Другие методы. Не вошедшие в предыдущие группы.
Статистические алгоритмы кластеризации
Ансамбль кластеризаторов
Алгоритмы семейства KRAB
Алгоритм, основанный на методе просеивания
DBSCAN и др.
Подходы 4 и 5 иногда объединяют под названием структурного или геометрического подхода, обладающего большей формализованностью понятия близости[2]. Несмотря на значительные различия между перечисленными методами все они опираются на исходную «гипотезу компактности»: в пространстве объектов все близкие объекты должны относиться к одному кластеру, а все различные объекты соответственно должны находиться в различных кластерах.
Все методы кластерного анализа состоят из четырех основных шагов: а) выбор мер и произведение измерений характерных признаков объектов или индивидов, подлежащих классификации; б) задание меры сходства; в) формулирование правил и определение порядка формирования кластеров; г) применение этих правил к данным для формирования кластеров. Так как каждый шаг предполагает выбор из множества возможных процедур, был разработан широкий спектр методик кластеризации.
На первом шаге принимается решение о том, какие характерные признаки или свойства будут использоваться в качестве основы классификации. Конечно, это решение будет зависеть от проблемы исследования и природы классифицируемых объектов. Хотя обычно все признаки имеют одинаковые веса, не исключается возможность выбора процедуры приписывания различных весов.
Принимаемое на втором шаге решение связано с выбором подходящей меры сходства. Это м. б. число общих признаков, корреляция между признаками, метрика (пространства классификации) или к.-л. др. мера.
На третьем шаге выбирается сам метод классификации. Агломеративные методы начинают с анализа отдельных объектов или индивидов и объединяют их в группы; методы расслоения начинают с анализа полной группы и делят ее на подгруппы. Классификация по одному признаку приводят к классам, все элементы которых имеют по крайней мере один общий отличительный признак; классификация, основывается на сравнении нескольких признаков, приводят к группам, которые обладают рядом общих свойств, но не обязательно обладают одним общим отличительным признаком.
Принимаемое на четвертом шаге решение касается момента остановки процедуры классификации или, проще говоря, определения количества сформированных групп. Это может определяться как внутренними критериями (например, естественным разбиением полной группы на подгруппы), так и внешними критериями (т. е. тем, какая схема классификации приводит к наиболее полезным закономерностям). Наконец, необходимо решить, будет ли использоваться иерархическая или неиерархическая схема классификации. При выборе иерархической схемы сформированные группы будут находиться на различных уровнях обобщенности (как в биологических таксономиях); в случае выбора неиерархической схемы получаются группы одного уровня обобщенности (как при использовании Q-техники факторного анализа). Результаты этих решений будут определять подходящий метод кластерного анализа и характер сформированных кластеров.

Рис.3 Дендрограмма горизонтальная

Рис.4 График средних для каждого кластера
Факторный анализ
С возрастанием количества анализируемых признаков быстро растет трудность изучения и классификации характеризуемых ими объектов. Между тем, любые сложнопостроенные системы, как правило, управляются сравнительно небольшим набором факторов. Выявлению и анализу этих факторов посвящен широкий круг вычислительных процедур, обычно объединяемых названием «факторный анализ». Следует однако, помнить, что в названной области выделяется несколько самостоятельных процедур: метод главных компонент (МГК), R–метод факторного анализа, Q–метод факторного анализа, анализ главных координат, анализ соответствия. Все эти методы основаны на выделении собственных значений и собственных векторов ковариационной или корреляционной матрицы, поскольку заранее предполагается, что в наборе многомерных наблюдений скрыта простая структура, выражающаяся через дисперсии и ковариации переменных.
Метод главных компонент позволяет выявить группы элементов, наиболее тесно связанных с тем или иным мощным фактором. Элементы, однонаправлено изменяющие свое состояние под действием общего фактора, могут быть объединены в комбинации, называемые главными компонентами. Число последних намного меньше исходного числа параметров, в то же время они несут практически всю полезную информацию об изменчивости свойств, заключенную в исходной совокупности.
Главные компоненты вычисляются по формулам:
1ГК = ∑ωilxi = ω1l ·х1 + ω1х2 + . . . . +ωn1хn;
2ГК = ∑ωi2xi;
3ГК = ∑ωi3xi и т.д..
Здесь xi - значения параметров, ωij - факторные нагрузки (это влияние j -го фактора на i -й элемент, т.е. своего рода коэффициент корреляции между ними).
Таким образом, для нахождения главных компонент нам необходимо вычислить матрицу факторных нагрузок W. Она определяется из соотношения:
W = uΛ½
где u - матрица собственных векторов, а Λ - матрица собственных чисел корреляционной матрицы R. Элементы матрицы Λ определяются как корни характеристического уравнения:
|R-λ׀| = 0 , где I - единичная матрица.
Вычислив этот определитель, получаем уравнение, степень которого и число полученных корней равны числу строк в корреляционной матрице R . При этом λ1 >λ2 >λ3 . . . >λn, a ∑λi = n. Матрица u, находится из выражения:
(R - λ1)u=0
Подставляя в это уравнение найденные значения λi, получаем для каждого λi вектор значений ui.
Таблица №8
Матрица факторных нагрузок
| Na2O | MgO | Al2O3 | SiO2 | P2O5 | S* | K2O | CaO | TiO2 | MnO | Fe2O3 | |
| F1 | 0,33 | -0,74 | -0,41 | 0,88 | -0,57 | 0,15 | 0,61 | -0,59 | -0,42 | -0,74 | -0,85 |
| F2 | -0,27 | 0,40 | -0,84 | 0,36 | -0,16 | -0,34 | -0,40 | 0,67 | -0,77 | 0,04 | -0,32 |
Как видим, 1-й фактор значимо влияет на все элементы. Такой фактор обычно называют генеральным. Генеральный фактор отрицательно сказывается на контрастности корреляционной матрицы, обуславливая перекрытие выделяемых групп. Дать главным факторам геологическую интерпретацию не всегда возможно, но когда это удается, информативность метода резко возрастает. В частности, в рассмотренном примере со 2-м фактором, видимо, связан процесс карбонатизации пород. Дать интерпретацию 1-му фактору сложнее. Возможно, это песчаники.

Рис.5 Диаграмма факторных нагрузок
Метод главных компонент можно использовать и для распознавания образов. Для этого в координатах двух ГК выносятся значения для эталонных объектов и локализуются области, отвечающие этим объектам (рис. .)

Рис.6 Определение промышленного типа месторождения по методу главных компонент.
а - 1-й промтип, б - 2-й промтип, в – непромышленнные объекты, г - изучаемое рудопроявление.
Таким образом МГК сводится к линейному преобразованию М исходных переменных в т новых переменных, каждая из которых является линейной комбинацией исходных переменных. При этом МГК не является статистическим методом и мы практически не имеем формальных критериев для отбрасывания некоторых переменных или компонент, дающих очень малый вклад в суммарную дисперсию. О правильности своих действий мы можем судить только после проведения анализа МГК.
В отличие от МГК, факторный анализ считается статистическим методом, поскольку в его основе лежат некоторые предположения о природе изучаемой совокупности. Предполагается, что связь между m переменными является отражением корреляционной зависимости каждой из переменных с р взаимно некоррелированными факторами, причем р<m (если р = m, модель эквивалентна МГК). Поэтому дисперсию для m переменных можно вычислить с помощью дисперсии р – факторов плюс вклад, происхождение которого одинаково для всех переменных.
В Q-методе факторного анализа, в отличие от R-метода, анализируются взаимосвязи между наблюдениями, а не переменными.
Одно из главных препятствий в применении геологами различных модификаций факторного анализа заключено в абстрактности понятий собственных векторов и собственных значений корреляционных матриц. Между тем, эти категории имеют вполне определенный содержательный и геометрический смысл. На рис. видно, что строки корреляционной матрицы можно представить как произвольные оси двумерного эллипсоида, тогда собственные вектора, дают направление главных осей эллипсоида, а корень из величины собственного значения – длину главных полуосей. Поскольку собственные значения включают в себя дисперсии переменных, очевидно, что и факторы отражают дисперсии (точнее, стандартные отклонения). При этом наклон и длина главных осей эллипсоида наглядно свидетельствуют о влиянии фактора на значения конкретной переменной.
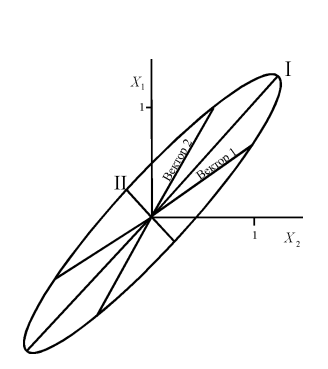
Рис.7 . Графическое изображение собственных векторов корреляционной матрицы.
Поскольку одна из главных задач факторного анализа - сокращение размерности исходного пространства признаков, важнейшим вопросом является выбор количества сохраненных факторов. Формального ответа на этот вопрос не существует, поэтому в большинстве случаев рекомендуется сохранять столько факторов, сколько имеется собственных чисел, больших 1, то есть сохраняются факторы, вклад которых в дисперсию больше, чем у каждой из исходных переменных. Эта рекомендация полезна в тех случаях, когда исходные данные хорошо скоррелированы и первые 2-3 фактора дают основной вклад в общую дисперсию. Если же переменные скоррелированы слабо, то половина и даже больше факторов может иметь собственные числа большие единицы. Число факторов получается слишком большим, причем вклад каждого из них в дисперсию невелик, а содержательная интерпретация затруднительна. В таких случаях применение факторной модели следует признать нецелесообразным.
В ряде случаев бывает затруднительно дать интерпретацию факторов даже если переменные хорошо скоррелированы. Перекрытие групп переменных зачастую обусловлено тем, что положение р ортогональных факторных осей в m-мерном пространстве определяется положением m–р ненужных ортогональных осей в выборочном пространстве. Исключив из рассмотрения ненужные оси, мы можем произвести вращение оставшихся факторных осей таким образом, чтобы выделенные группы наилучшим образом расположились в новых координатах. В наиболее часто используемом методе (метод варимакс Кайзера ) вращение осуществляется до тех пор, пока проекции каждой переменной на факторные оси не окажутся близкими либо к нулю, либо к ±1. Чаще всего такое вращение приводит к тому, что для каждого фактора мы получаем несколько больших значений нагрузок и много близких к нулю. Это существенно облегчает содержательную интерпретацию факторов. Если же вращение факторных осей лишь ухудшает первоначальный результат, это свидетельствует либо о взаимной коррелированности факторов, либо о неприменимости выбранной факторной модели.
Графическое представление процедуры вращения факторных осей для двумерного случая дано на рис..

Рис. 8. Вращение факторных осей для двумерного случая.
Проекции векторов переменных на факторные оси соответствуют их факторным нагрузкам. Видно, что после вращения разделение элементов на группы значительно улучшилось. При этом длина векторов и их относительное положение не изменились.
Таким образом, факторный анализ сочетает в себе преимущества и возможности как методов группирования, так и распознавания образов. В частности, он может быть использован как вариант множественной регрессии для вычисления востановленных значений переменной:
Хвосст. = S⋅ωj⋅Z′j+х⋅ε΄,
где S – диагональная матрица m х m оценок стандартов m переменных;
ωj – факторная нагрузка j фактора;
Z´j – вектор-строка значений фактора j;
х - среднее значение параметра по выборочным данным;
ε΄ -вектор-строка размером N (число наблюдений) вида {1, 1, 1, . . . . 1}.
Таким способом можно оценить влияние каждого выделенного фактора (процесса) на распределение конкретного элемента и геометризовать в пространстве интенсивность этого влияния. Эта задача обычна при создании генетических моделей и прогнозо-поисковых комплексов [5].
Заключение
Данная контрольная работа, основной целью, которой было выяснить и понять распределение полезных компонентов в Южно-русском районе, по данным полученным в результате рентгенофлуоресцентного анализа осадочных горных пород, решила много задач.
Определил, что основными компонентами являются SiO2 и Al2O3 максимальноепоказание в статистических данных. Следует предположить, что это указывает на распространение алюмосиликатов на данной территории. В частности КПШ, плагиоклазы. Связь MgO и CaO может свидетельствовать о породах известковых скарнов.
В результате написания автор научился применять математические методы моделирования для обработки геологической информации, в программе «Statistica», реализующий функции анализа данных, управления данными, добычи данных, визуализации данных с привлечением статистических методов; формулировать геологические задачи в пригодном виде для их решения математическими методами; изучил основные принципы геолого-математического моделирования.
Список использованной литературы
1. Гуськов, О.И. Математические методы в геологии. Сборник задач / О.И. Гуськов, П. И. Кушнарев, С.М. Таранов. – М.: Недра,2007. – 205 с.
2. Каждан, А.Б. Математические методы в геологии. Учебник для вузов / А.Б. Каж- дан, О.И. Гуськов, А.А. Шимановский. – М.: Недра, 2010. – 251 с.
3. Шестаков, Ю.С. Математические методы в геологии. Учебник для вузов. – Крас- ноярск: КИЦМ, 2008. – 208 с. б) дополнительная литература:
4. Беус, А.А. Руководство по предварительной математической обработке геохими- ческих данных при поисковых работах. М.: МГУ, 2006. – 118 с.
5. Ворошилов В.Г. Математическое моделирование в геологии: Учебное пособие. Томск: Изд. ТПУ, 2001. - 124 с
6. Распознавание: [Электронный ресурс]. – URL: http://www.machinelearning.ru/ wiki/index.php ?title=Эффективность. (Дата обращения 23.05.18).
7. Энатская Н. Ю., Хакимуллин Е. Р. «Математическая статистика. Учебное пособие» – Московский государственный институт электроники и математики. М., 2011. – 118с.
Дата добавления: 2018-06-27; просмотров: 444; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!