переходим к циклам, а именно как писать когда одни и те же действия выполняются большое количество раз, при этом в этих действиях может меняться какая-то мелочь, зависимая от номера повторения (итерации)
Начнём с самого простого. Код ниже выведет строку "Привет" 5 раз подряд. Понятно, что вместо 5 может быть любое кол-во повторений.
for i in range(5) :
print("Привет")
Далее. Сосчитаем например сумму 1*1 + 2*2 + ... + 100*100. Это можно сделать с помощью специальной формулы, но предположим что мы её не знаем, да и далеко не для всех подобных сумм существуют удобные формулы.
1. Создаётся переменная накопитель, в данном случае sum= 0. К ней мы в цикле будем приплюсовывать сначала 1*1, затем 2*2 и т.д. Если бы мы не приплюсовывали, а домножали, то начинать нужно не с нуля, а с единицы.
2. В цикле происходит приплюсовывание.
3. Используем результат где нам нужно - например его можно вывести.
sum= 0
for i in range(101) :
sum+= i*i
print(sum)
Важный момент: range(100) - тут считаются числа от 0 до 99. Начинается с нуля. У функции range также есть перегрузка - если мы напишем range(20,50), то будут плюсоваться от 20 до 49 включительно, только этот промежуток.
Ещё один пример для закрепления - как сосчитать факториал. Например, факториал числа 5 равен 1*2*3*4*5= 120. Сосчитаем факториал некоего заданного числа n.
prod= 1
for i in range(2,n+1) :
prod*= i
print(prod)
Цикл for может использоваться и в пробегании по словам. Вспомним, что слово это массив символов. Сначала напишем как обычно - выведем первые 4 символа, написав каждый из них 2 раза. Например, было МУСЬКА, стало ММУУССЬЬ
s= input()
for i in range(4) :
print(2*s[i], end='')
Здесь через запятую новый аргумент функции print мы добавили, чтобы после каждого вывода не было перехода на новую строку, а продолжался вывод на той же строке. Тут именно две одинарные кавычки, а не одна двойная. Таким образом мы отмечаем, что концовка равна пустому символу. По умолчанию концовка равна переходу на новую строку или "\n"
Теперь запишем то же самое иначе. Вместо range() у нас будет сама строка, а вместо итератора будет буква. И символ удвоется уже каждый, на протяжении всего слова. Например, было Муська, стало ММууссььккаа. В предыдущем случае чтобы так было, нужно в написать range(len(s))
s= input()
for i in s :
print(2*i, end='')
Подобное пробегание по строкам используется в питоне часто, да и не только по строкам - с этим мы ещё встретимся в дальнейшем.
А что, если мы хотим например, чтобы у нас удваивался каждый второй символ? Тогда стоит использовать обычную универсальную запись. Пробег именно по строке удобно использовать, когда у нас задействованы все символы в нём.
s= input()
for i in range(len(s)) :
if i%2==1 :
print (s[i]*2,end='')
else :
print(s[i],end='')
Тут каждый второй символ мы организовали с помощью деления с остатком или иначе чётности и нечётности. Символы, которые нужно удлинять, имеют порядковые номера 1, 3, 5 и т.д. - все эти числа отличаются на 2 и при делении на 2 имеют остаток 1 (т.е. все эти числа нечётные) - это мы и использовали, чтобы их идентифицировать.
*
Теперь ещё про другой вид цикла - while (пока). Т.е. пока некое условие истинно, мы делаем что-то. Пример ниже:
i= 2
while i<100 :
i+=7; print(i)
Сначала i=2. Далее прибавляем 7 и выводим. Как только i<100 перестанет соблюдаться, т.е. i станет 100 или больше, то мы выйдем из цикла.
Также есть стандартные операторы выхода из цикла, которые и в си-подобных языках, и в паскале. Операторы break, continue. Первый выкидывает нас из внутреннего цикла, второй - пропускаем данную итерацию.
Например, будем складывать только 1+2+4+5+7+...+100, т.е. если число делится на 3, то мы его пропускаем. Иными словами, если остаток при делении на 3 равен нулю.
sum=0
for i in range(101) :
if not i%3 :
continue
else :
sum+= i
print(sum)
Теперь пример с оператором break. Предположим, у нас есть некое слово. Мы выводим буквы и если наткнёмся на букву П, то выйдем из цикла и перестанем выводить.
s= input()
for i in s :
if i=="п" :
break
else :
print(i,end='')
Что же касается известного спорного оператора goto, то в питоне его нет и прыжки на произвольные строки в коде тут не поддерживаются из-за высокоуровневости языка. Но оператор goto не является необходимым и всегда можно написать код без него, даже если он и будет выглядеть в некоторых случаях сложнее. Для замены прыжков можно использовать логические переменные-переключатели.
________________________________________________________________________
Массивы (списки)
В питоне вместо массивов в привычном понимании присутствуют списки. Это как массив, только вместо однотипных элементов мы можем хранить совсем разные, и даже массивы. Если в языках со статической типизацией типа с++ массив может состоять только из целых чисел или только из строк и т.п, то в питоне в один массив мы можем запихнуть и строки, и числа, и другие массивы, и вообще любые типы данных. Так как это уже не совсем массив получается, в питоне данный объединяющий тип данных называется списком.
Из интересного, что стоит отметить:
1. В списке могут храниться подсписки, в которых тоже в свою очередь подподсписки и т.п, т.е. функционал весьма гибок.
2. Со списком мы можем обращаться как с обычной переменной, например вывести её или использовать как аргумент функции, объединять с другим списком и т.п.
3. Перебор по элементам списка стандартный как в массиве.
4. Могут быть отрицательные элементы списка (массива) - например (-1)-й элемент равен последнему, (-2)-й предпоследнему и т.п.
5. Нумерация элементов начинается с нуля, как обычно.
6. Список заключается в квадратные скобки. Как раз эти скобки и дают понять о том, что речь идёт именно о списке, а не о каком-то другом типе данных.
Пример создания списка:
a= [5, "cat", ["murr", -1, 5.44], True]
Здесь у нас список из четырёх элементов: 5 (целое число), "cat" (текст), ["murr", -1, 5.44] (подсписок) и True (логическая переменная). Через a[0] обратимся к 1-му элемента (число 5), через a[1] ко второму и т.д.
Можно делать и так: a[2][1] - мы обратились ко 2-му элементу (начиная с нуля) нашего списка [a] - это подсписок. Далее в этом подсписке мы обращаемся к 1-му элементу (с нуля) - это будет число (-1). А если сделать так: a[2][0][1] - то это будет бувка u - по той же логике: 0-й элемент подсписка это слово и в нём выбираем 1-ю (с нуля) букву.
В списке у нас 4 элемента. Вместо a[3] мы можем писать a[-1], вместо a[2] - a[-2] и т.п. Но в общем случае циклическая группа остатков по модулю тут не действует - a[4] уже выдаст ошибку. Только от нуля либо в одну сторону пока элементы есть, либо в обратную сторону так же.
Можно переприсвоить, т.е. поменять какие-то элементы массива, например a[1]= 8 - и наш список теперь будет [5, 8, ["murr", -1, 5.44], True]
Вывести список: print(a). Выведется он так с квадратными скобками и элементами через запятую, как мы его и пишем тут.
Добавить новый элемент в список: a.append(новый элемент). Размер увеличится на 1, все старые элементы сохраняться. Примерно как к поезду прикрепили новый вагон на некой станции и он так же благополучно едет дальше.
Отсортированный список: sorted(a) - сортировка идёт по возрастанию. Сначала цифры от 0 до 9, затем заглавные буквы от A до Z, затем прописные буквы от a до z. Тут именно список будет, т.е. print(sorted(a)) можно вывести. Эту же функцию можно использовать со строкой.
Работает данная функция не со всеми данными, а с однотипными - только числами например, буквами и т.п. Если в одном списке и числа, и буквы, и списки, и логические переменные, и ещё невесть что, то сортировка может и не работать.
Функцию sorted можно использовать и для строк - идёт сортировка символов по возрастанию. Пример:
s= 'муся'
sorted(s)
Будет массив: ['м', 'с', 'у', 'я']
Для массивов, как и для строк, можно использовать метод find для поиска нужного элемента. Например, задан массив:
m= [1, 3, 2, 17, 6, 33]
print (m.find(3)] - выведет в какой позиции найден элемент 3. В данном случае это 1-й элемент (начинаем с нуля!), поэтому выведет 1.
Для строк аналогично. Можно искать не конкретный символ, а кусок строки.
Если элемент не найден, то выведет -1. Это можно использовать для создания условий - найден ли нужный элемент или нет. Если хотим искать с конца, то вместо find пишем rfind.
При поиске элемента у нас выводится первый найденный. Т.е. если в массиве несколько одинаковых элементов (на разных позициях), то при обычном find выведет самую левую позицию, а при rfind - самую правую.
Создать список символов из строки можно так:
>>> list('пример')
['п', 'р', 'и', 'м', 'е', 'р']
Вот ещё вариант:
>>> c = [i* 3 for i in 'пример']
>>> c
['ппп', 'ррр', 'иии', 'ммм', 'еее', 'ррр']
Удаление 2-го элемента
>>> c.pop(2)
>>> c
['ппп', 'ррр', 'ммм', 'еее', 'ррр']
Вставка нового элемента в нужное место:
>>> c
['ппп', 'ррр', 'ммм', 'еее', 'ррр']
>>> c.insert(3,'слово')
>>> c
['ппп', 'ррр', 'ммм', 'слово', 'еее', 'ррр']
Количество элементов со значением 'слово'
>>> c.count('слово')
1
Удаление элемента, но заданное не по его порядковому номеру, а по значению. Если элементов с таким значением несколько, то удаляется первый из них.
>>> c.remove('ммм')
>>> c
['ппп', 'ррр', 'слово', 'еее', 'ррр']
>>> c.remove('ррр')
>>> c
['ппп', 'слово', 'еее', 'ррр']
Разворачивание списка
>>> c.reverse()
>>> c
['ррр', 'еее', 'слово', 'ппп']
Ну и далее аналогично метод copy() создаёт копию списка, а метод clear() делает список пустым.
Расширение списка новым списком
>>> c.extend(c)
>>> c
['ррр', 'еее', 'слово', 'ппп', 'ррр', 'еее', 'слово', 'ппп']
Есть ещё неизменяемые списки, т.к. называемые кортежи - но про них в одной из дополнительных глав. Для создания кортежа вместо квадратных скобочек нужно использовать круглые.
________________________________________________________________________
Словари
Словари - это ещё один тип данных из нескольких объектов. Подобные типы называют контейнерами. Например, массивы, списки - это всё контейнеры. Словарь - это примерно как массив, только вместо порядкового номера элемента у нас так называемый ключ. Можно сказать, что массив - это тот же словарь, где ключами является последовательность натуральных чисел (0, 1, 2... и т.д.), начиная с нуля. В словаре ключами могут быть любые числа, а также строки или что-либо ещё.
Другое название словарей - ассоциативные массивы, хеш-таблицы. В с++ это например реализуется через map. Но в питоне с этим всё проще и понятнее.
Если списки у нас помечаются квадратными скобками, то словари - фигурными. Можно создать пустой список или пустой словарь двумя соответствующими скобками.
Пример создания словаря:
>>> sl= {
5 : 'муся',
7 : 'барсик',
11 : 'киса'
}
>>> sl
{5: 'муся', 7: 'барсик', 11: 'киса'}
Сначала мы создали словарь, затем его вывели - это всё простоты сразу проверяется и показывается в интерпретаторе. В самой же программе мы пишем print(sl). В данном примере ключами являются 5, 7, 11. То что в тексте - это содержимое. Можно обращаться к нему по индексам, где индексами являются наши ключи. Например, a[11] выдаст 'киса'.
По сути словарь - это некое расширение понятие массив, некое обобщение - где вместо обычных индексов 0, 1, 2 и т.д. мы можем задать любые. При этом индексами могут быть не только числа, но и строки.
>>> name= {
'short' : 'муся',
'full' : 'муся мусс'
}
>>> name
{'short': 'муся', 'full': 'муся мусс'}
При создании словаря можно каждую пару ключ-содержимое писать на новой строке для удобства, но не забывать о запятых. Потому что идёт перечисление. А можно всё писать на одной строке, если словарь короткий.
Другой способ создать тот же предыдущий словарь:
name= dict(short='муся', full='муся мусс')
Ещё пример:
>>> d= dict([(15, 'вася'), (24, 'тишка')])
>>> d
{15: 'вася', 24: 'тишка'}
И ещё способы создавать словари:
>>> d = dict.fromkeys(['a', 'b'])
>>> d
{'a': None, 'b': None}
// ключи создали, а содержимых пока нет
>>> d = dict.fromkeys(['a', 'b'], 100)
>>> d
{'a': 100, 'b': 100}
// содержимое 100 передаётся для всех ключей сразу
>>> d = {a: a ** 2 for a in range(7)}
>>> d
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36}
// словарь, где содержимое - это ключ в степени 2 (и так от 0 до 7 по функции range)
Возьмём наш последний словарь, заменим в нём d[4]= 55. Получим:
{0: 0, 1: 1, 2: 4, 3: 9, 4: 55, 5: 25, 6: 36}
Расширим словарь:
>>> len(d)
7
>>> d[7]= 10
>>> d
{0: 0, 1: 1, 2: 4, 3: 9, 4: 55, 5: 25, 6: 36, 7: 10}
Всего у нас в словаре 7 ассоциативных пар, где ключи от 0 до 6. Создали элемент с ключом 7 и получили расширенный словарь.
А можно и так:
>>> d['again']=22
>>> d
{0: 0, 1: 1, 2: 4, 3: 9, 4: 55, 5: 25, 6: 36, 7: 10, 'again': 22}
Методы для данного словаря:
d.clear() - очистить наш словарь d (сделать его пустым)
d.copy() - копия словаря
d.items() - возвращает пары (ключ, значение).
dict.keys() - возвращает ключи в словаре.
d.values() - возвращает значения в словаре.
Примеры с уже имеющимся словарём
>>> name.items()
dict_items([('short', 'муся'), ('full', 'муся мусс')])
>>> name.keys()
dict_keys(['short', 'full'])
>>> name.values()
dict_values(['муся', 'муся мусс'])
Удаление какой-либо ассоциативной пары из словаря:
>>> d = {a: a ** 2 for a in range(7)}
>>> d
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36}
>>> d.pop(2)
Станет: {0: 0, 1: 1, 3: 9, 4: 16, 5: 25, 6: 36}
В словарях тоже возможно многоуровневое обращение. Например, возьмём уже имеющийся словарь:
>>> name= {
'short' : 'муся',
'full' : 'муся мусс'
}
>>> name
{'short': 'муся', 'full': 'муся мусс'}
И если обратиться как name['full'][3], то получим 3-й элемент содержимого под ключом full, т.е. букву 'я'
Также можно создавать словари в словарях. Т.е. ключом будет некое слово, а содержимое - подсловарём.
cats= {
'musya' : {'age' : 3, 'wool' : 'grey'},
'vasya' : {'age' : 5, 'wool' : 'black'}
}
>>> cats
{'musya': {'age': 3, 'wool': 'grey'}, 'vasya': {'age': 5, 'wool': 'black'}}
>>> cats['vasya']['age']
5
>>> cats['musya']['wool'][0]
'g'
________________________________________________________________________
Функции
Переходим к функциям. Знакомым с другими языками программирования не нужно объяснять, что это такое. Например, в программе мы часто используем какое-то выражение типа сумма двух квадратов и под корнем (гипотенуза или расстояние между точками). Можно для удобства прописать функцию.
* Сделаем пока без корня, чтобы не нужно было импортировать модуль (библиотеку) math - интерпретатор это не пережёвывает, неудобно мгновенно проверять код.
Пример создания функции:
def hypot2(a,b) :
return a*a + b*b
Далее в программе можно использовать, где вместо a, b подставляем то что нам нужно:
>>> hypot2(4,7)
65
# 4*4 + 7*7 = 65
Вместо конкретных чисел могут быть переменные, которые уже имеют какое-то значение. Или даже другие функции.
>>> hypot2(1, hypot2(3,5))
1157
Синтаксис функций понятен из примера выше. Оператор def, далее название нашей функции, далее в скобках используемые аргументы, далее двоеточие. И на новых строках через табуляцию прописываем какие-то действия с аргументами в скобках и получаем какой-то результат, который далее помещаем в return - тогда функция будет принимать (возвращать) этот полученный результат. Либо можно ничего не возвращать, просто печатать (print) например что-нибудь.
Пример функции, которая делает перевод N пустых строк:
def _ (N) :
for i in range (N) :
print()
И далее вызов функции:
_(5)
Что касается перегрузки функции в привычном понимании (с с++ или паскаля), то она тут не работает. Например для нашей предыдущей функции:
def _() :
_(1)
Данная функция работать не будет, выдаст ошибку. Функция-то создастся без ошибки типа, но вот воспроизводиться не будет.
Что же тогда делать? Ответ банален - давать разные имена функциям. Но это неудобно. Можно ещё делать значения по умолчанию, пример ниже:
def khypot (a, b, k=1) :
return k*hypot2(a,b)
>>> khypot(2,1)
5
>>> khypot(2,1,3)
15
Значений по умолчанию может быть несколько:
def count (a, b, k=1, m= 2) :
return k*hypot2(a,b) + m*khypot(m,(k*m))
Если мы хотим чтобы k=1 оставалось по умолчанию, но вот m изменить, используем функцию так:
>>> count(1,4,m=5)
267
Можно использовать в функции уже заранее объявленные глобальные переменные:
a= 5
b= 10
def sum() :
print(a+b)
И далее просто вызвать sum(). Однако, внутри функции нельзя менять глобальные переменные - выдаст ошибку. Если мы хотим поменять например a, то тогда нужно в начале функции написать global a. Ниже пример:
>>> a=6
>>> b=12
>>> def sum() :
global a
a= a+b
print(a+b)
>>> sum()
30
>>> a
18
>>> b
12
Вот ещё пример функции, которая возводит имеющееся глобальное число в квадрат, изменяя его таким образом:
>>> a= 5
>>> def q2() :
global a
a*=a
>>> a
5
>>> q2()
>>> a
25
Теперь вопрос - как сделать, чтобы функция меняла не глобальную переменную, а вообще любую. Например, написать q2(b) и переменная b умножится сама на себя. Потому что функция не меняет сами переменные аргументов, оперируя только с их копиями.
Вот пример что сами переменные не меняются:
>>> def q2 (a) :
a*= a
>>> b=3
>>> q2(b)
>>> b
3
Как было 3, так и осталось 3.
Я искал ответ на этот вопрос и каких-то специальных включений по адресу как в с++ например я не нашёл, но можно сделать так и лишний раз не заморачиваться:
>>> def q2(a) :
return a*a
>>> b=3
>>> b= q2(b)
>>> b
9
В питоне также можно объявлять вспомогательные функции внутри функций, например:
>>> def q (a) :
def cube(a) :
return a**3
return cube(cube(a) + a)
>>> q(1)
8
>>> q(2)
1000
При этом самой функцией cube() ты не можешь пользоваться во внешней части программы - она работает только внутри функции q(). Это примерно можно сравнить с private-методами класса.
Стоит также помнить, что в качестве аргумента функции спокойно может использоваться не только базовая переменная, но также строка или даже список.
>>> def dv (c) :
print (c + c)
>>> dv( [1, 4, 5] )
[1, 4, 5, 1, 4, 5]
>>> dv (3)
6
>>> dv ('муся')
мусямуся
Ну и словари тоже могут использоваться, если ты с ними что-то собираешься делать. Например тут мы переопределили функцию вывода, которая работает практически для любых объектов, в т.ч. и для словарей:
>>> def p(c) :
print (c)
>>> p(2)
2
>>> p({4:'kisa', 6:'vasya'})
{4: 'kisa', 6: 'vasya'}
По сути в питоне аргументы являются шаблонными и могут являются любым типом данных, для которых допустимы все операции, которые производятся в функции. Например, сложение допустимо как для чисел, так и для строк и списков - поэтому если функция состоит только из сложений, аргументы могут быть как числами, так и списками, строками.
________________________________________________________________________
Классы
Класс - это тип данных, который мы сами можем создавать для тех или иных нужд. Впрочем, для уже программирование это не нужно подробно объяснять. В питоне тоже можно создавать классы, наследование, инкапсуляция и прочее всё это добро есть - это объектно-ориентированный язык. До этого мы даже пользовались уже этим - строки, массивы (списки), словари - это всё тоже объекты класса, для них есть типовые методы типа добавить новый элемент в список и прочие.
Например, пусть у нас будет тип данных кошка, в котором мы будем хранить её имя, возраст и какую-нибудь логическую переменную - типа живая или нет. Ниже пример такого класса:
>>> class cat :
def __init__(self,name,age,alive) :
self.name= name
self.age= age
self.alive= alive
>>> musya= cat('musya',5,True)
>>> musya.age
5
Сначала пишем ключевое слово class, затем название класса. Далее двоеточие. И далее в табуляции мы создаём конструктор класса - это специальная функция def __init__. Первым аргументом обязательно указывается self. В конструкторе мы пишем атрибуты класса.
Ниже также показано создание экземпляра класса - нужно обязательно при объявлении задать какие-то начальные значения. И далее выводим например возраст.
Ниже добавим ещё какой-нибудь метод, например мяукание - просто будем выводить.
class cat :
def __init__(self,name,age,alive) :
self.name= name
self.age= age
self.alive= alive
""" добавляем метод мяукания - это комментарий такой"""
def meow (self) :
print("мяяяяяяяу")
При создании метода обязательно должен присутствовать аргумент self - то что мы типа как бы сами себя передаём.
kisa= cat('kis',4,True)
kisa.meow()
Конструктор писать необязательно - ниже будет показано как можно по другому. А также класс может быть вообще без атрибутов, только одни методы. Например, можно агрегировать некоторые функции для удобства в один общий класс, где эти функции станут методами.
Дополненный класс:
class cat :
def __init__(self,name,age,female) :
self.name= name
self.age= age
self.female= female
def meow (self) :
print("мяяяяяяяу")
def lost (self) :
return 20 - self.age
>>> vasya= cat('vaska',11,False)
>>> vasya.lost()
9
А можно всё и гораздо проще сделать вот например так:
>>> class cat :
age = 5
name = 'unknown'
>>> tishka = cat()
>>> tishka.name
'unknown'
>>> tishka.name= 'тишка'
>>> tishka.name
'тишка'
*
Пустой класс
class pustoy:
pass
Экземпляр пустого класса
a= pustoy()
a.param= 5 # создали атрибут классу a
b= pustoy()
А у экземпляра b атрибута param ещё нет.
*
Инкапсуляция в Python работает лишь на уровне соглашения между программистами о том, какие атрибуты являются общедоступными, а какие — внутренними.
Одиночное подчеркивание в начале имени атрибута говорит о том, что переменная или метод не предназначен для использования вне методов класса, однако атрибут доступен по этому имени.
class A:
def _private(self):
print("Это приватный метод!")
>>> a = A()
>>> a._private()
Это приватный метод!
Двойное подчеркивание в начале имени атрибута даёт бОльшую защиту: атрибут становится недоступным по этому имени.
class B:
def __private(self):
print("Это приватный метод!")
>>> b = B()
>>> b.__private()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'B' object has no attribute '__private'
Однако полностью это не защищает, так как атрибут всё равно остаётся доступным под именем _ИмяКласса__ИмяАтрибута:
>>> b._B__private()
Это приватный метод!
*
Наследование подразумевает то, что дочерний класс содержит все атрибуты родительского класса, при этом некоторые из них могут быть переопределены или добавлены в дочернем. Например, мы можем создать свой класс, похожий на словарь:
>>> class Mydict(dict):
... def get(self, key, default = 0):
... return dict.get(self, key, default)
...
>>> a = dict(a=1, b=2)
>>> b = Mydict(a=1, b=2)
Класс Mydict ведёт себя точно так же, как и словарь, за исключением того, что метод get по умолчанию возвращает не None, а 0.
>>> b['c'] = 4
>>> print(b)
{'a': 1, 'c': 4, 'b': 2}
>>> print(a.get('v'))
None
>>> print(b.get('v'))
0
Полиморфизм - разное поведение одного и того же метода в разных классах. Например, мы можем сложить два числа, и можем сложить две строки. При этом получим разный результат, так как числа и строки являются разными классами.
>>> 1 + 1
2
>>> "1" + "1"
'11'
Перегрузка операторов — один из способов реализации полиморфизма, когда мы можем задать свою реализацию какого-либо метода в своём классе.
Например, метод __init__ перегружает конструктор класса. Конструктор - создание экземпляра класса.
__del__(self) - вызывается при удалении объекта сборщиком мусора.
__repr__(self) - вызывается встроенной функцией repr; возвращает "сырые" данные, использующиеся для внутреннего представления в python.
__str__(self) - вызывается функциями str, print и format. Возвращает строковое представление объекта.
__lt__(self, other) - x < y вызывает x.__lt__(y).
__le__(self, other) - x ≤ y вызывает x.__le__(y).
__eq__(self, other) - x == y вызывает x.__eq__(y).
__ne__(self, other) - x != y вызывает x.__ne__(y)
__gt__(self, other) - x > y вызывает x.__gt__(y).
__ge__(self, other) - x ≥ y вызывает x.__ge__(y).
__bool__(self) - вызывается при проверке истинности. Если этот метод не определён, вызывается метод __len__ (объекты, имеющие ненулевую длину, считаются истинными).
__len__(self) - длина объекта.
Перегрузка арифметических операторов
__add__(self, other) - сложение. x + y вызывает x.__add__(y).
__sub__(self, other) - вычитание (x - y).
__mul__(self, other) - умножение (x * y).
__truediv__(self, other) - деление (x / y).
__floordiv__(self, other) - целочисленное деление (x // y).
__mod__(self, other) - остаток от деления (x % y).
__divmod__(self, other) - частное и остаток (divmod(x, y)).
__pow__(self, other[, modulo]) - возведение в степень (x ** y, pow(x, y[, modulo])).
__lshift__(self, other) - битовый сдвиг влево (x << y).
__rshift__(self, other) - битовый сдвиг вправо (x >> y).
__and__(self, other) - битовое И (x & y).
__xor__(self, other) - битовое ИСКЛЮЧАЮЩЕЕ ИЛИ (x ^ y).
__or__(self, other) - битовое ИЛИ (x | y).
Пойдём дальше.
__radd__(self, other),
__rsub__(self, other),
__rmul__(self, other),
__rtruediv__(self, other),
__rfloordiv__(self, other),
__rmod__(self, other),
__rdivmod__(self, other),
__rpow__(self, other),
__rlshift__(self, other),
__rrshift__(self, other),
__rand__(self, other),
__rxor__(self, other),
__ror__(self, other) - делают то же самое, что и арифметические операторы, перечисленные выше, но для аргументов, находящихся справа, и только в случае, если для левого операнда не определён соответствующий метод.
Например, операция x + y будет сначала пытаться вызвать x.__add__(y), и только в том случае, если это не получилось, будет пытаться вызвать y.__radd__(x). Аналогично для остальных методов.
Идём дальше.
__iadd__(self, other) - +=.
__isub__(self, other) - -=.
__imul__(self, other) - *=.
__itruediv__(self, other) - /=.
__ifloordiv__(self, other) - //=.
__imod__(self, other) - %=.
__ipow__(self, other[, modulo]) - **=.
__ilshift__(self, other) - <<=.
__irshift__(self, other) - >>=.
__iand__(self, other) - &=.
__ixor__(self, other) - ^=.
__ior__(self, other) - |=.
__neg__(self) - унарный -.
__pos__(self) - унарный +.
__abs__(self) - модуль (abs()).
__invert__(self) - инверсия (~).
__complex__(self) - приведение к complex.
__int__(self) - приведение к int.
__float__(self) - приведение к float.
__round__(self[, n]) - округление.
__enter__(self), __exit__(self, exc_type, exc_value, traceback) - реализация менеджеров контекста.
Пример для двумерного вектора
def __add__(self, other):
return Vector2d(self.x + other.x, self.y + other.y)
def __iadd__(self, other):
self.x += other.x
self.y += other.y
return self
________________________________________________________________________
Работа с файлами
Итак, начнем. Прежде, чем работать с файлом, его надо открыть.
f = open('text.txt', 'r')
У данной функции два параметра - имя файла и режим. Ниже список режимов:
'r' открытие на чтение (является значением по умолчанию).
'w' открытие на запись, содержимое файла удаляется, если файла не существует, создается новый.
'x' открытие на запись, если файла не существует, иначе исключение.
'a' открытие на дозапись, информация добавляется в конец файла.
'b' открытие в двоичном режиме.
't' открытие в текстовом режиме (является значением по умолчанию).
'+' открытие на чтение и запись
Режимы могут быть объединены, то есть, к примеру, 'rb' - чтение в двоичном режиме. По умолчанию режим равен 'rt'.
И последний аргумент, encoding, нужен только в текстовом режиме чтения файла. Этот аргумент задает кодировку.
Теперь чтение из файла. Ниже 2 способа:
1. Метод read, читающий весь файл целиком, если был вызван без аргументов, и n символов, если был вызван с аргументом (целым числом n).
>>> f = open('text.txt')
>>> f.read(1)
'H'
>>> f.read()
'ello world!\nThe end.\n\n'
2. Прочитать файл построчно, воспользовавшись циклом for:
>>> f = open('text.txt')
>>> for line in f:
... line
...
'Hello world!\n'
'\n'
'The end.\n'
'\n'
Теперь рассмотрим запись в файл. Попробуем записать в файл вот такой вот список:
>>> l = [str(i)+str(i-1) for i in range(20)]
>>> l
['0-1', '10', '21', '32', '43', '54', '65', '76', '87', '98', '109', '1110', '1211', '1312', '1413', '1514', '1615', '1716', '1817', '1918']
Откроем файл на запись:
>>> f = open('text.txt', 'w')
Запись в файл осуществляется с помощью метода write:
>>> for index in l:
... f.write(index + '\n')
...
4
3
3
3
3
Для тех, кто не понял, что это за цифры, поясню: метод write возвращает число записанных символов.
После окончания работы с файлом его обязательно нужно закрыть с помощью метода close:
>>> f.close()
Теперь попробуем воссоздать этот список из получившегося файла. Откроем файл на чтение (надеюсь, вы поняли, как это сделать?), и прочитаем строки.
>>> f = open('text.txt', 'r')
>>> l = [line.strip() for line in f]
>>> l
['0-1', '10', '21', '32', '43', '54', '65', '76', '87', '98', '109', '1110', '1211', '1312', '1413', '1514', '1615', '1716', '1817', '1918']
>>> f.close()
Мы получили тот же список, что и был. В более сложных случаях (словарях, вложенных кортежей и т. д.) алгоритм записи придумать сложнее. Но это и не нужно. В python уже давно придумали средства, такие как pickle или json, позволяющие сохранять в файле сложные структуры.
________________________________________________________________________
________________________________________________________________________
________________________________________________________________________
Дополнительно про язык Python
________________________________________________________________________
________________________________________________________________________
________________________________________________________________________
Дата добавления: 2018-09-22; просмотров: 344; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!