Моделирование LQ регуляторов
Выберем критерии для тех переменных, которые включеныв модель, описывающую поведение управляемого процесса. Это функция передачи системы, помех и любых других передаточных функций от измеряемых переменных. Выполняя эти две задачи, используем программуMATLAB для создания соответствующего закона управления, который затем может представлять собой несколько функций передачи.Соберем модель и выясним, какое поведение регулятора достигнуто.Для того чтобы синтезировать закон управления, который отвечает требованиям, нужно не только иметь хорошую модель процесса, но и знать, как выбрать критерии, который приведет к устойчивому управлению.
Ознакомимся с типичным поведением линейного квадратичного регулятора, работающего в разных режимах и с различными системами. Преимущество линейного квадратичного регулятора заключается в том, что управление оптимально по отношению к выбранному критерию, по крайней мере, когда система и модель являются линейными.Но даже эти «идеальные» условия обязательно означают, что поведение является «оптимальным для пользователя». Оптимальные управление почти всегда требует входного сигнала, который потребляет больше энергии, имеет большую амплитуду и более высокую частоту.Пользователь может оказаться неспособным (или не иметь возможности) найти такой сигнал, но имеет понятие о различии между качеством и ограничениями входного сигнала с использованием значений на входе 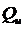 (или, более точно, отношения
(или, более точно, отношения 
|
|
|
Следовательно, эта переменная становится основным элементом настройки.Видно, что настройки недостаточно для поведения управления регулятора, чтобы она соответствовала требуемой характеристике. На практике требуются другие методы изменения поведения управления, такие как динамические критерии, модификация передаточной функции открытого цикла или фильтрации. Схема управления, используемая для моделирования, включает систему, контроллер, контур, подверженные помехам, генератор заданных значений и другие вспомогательные блоки. Каждый блок должен быть определен до начала моделирования; для этого различные процедуры и программы доступны в панели инструментов, основная схема регулирования, изображена на рисунке 4.
На схеме показана система, созданная блоком Systemс использованием дискретной передаточной функции и случайного дисбаланса, генерируемого блоком Disturbance. Блок Saturation, который представляет собой предел выходного сигнала контроллера, помещается перед системой.Регулятор создается блоками Filter-Filter 3. Filter и Filter1 обрабатывают обратную связь, Filter 2 с учетом заданного значения и Filter 3 с эффектом вспомогательного сигнала u0, хотя это не используется в стандартном подходе и поэтому отключается от диаграммы.Установленная точка генерируется блоком SignalGenerator. Другие блоки используются для вывода входных и выходных переменных и вычисления суммы квадратов ошибки вывода.
|
|
|
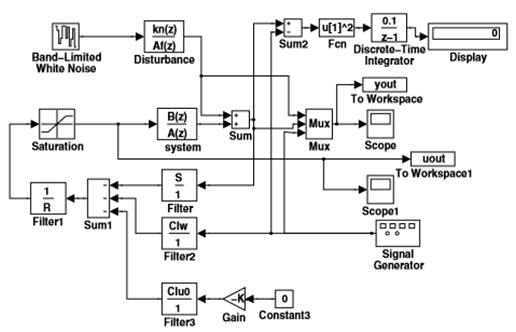
Рисунок 4 – Основная схема управления
Модель содержит ряд предопределенных систем, которые могут быть выбраны интерактивно, а также устанавливает соответствующий период выборки 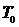 и несколько других параметров в программе Simulik, а также возможность вычисления регулятора.
и несколько других параметров в программе Simulik, а также возможность вычисления регулятора.
Качество управляющего поведения в значительной степени зависит от свойств системы. Известно, что так называемая не минимальная фазовая система относится к числу тех, в которых качество управляющего поведения иногда сильно ограничено[2]. Это системы, в которых передаточная функция имеет неустойчивый ноль. В то время как фазовые дискретные системы непрерывного времени не являются общими, они встречаются чаще с дискретным описанием. В этом случае свойство не минимальной фазы зависит не только от физических свойств системы, но и от периода выборки.
Были выбраны несколько простых систем. Тем не менее, они хорошо подходят для демонстрации избранных свойств.
|
|
|
S1 – простая система второго порядка, имеющая дискретную передаточную функцию
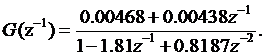
S2 – дискретная передаточная функция

3.1 Компенсация нарушений
Оптимальный закон управления будет состоять только из компонента обратной связи S/R.Поведение компенсации и выходной сигнал регулятора для «хорошо управляемой» системы S1 и для двух значений 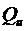 показаны на рисунке 5.Графики показывают временное поведение выходного сигнала и помехи без компенсации
показаны на рисунке 5.Графики показывают временное поведение выходного сигнала и помехи без компенсации 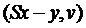 и выходной сигнал регулятора
и выходной сигнал регулятора 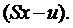
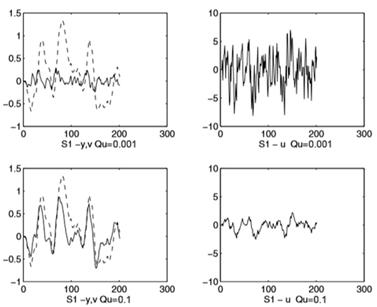
Рисунок 5 – Компенсация помех для системы S1
Следующий график, изображенные на рисунке 6, показывают ошибку компенсации помех системы S2, полученный с блоковScopeи Scope1. Как видно графики различаются при одинаковых критериях  и
и 
Если нужно поэкспериментировать с управлением системой, изменяя критерии, вводя эффективное ограничение на выход регулятора в блоке насыщения или используя только короткий горизонт в критерии оптимизации, большинство результатов будут получены, когда нарушение более или менее компенсируется. В то же время значение влияет на качество компенсации помех.
Подобное не распространяется на другие системы, которые являются либо нестабильными, либо неминуемыми, либо имеют временную задержку. Для неустойчивой системы ограничение входного сигнала является критическим. Выход контроллера остается в основном в пределах границы 
|
|
|
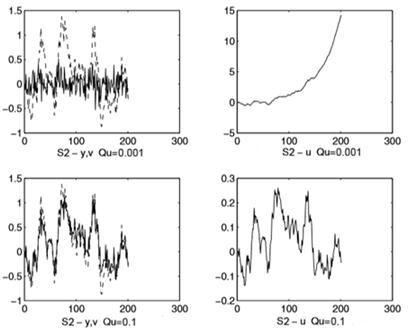
Рисунок 6 – Компенсация помех для системы S2
Подобное не распространяется на другие системы, которые являются либо нестабильными, либо неминуемыми, либо имеют временную задержку. Для неустойчивой системы ограничение входного сигнала является критическим. Выход контроллера остается в основном в пределах границы
Тем не менее, применение этого ограничения приводит к заметному ухудшению компенсации, но ограничение  приводит к нестабильности.Это помогает увеличить значение , так что ограничение не может вступить в силу.Длина горизонта критерия, используемого в этом случае, мало влияет на качество компенсации.
приводит к нестабильности.Это помогает увеличить значение , так что ограничение не может вступить в силу.Длина горизонта критерия, используемого в этом случае, мало влияет на качество компенсации.
Амплитуда выходного сигнала контроллера мала, и его ограничение блоком насыщения приводит к дальнейшему ухудшению компенсации помех, но таким образом, чтобы приблизиться к нарушению без контроля.
Системы S2 и S1 отличаются тем, что имеют два временных интервала задержки. Если нужно будет использовать горизонт в этой системе, то существует критерий, который может быть применен для получения хорошей компенсации помех.
Компенсация нарушения, представленная регрессионной моделью, являющаяся оптимальной. В минимальной фазовой системе нарушение может быть компенсировано его источником, белый шумом, который останется в процессе компенсации. Компенсация в не минимальных фазовых системах ограничена. Преимущество оптимального регулятора заключается в том, что требуется небольшойвыходной сигнал регулятора.
3.2Контроль заданного значения
Сначала рассмотрим изменение заданного значения шага. На рисунке 7 показаны графики для системы S1 и выходов контроллера с использованием двух разных критериев. Аналогичная ситуация изображена на рисунке 8, для системы S2. Оба получены в блокахScopeи Scope1 модели, изображенной на рисунке 4.
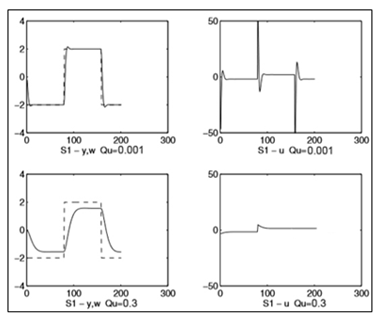
Рисунок 7 – Реакция на скачек и выходной сигнал для системы S1
Эксперименты с этими системами в различных условиях дают следующие результаты.Стандартная оптимизация критерия приводит к ошибке установившегося состояния. Это зависит от ограничения выхода регулятора и усиления системы. Вот почему критерий 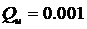 не заметен,а при
не заметен,а при 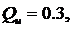 S1 и S2 на выходе возникает установившийся сигнал.
S1 и S2 на выходе возникает установившийся сигнал.
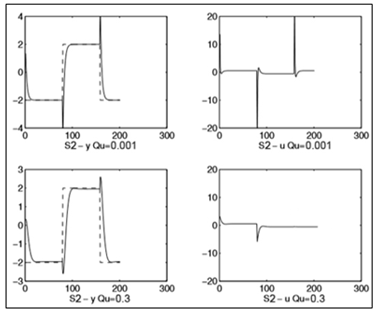
Рисунок 8 – Реакция на скачек и выходной сигнал для системыS2
Как и при компенсации помех, ограничение выходного сигнала контроллера приемлема для минимально - фазовой системы. Однако это может привести к нестабильности в неустойчивой системе, иметь очень отрицательный эффект в не минимально - фазовой системе.
Наблюдаем, что при изменении разных значений изменяется реакция на скачек входного сигнала, а также видны изменения выходного сигнала системы.
Ошибка управления установившегося состояния может увеличиваться, если изменение заданного значения равномерно.
Адаптивные контроллеры
Во многих ситуациях система неизвестна, известна лишь частично, или система настолько сложная, что модель, используемая в конструкции контроллера, может быть только приблизительна фактической установки. Во всех этих случаях первым шагом в проектировании контроллера является построение модели. Структура модели и ее параметры определяются по информации о системе (предварительная информация) и по измеренным данным о процессе.
Такая модель не близка к реальности. Поведение контроллера, предназначенного для модели, но используемого с фактической системой, зависит не только от используемого критерия модели, но и от того, как она представляет систему. В таких ситуациях адаптация и надежность становятся важными. Целью адаптации является настройка модели таким образом, чтобы она соответствовала реальному объекту.
Надежность подразумевает попытку гарантировать сохранение некоторых свойств управления для всех систем из предполагаемого набора. Эти две ветви теории управления часто рассматриваются изолированно, но на практике они обе необходимы одновременно. Любое моделирование процесса управления ограничено моделями с ограниченной сложностью. Информация о его параметрах также ограничена. Чем больше модель сможет соответствовать реальному объекту, тем менее необходима устойчивость, и наоборот.
Когда адаптация имеет приоритет, то достигается качественном управление. Идентификация играет доминирующую роль в адаптации. Этот процесс позволяет узнать о свойствах системы из измеренных данных. В настоящее время данные могут рассматриваться как случайные процессы. Формулируя задачу управления LQ как стохастический, возможно продемонстрировать, как процесс идентификации и управления синтезируется в адаптивный подход. В заключении покажем поведение контроллера LQ, используя LQtoolbox.
4.1 Стохастический подход к проектированию LQ контроллера
LQ синтез дает возможность работать со случайными сигналами. Если взять синтез Винера, который позволяет разработать оптимальное управление, минимизирующую квадратичную потерю для известного стохастического возмущения.
Если система имеет случайный выход или содержит случайный компонент, критерий нельзя напрямую минимизировать. Вместо этого должна использоваться детерминированная функция случайных величин. Опыт показывает, что среднее значение случайной величины или случайного процесса, является приемлемой функцией. Критерий выглядит следующим образом:
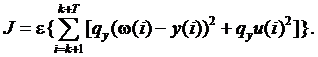
Введение среднего значения ε не связано с большими осложнениями. Чтобы свести к минимуму критерий, потребуется модель, которая определяет требуемое среднее значение. Это уже регрессионная модель, где детерминированная часть сигнала
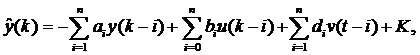
одновременно является средним значением выхода y(k). Можно записать как

где  содержит предыдущие входы и выходыy(k), а сигнал моделируется как
содержит предыдущие входы и выходыy(k), а сигнал моделируется как
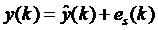 (1)
(1)
Так как 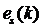 – белый шум с нулевым средним значением
– белый шум с нулевым средним значением 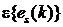 , то с учетом в критерии не фигурирует. Поскольку
, то с учетом в критерии не фигурирует. Поскольку 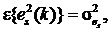 значение критерия будет увеличиваться с каждым новым средним значением
значение критерия будет увеличиваться с каждым новым средним значением 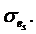 Это приращение не зависит от u(k) и не может быть изменено. Поэтому игнорируем его, когда критерий минимизирован.
Это приращение не зависит от u(k) и не может быть изменено. Поэтому игнорируем его, когда критерий минимизирован.
Все это приводит к «Принципу эквивалентной уверенности», который гласит, если, не зная истинных параметров, то используется среднее значение их оценок. Эти средние значения не обязательно приемлемы в качестве параметров. Начало адаптации является типичной ситуацией, когда оценки параметров задают правильные значения.
Используем принцип, когда синтез не основан на информации о состоянии (точности) оценочных параметров, содержащихся в ковариационной матрице. Синтез модифицируется, чтобы придать роль качеству идентификации. Поскольку результирующий алгоритм управления учитывает состояние идентификации, эта стратегия управления называется «осторожной».Аналогичные результаты получены из обобщения регрессионной модели, так что дисперсия ошибки является функцией ковариационной матрицы параметров. Эта модель получила название линейного стохастического преобразования [7]. В то время как уравнение (1) дает 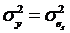 для модели регрессии, используется стохастическое линейное преобразование:
для модели регрессии, используется стохастическое линейное преобразование:
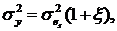
где 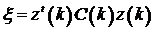 иz(k) – данные, используемые в y(k).
иz(k) – данные, используемые в y(k).
Эта модель является основой, называемой«осторожной стратегией» [7, 2], несмотря на то, что она частично связана с практическими применениями, и не может быть использована в результате адаптивного управления из-за двух серьезных сбоев:
● ковариационную матрицу C запуска выбираем очень тщательно, если стратегия должна дать хорошие результаты;
● стратегия очень часто выбирает u(k) для минимизации ξ, а не ее собственного критерия. Последовательность u(k) особенно не подходит для идентификации параметров, в результате чего ковариационная матрица не становится меньше. Это означает, что весь процесс не может избежать плохого контроля.
4.2 Синтез квадратичного управления в реальном времени
Использование синтеза LQ в адаптивных контроллерах определяется тем фактом, что синтез контроллера должен постоянно повторяться по мере изменения параметров. Поэтому оценка и синтез параметров обновляются в каждый период выборки. Важное значение имеет ограничение на конечное допустимое время расчета. С одной стороны, это зависит от периода выборки и скорости технологии расчета, а с другой – от сложности расчета. Метод расчета, который требует частого, нонебольшого времени для вычисления, лучше всего подходит для адаптивного управления. Поскольку это итеративный процесс, в котором время вычисления зависит от ряда факторов, нет гарантии, что оптимальное управление, соответствующее в бесконечном горизонте, может быть рассчитан за один период управления.
Существуют две альтернативы, что в каждый период выборки критерий конечного горизонта будет сведен к минимуму. Длина горизонта должна обеспечивать достаточное место для итераций для завершения решения уравнения Риккати за допустимое время. К этому подходу добавляется тест на сходимость закона управления, а расчет прерывается, если падает скорость сходимости. Там, где итераций мало, начальные условия для решения уравнения Риккати играют важную роль в устойчивости и качестве (корни замкнутого контура).Матрица 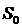 действует как кнопка настройки.Этот подход, в котором горизонт смещается все дальше и дальше во время процесса управления, известен как «Стратегия отступающего горизонта» или «Стратегия горизонтального перемещения».
действует как кнопка настройки.Этот подход, в котором горизонт смещается все дальше и дальше во время процесса управления, известен как «Стратегия отступающего горизонта» или «Стратегия горизонтального перемещения».
Если нужен контроль с бесконечным горизонтом, то увеличим итерации уравнения Риккати во времени. Это означает, что фиксированное количество итераций выполняется в каждый контрольный период, основываясь на ранее достигнутом состоянии, а не на начальных условиях [4]. Эффект этого заключается в том, что критический горизонт увеличивается на выбранное число в каждый контрольный период (NSTEP). Через некоторое время закон управления будет приближаться к решению стационарного состояния. Это предполагает, что используется одни и те же параметры модели для расчета за каждый контрольный период. Это не обязательно верно при адаптивном управлении. Невозможно определить, что будет контролировать закон, когда параметры могут измениться. Опыт показывает, что эта стратегия, известная как IST (IST, IterationSpreadinTime), дает хороший результат, когда в течение контрольного периода используется только одна итерация, причем это кратчайшее время вычисления.
Стратегия IST имеет еще один положительный эффект. Это одновременно и одна стабилизирующая стратегия. Когда стратегия имеет только один шаг, будущие значения ввода и вывода легко определить и сравнить с требованием ограничения, так чтокритерий 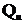 может быть непосредственно изменен для сохранения ограничения. Этот алгоритм известен как MIST (измененная итерация во времени)[8].
может быть непосредственно изменен для сохранения ограничения. Этот алгоритм известен как MIST (измененная итерация во времени)[8].
Дата добавления: 2018-08-06; просмотров: 186; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!