Файлы с неплотным индексом, или индексно-последовательные файлы
Попробуем усовершенствовать способ хранения файла: будем хранить его в упорядоченном виде и применим алгоритм двоичного поиска для доступа к произвольной записи.Неплотный индекс строится именно для упорядоченных файлов. Для этих файлов используется принцип внутреннего упорядочения для уменьшения количества хранимых индексов. Структура записи индекса для таких файлов состоит из значения ключа первой записи блока и номера блока с этой записью.
В индексной области мы теперь ищем нужный блок по заданному значению первичного ключа. Так как все записи упорядочены, то значение первой записи блока позволяет нам быстро определить, в каком блоке находится искомая запись. Все остальные действия происходят в основной области. Время сортировки больших файлов весьма значительно, но поскольку файлы поддерживаются сортированными с момента их создания, накладные расходы в процессе добавления новой информации будут гораздо меньше.
ЛЕКЦИЯ 22. ИНВЕРТИРОВАННЫЕ СПИСКИ, СВЯЗАННЫЕ ФАЙЛЫ
Цели и задачи лекции:Ознакомиться с принципами организации взаимосвязанных файлов.
Основные вопросы: Связанные файлы, инвертированные списки.
Принцип организации связанных файлов рассмотрим на следующем примере.
Связаны два файла, например F1 и F2, где одна запись в файле F1 может быть связана с несколькими записями в файле F2. При этом файл F1 в этом комплексе условно называется "Основным", а файл F2 - "зависимым" или "подчиненным". Структура основного файла может быть условно представлена в виде трех областей:
|
|
|
· Ключ.
· Запись.
· Ссылка-указатель на первую запись в "подчиненном" файле, с которой начинается цепочка записей файла F2, связанных с данной записью файла F1.
В подчиненном файле также к каждой записи добавляется специальный указатель, в нем хранится номер записи, которая является следующей в цепочке записей "подчиненного" файла, связанной с одной записью "основного" файла.
Таким образом, каждая запись "подчиненного файла" делится на две области:
область указателя; область, содержащую собственно запись.
В качестве примера рассмотрим связь между преподавателями и занятиями, которые эти преподаватели проводят. В файле F1 приведен список преподавателей, а в файле F2 - список занятий, которые они ведут.
| |||||||||||||||
|
| ||||||||||||||||||||||||||
|
В этом случае содержимое двух взаимосвязанных файлов F1 и F2 может быть расшифровано следующим образом: первая запись в файле F1 связана с цепочкой записей файла F2, которая начинается с записи номер 1, следующая запись номер 4 и последняя запись в цепочке - запись номер 5. Последняя - потому что пятая запись не имеет ссылки на следующую запись в цепочке. Аналогично можно расшифровать и остальные связи. Если мы проведем интерпретацию данных связей на уровне предметной области, то можно утверждать, что преподаватель Иванов ведет предмет "Вычислительные сети" в группе 4306, "Моделирование" в группе 84305 и "Вычислительные сети" в группе 4309. Аналогично могут быть расшифрованы и остальные взаимосвязанные записи.
Алгоритм нахождения нужных записей "подчиненного" файла:
Шаг 1. Ищется запись в "основном" файле в соответствии с его организацией (с помощью функции хеширования, или с использованием индексов, или другим образом). Если требуемая запись найдена, то переходим к шагу 2, в противном случае выводим сообщение об отсутствии записи основного файла.
Шаг 2. Анализируем указатель в основном файле, если он пустой, то есть стоит прочерк, значит, для этой записи нет ни одной связанной с ней записи в "подчиненном файле", и выводим соответствующее сообщение, в противном случае переходим к шагу 3.
Шаг 3. По ссылке-указателю в найденной записи основного файла переходим прямым методом доступа по номеру записи на первую запись в цепочке "Подчиненного" файла. Переходим к шагу 4.
Шаг 4. Анализируем текущую запись на содержание, если это искомая запись, то мы заканчиваем поиск, в противном случае переходим к шагу 5.
Шаг 5. Анализируем указатель на следующую запись в цепочке, если он пуст, то выводим сообщение, что искомая запись отсутствует, и прекращаем поиск, в противном случае по ссылке-указателю переходим на следующую запись в "подчиненном файле" и снова переходим к шагу 4.
Использование цепочек записей позволяет эффективно организовывать модификацию взаимосвязанных файлов.
Алгоритм удаления записи из цепочки "подчиненного" файла:
Шаг 1. Ищется удаляемая запись в соответствии с ранее рассмотренным алгоритмом. Единственным отличием при этом является обязательное сохранение в специальной переменной номера предыдущей записи в цепочке, допустим, это переменная NP.
Шаг 2. Запоминаем в специальной переменной указатель на следующую запись в найденной записи, например, заносим его в переменную NS. Переходим к шагу 3.
Шаг 3. Помечаем специальным символом, например символом звездочка (*), найденную запись, то есть в позиции указателя на следующую запись в цепочке ставим символ "*" - это означает, что данная запись отсутствует, а место в файле свободно и может быть занято любой другой записью.
Шаг 4. Переходим к записи с номером, который хранится в NP, и заменяем в ней указатель на содержимое переменной NS.
Для того чтобы эффективно использовать дисковое пространство при включении новой записи в "подчиненный файл", ищется первое свободное место, т.е. запись, помеченная символом "*", и на ее место заносится новая запись, после этого производится модификация соответствующих указателей.
|
|
|
|
|
|
Инвертированные списки
До сих пор мы рассматривали структуры данных, которые использовались для ускорения доступа по первичному ключу. Однако достаточно часто требуется проводить операции доступа по вторичным ключам. Напомним, что вторичным ключом является набор атрибутов, которому соответствует набор искомых записей. Это означает, что существует множество записей, имеющих одинаковые значения вторичного ключа. Например, в случае нашей БД "Библиотека" вторичным ключом может служить место издания, год издания. Множество книг могут быть изданы в одном месте, и множество книг могут быть изданы в один год.
Для обеспечения ускорения доступа по вторичным ключам используются структуры, называемые инвертированными списками, которые послужили основой организации индексных файлов для доступа по вторичным ключам.
Инвертированный список в общем случае - это двухуровневая индексная структура. Здесь на первом уровне находится файл или часть файла, в которой упорядочение расположены значения вторичных ключей. Каждая запись с вторичным ключом имеет ссылку на номер первого блока в цепочке блоков, содержащих номера записей с данным значением вторичного ключа. На втором уровне находится цепочка блоков, содержащих номера записей, содержащих одно и то же значение вторичного ключа. При этом блоки второго уровня упорядочены по значениям вторичного ключа.
И, наконец, на третьем уровне находится собственно основной файл.
Механизм доступа к записям по вторичному ключу при подобной организации записей весьма прост. На первом шаге мы ищем в области первого уровня заданное значение вторичного ключа, а затем по ссылке считываем блоки второго уровня, содержащие номера записей с заданным значением вторичного ключа, а далее уже прямым доступом загружаем в рабочую область пользователя содержимое всех записей, содержащих заданное значение вторичного ключа.
Для одного основного файла может быть создано несколько инвертированных списков по разным вторичным ключам.
Следует отметить, что организация вторичных списков действительно ускоряет поиск записей с заданным значением вторичного ключа. Но рассмотрим вопрос модификации основного файла.
При модификации основного файла происходит следующая последовательность действий:
· Изменяется запись основного файла.
· Исключается старая ссылка на предыдущее значение вторичного ключа.
· Добавляется новая ссылка на новое значение вторичного ключа.
При этом следует отметить, что два последних шага выполняются для всех вторичных ключей, по которым созданы инвертированные списки. И, разумеется, такой процесс требует гораздо больше временных затрат, чем просто изменение содержимого записи основного файла без поддержки всех инвертированных списков.
ЛЕКЦИЯ 23 . В-ДЕРЕВЬЯ
Цели и задачи лекции:Ознакомиться с методами организации древовидных структур во внешней памяти.
Основные вопросы: В-деревья, В+-деревья, поиск, удаление и добавление элементов.
Базовым "древовидным" аппаратом для поиска данных во внешней памяти являются B-деревья. В основе этого механизма лежат следующие идеи. Во-первых, поскольку речь идет о структурах данных во внешней памяти, общее время доступа к которой определяется в основном не объемом последовательно расположенных данных, а временем чтения и записи, то выгодно получать за одно обращение к внешней памяти как можно больше информации, учитывая при этом необходимость экономного использования основной памяти. При сложившемся подходе к организации основной памяти в виде набора страниц равного размера естественно считать именно страницу единицей обмена с внешней памятью. Во-вторых, желательно обеспечить такую поисковую структуру во внешней памяти, при использовании которой поиск информации по любому ключу требует заранее известного числа обменов с внешней памятью.
Классические B-деревья
Механизм классических B-деревьев был предложен в 1970 г. Бэйером и Маккрейтом. B-дерево порядка n представляет собой совокупность иерархически связанных страниц внешней памяти (каждая вершина дерева - страница), обладающая следующими свойствами:
1.Каждая страница содержит не более 2*n элементов (записей с ключом).
2.Каждая страница, кроме корневой, содержит не менее n элементов.
3.Если внутренняя (не листовая) вершина B-дерева содержит m ключей, то у нее имеется m+1 страниц-потомков.
4.Все листовые страницы находятся на одном уровне.
Количество обращений к диску при этом для поиска любой записи одинаково и равно количеству уровней в построенном дереве. Такие деревья называются сбалансированными (balanced) именно потому, что путь от корня до любого листа в этом древе одинаков. Именно термин "сбалансированное" от английского "balanced" - "сбалансированный, взвешенный" и дал название данному методу организации данных.
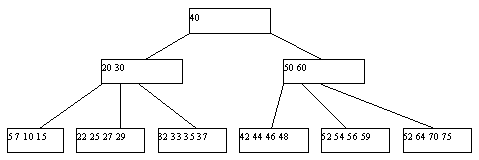
Рис. 1. Классическое B-дерево порядка 2
Поиск в B-дереве производится очевидным образом. Предположим, что происходит поиск ключа K. В основную память считывается корневая страница B-дерева. Предположим, что она содержит ключи k1, k2, ..., km и ссылки на страницы p0, p1, ..., pm. В ней последовательно (или с помощью какого-либо другого метода поиска в основной памяти) ищется ключ K. Если он обнаруживается, поиск завершен. Иначе возможны три ситуации:
1.Если в считанной странице обнаруживается пара ключей ki и k(i+1) такая, что ki < K < k(i+1), то поиск продолжается на странице pi.
2.Если обнаруживается, что K > km, то поиск продолжается на странице pm.
3.Если обнаруживается, что K < k1, то поиск продолжается на странице p0.
Для внутренних страниц поиск продолжается аналогичным образом, пока либо не будет найден ключ K, либо мы не дойдем до листовой страницы. Если ключ не находится и в листовой странице, значит ключ K в B-дереве отсутствует.
Включение нового ключа K в B-дерево выполняется следующим образом. По описанным раньше правилам производится поиск ключа K. Поскольку этот ключ в дереве отсутствует, найти его не удастся, и поиск закончится в некоторой листовой странице A. Далее возможны два случая. Если A содержит менее 2*n ключей, то ключ K просто помещается на свое место, определяемое порядком сортировки ключей в странице A. Если же страница A уже заполнена, то работает процедура расщепления. Заводится новая страница C. Ключи из страницы A (берутся 2*n-1 ключей) + ключ K поровну распределяются между A и C, а средний ключ вместе со ссылкой на страницу C переносится в непосредственно родительскую страницу B. Конечно, страница B может оказаться переполненной, рекурсивно сработает процедура расщепления и т.д., вообще говоря, до корня дерева. Если расщепляется корень, то образуется новая корневая вершина, и высота дерева увеличивается на единицу. Одношаговое включение ключа с расщеплением страницы показано на рисунке 2.
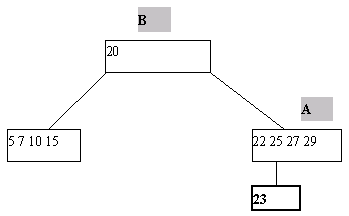
(a) Попытка вставить ключ 23 в уже заполненную страницу
(b) Выполнение включения ключа 22 путем расщепления страницы A
Рис.2. Пример включения ключа в B-дерево
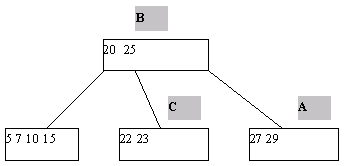
Процедура исключения ключа из классического B-дерева более сложна. Приходится различать два случая - удаление ключа из листовой страницы и удаления ключа из внутренней страницы B-дерева. В первом случае удаление производится просто: ключ просто исключается из списка ключей. При удалении ключа во втором случае для сохранения корректной структуры B-дерева его необходимо заменить на минимальный ключ листовой страницы, к которой ведет последовательность ссылок, начиная от правой ссылки от ключа K (это минимальный содержащийся в дереве ключ, значение которого больше значения K). Тем самым, этот ключ будет изъят из листовой страницы (рисунок 3).
(a) Начальный вид B-дерева
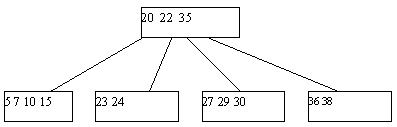
(b) B-дерево после удаления ключа 25
Рис. 3. Пример исключения ключа из B-дерева
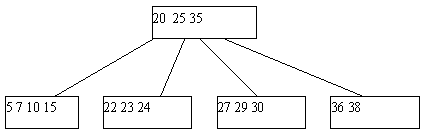
Поскольку в любом случае в одной из листовых страниц число ключей уменьшается на единицу, может нарушиться то требование, что любая, кроме корневой, страница B-дерева должна содержать не меньше n ключей. Если это действительно случается, начинает работать процедура переливания ключей. Берется одна из соседних листовых страниц (с общей страницей-предком); ключи, содержащиеся в этих страницах, а также средний ключ страницы-предка поровну распределяются между листовыми страницами, и новый средний ключ заменяет тот, который был заимствован у страницы-предка (рисунок 4).
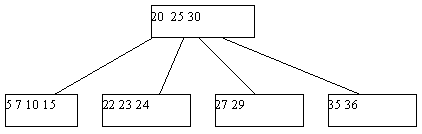
Рис. 4. Результат удаления ключа 38 из B-дерева с рисунка 5.3
Может оказаться, что ни одна из соседних страниц непригодна для переливания, поскольку содержат по n ключей. Тогда выполняется процедура слияния соседних листовых страниц. К 2*n-1 ключам соседних листовых страниц добавляется средний ключ из страницы-предка (из страницы-предка он изымается), и все эти ключи формируют новое содержимое исходной листовой страницы. Поскольку в странице-предке число ключей уменьшилось на единицу, может оказаться, что число элементов в ней стало меньше n, и тогда на этом уровне выполняется процедура переливания, а возможно, и слияния. Так может продолжаться до внутренних страниц, находящихся непосредственно под корнем B-дерева. Если таких страниц всего две, и они сливаются, то единственная общая страница образует новый корень. Высота дерева уменьшается на единицу, но по-прежнему длина пути до любого листа одна и та же. Пример удаления ключа со слиянием листовых страниц показан на рисунке 5.
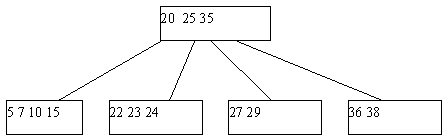
(a) Начальный вид B-дерева
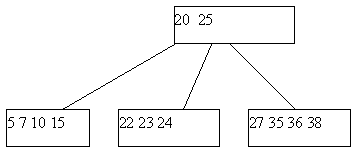
(b) B-дерево после удаления ключа 29
Рис. 5. Пример удаления ключа из B-дерева со слиянием листовых страниц
B+-деревья
Схема организации классических B-деревьев проста, но не очень хороша для практического использования. Прежде всего это связано с тем, что в большинстве практических применений необходимо хранить во внешней памяти не только ключи, но и записи. Поскольку в B-дереве элементы располагаются и во внутренних, и в листовых страницах, а размер записи может быть достаточно большим, внутренние страницы не могут содержать слишком много элементов, по причине дерево может быть довольно глубоким. Поэтому для доступа к ключам и записям, находящимся на нижних уровнях дерева, может потребоваться много обменов с внешней памятью. Во-вторых, на практике часто встречается потребность хранения и поиска ключей и записей переменного размера. Поэтому тот критерий, что в каждой странице B-дерева содержится не меньше n и не больше 2*n ключей, становится неприменимым.
Широкое практическое применение получила модификация механизма B-деревьев, которую принято называть B+-деревьями. Эти деревья похожи на обычные B-деревья. Они тоже сильно ветвистые, и длина пути от корня к любой листовой странице одна и та же. Но структура внутренних и листовых страниц различна. Внутренние страницы устроены так же, как у B-дерева, но в них хранятся только ключи (без записей) и ссылки на страницы-потомки. В листовых страницах хранятся все ключи, содержащиеся в дереве, вместе с записями, причем этот список упорядочен по возрастанию значения ключа (рисунок 6).
Поиск ключа всегда доходит до листовой страницы. Аналогично операции включения и исключения тоже начинаются с листовой страницы. Для применения переливания, расщепления и слияния используются критерии, основанные на уровне заполненности соответствующей страницы. Для более экономного и сбалансированного использования внешней памяти при реализации B+-деревьев иногда используют технику слияния трех соседних страниц в две и расщепления двух соседних страниц в три. Хотя B+-деревья хранят избыточную информацию (один ключ может храниться в двух страницах), они, очевидно, обладают меньшей глубиной, чем классические B-деревья, а для поиска любого ключа требуется одно и то же число обменов с внешней памятью.

(a) Структура внутренней страницы B+-дерева

(b) Структура листовой страницы B+-дерева
Рис. 5.6. Структуры страниц B+-дерева
Дополнительной полезной оптимизацией B+-деревьев является связывание листовых страниц в одно- или двунаправленный список. Это позволяет просматривать списки записей для заданного диапазона значений ключей с лишь одним прохождением дерева от корня к листу.
ЛЕКЦИЯ 24. ОБЗОР МАТЕРИАЛА
Цели и задачи лекции:обзор материала по дисциплине за семестр.
Основные вопросы:Концепция типов данных. Линейные структуры данных:списки, стеки, очереди, деки. Нелинейные структуры данных: нелинейные списки, деревья, графы. Поиск данных: последовательный поиск, быстрые методы поиска, поиск с использованием древовидных структур. Организация данных в файлах.
КОНСПЕКТ ЛЕКЦИЙ ПО ДИСЦИПЛИНЕ
«СТРУКТУРЫ И АЛГОРИТМЫ ОБРАБОТКИ ДАННЫХ»
(Часть 2. Семестр 4)
Для подготовки бакалавров по направленям:
654600 – «Информационные системы и технологии»
Дата добавления: 2018-05-02; просмотров: 818; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!