БАЙЄСОВСЬКИЙМЕТОД ПРИЙНЯТТЯ РІШЕНЬ
Вирішення задач діагностики і тестування в навчанні потребує врахування неконкретності відповідей тих хто навчається. Врахувати цю неконкретність дозволяє байєсовський метод прийняття рішень. Байєсовський метод має строге математичне обґрунтування, і на його основі можна реалізувати механізм вивода, що дозволяє вирішувати вказані вище задачі.
Байєсовський метод заснований на розумінні вірогідності деякої події як деякої оцінки, яка приписується цій події людиною і може змінюватись при надходженні будь-яких додаткових відомостей. Математичний фундамент цього методу складає теорема Байєса. Вона розглядає подію S з вірогідністю P(S)>0 і множину попарно несумісних подій 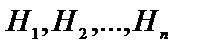 , повну в тому розумінні, що одна з цих подій неодмінно настане. Тоді, виходячи з теореми, вірогідність події
, повну в тому розумінні, що одна з цих подій неодмінно настане. Тоді, виходячи з теореми, вірогідність події 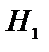 при умові, що наступила подія S, може бути розрахована по формулі:
при умові, що наступила подія S, може бути розрахована по формулі:
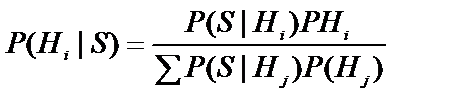 ,
,
де 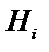 - апріорні (завчасно відомі) ймовірності гіпотез,
- апріорні (завчасно відомі) ймовірності гіпотез,
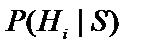 - апостеріорні (отримані в процесі) ймовірності гіпотез,
- апостеріорні (отримані в процесі) ймовірності гіпотез,
 - симптом,
- симптом,
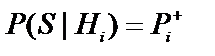 - вірогідність підтвердження гіпотези
- вірогідність підтвердження гіпотези  симптомом
симптомом  ,
,
 - вірогідність не підтвердження гіпотези
- вірогідність не підтвердження гіпотези 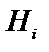 симптомом
симптомом 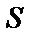 .
.
Для оцінки впливу симптому 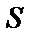 на гіпотезу
на гіпотезу 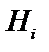 необхідно означити, симптом, наприклад, спитавши у користувача чи має місце подія
необхідно означити, симптом, наприклад, спитавши у користувача чи має місце подія 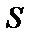 . Якщо подія має місце (відповідь «Так»), то для обрахування нової (апостеріорної) вірогідності
. Якщо подія має місце (відповідь «Так»), то для обрахування нової (апостеріорної) вірогідності 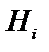 використовується формула:
використовується формула:

а якщо не має місце (відповідь «Ні»),то:
|
|
|
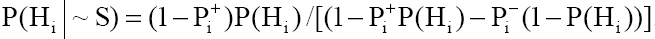
У випадку відповіді «Не знаю» апостеріорна ймовірність гіпотези  не змінюється.
не змінюється.
Можна побачити, що справедливе співвідношення:
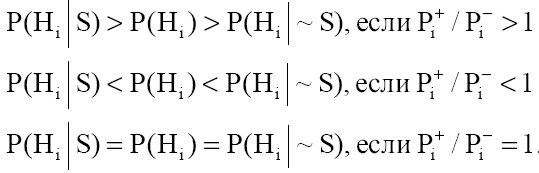
Для врахування невизначеності знання користувача при означувані симптомів необхідно розширити список його можливих відповідей. Це легко зробити користувачу означити симптом на шкалі від  до
до 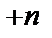 ,
, 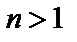 ,
, 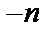 - відповідає відповіді «Ні», 0 - відповіді «Не знаю», а
- відповідає відповіді «Ні», 0 - відповіді «Не знаю», а 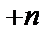 - відповіді «Так». Наприклад, при
- відповіді «Так». Наприклад, при 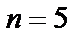 відповідь користувача «4» відповідала б степені впевненості «Дуже навіть може бути, що «Так», а відповідь «-3» - «схоже, що «Ні» . Значення апостеріорних вірогідностей в цьому випадку, обраховують використовуючи шматково-лінійну інтерполяцію між значеннями
відповідь користувача «4» відповідала б степені впевненості «Дуже навіть може бути, що «Так», а відповідь «-3» - «схоже, що «Ні» . Значення апостеріорних вірогідностей в цьому випадку, обраховують використовуючи шматково-лінійну інтерполяцію між значеннями 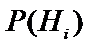 ,
, 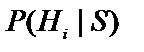 ,
, 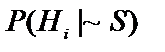 .
.
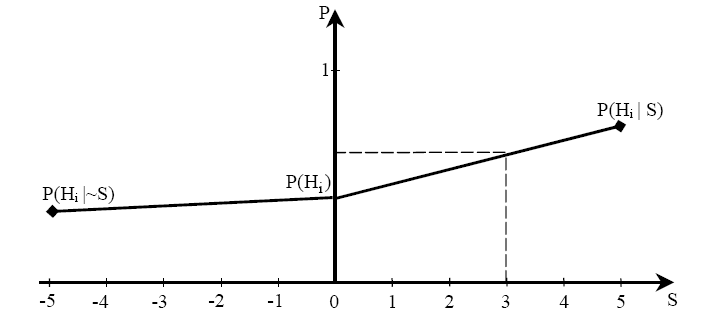
Рис. Для обліку невизначеностей знань користувача
2. Процес прийняття рішення для однієї гіпотези проходить наступним чином. Нехай 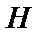 - гіпотеза, якій приписана апостеріорна вірогідність
- гіпотеза, якій приписана апостеріорна вірогідність 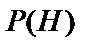 і яка залежить від симптомів
і яка залежить від симптомів 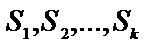 , де
, де 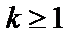 . З кожним симптомом
. З кожним симптомом  пов’язані дві вірогідності:
пов’язані дві вірогідності: 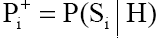 і
і 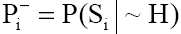 .
.
Перша вірогідність характеризує степінь участі симптому в даній гіпотезі (наприклад, вірогідність високої температури (симптом  ) при хворобі грип (гіпотеза
) при хворобі грип (гіпотеза 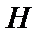 )), а друга вірогідність характеризує ступінь участі симптому в других гіпотезах (продовжуючи приклад, можна виділити, що це може бити вірогідність високої температури, якщо пацієнт хворий не грипом). Вірогідності
)), а друга вірогідність характеризує ступінь участі симптому в других гіпотезах (продовжуючи приклад, можна виділити, що це може бити вірогідність високої температури, якщо пацієнт хворий не грипом). Вірогідності 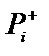 і
і 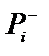 незалежні, тобто кожна із цих вірогідностей незалежно від другої може приймати значення від 0 до 1. Якщо значення
незалежні, тобто кожна із цих вірогідностей незалежно від другої може приймати значення від 0 до 1. Якщо значення 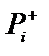 , як правило, можна оцінити використовуючи накопичені данні (історії хвороб, журнали обліку успіхів тощо), то значення
, як правило, можна оцінити використовуючи накопичені данні (історії хвороб, журнали обліку успіхів тощо), то значення 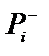 оцінити практично неможливо, тому оцінка
оцінити практично неможливо, тому оцінка 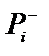 практично завжди залежить від експерта чи людини, яка відіграє роль експерта. Як випливає з формул
практично завжди залежить від експерта чи людини, яка відіграє роль експерта. Як випливає з формул
|
|
|
в баєвському методі вирішальну роль відіграє не абсолютне значення 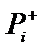 і
і 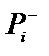 , а їх відношення
, а їх відношення 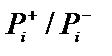 . Саме ці відношення на ряду з апріорними вірогідностями гіпотез і представляють собою експертні знання.
. Саме ці відношення на ряду з апріорними вірогідностями гіпотез і представляють собою експертні знання.
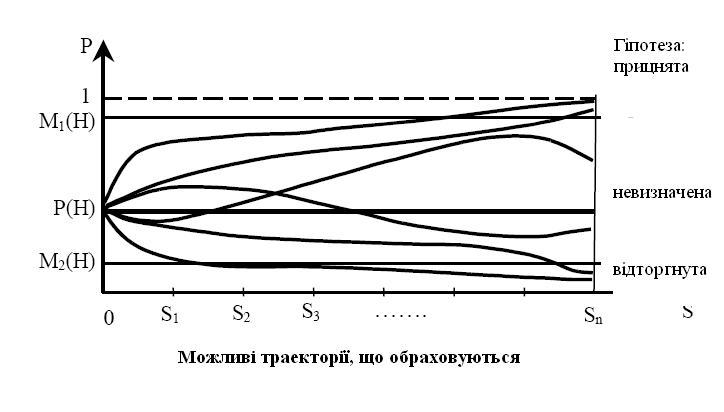
3. Симптоми означуються в порядку їх слідування, і за допомогою цих значень симптомів обраховується нове значення вірогідності гіпотези. Якщо на питання вірогідності гіпотези допустимі відповіді «Так», «Ні», «Не знаю», то всього буде 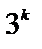 послідовностей можливих відповідей, які задають різні траєкторії обчислення. Якщо відповідати завжди так, щоб вірогідність збільшувалась (зменшувалась), то отримаємо траєкторію, яка приводить до максимальної (мінімальної) можливості вірогідності
послідовностей можливих відповідей, які задають різні траєкторії обчислення. Якщо відповідати завжди так, щоб вірогідність збільшувалась (зменшувалась), то отримаємо траєкторію, яка приводить до максимальної (мінімальної) можливості вірогідності 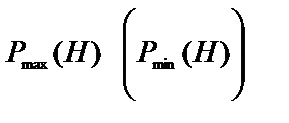 даної гіпотези. На основі максимальної і мінімальної вірогідності для кожної гіпотези встановлюються значення верхнього і нижнього порога визначеності гіпотези. Наприклад, в якості верхнього порога визначеності гіпотези
даної гіпотези. На основі максимальної і мінімальної вірогідності для кожної гіпотези встановлюються значення верхнього і нижнього порога визначеності гіпотези. Наприклад, в якості верхнього порога визначеності гіпотези 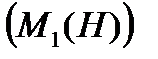 - можна взяти значення максимальної вірогідності, яке помножене на коефіцієнт 0,8, а в якості нижнього порогу визначеності
- можна взяти значення максимальної вірогідності, яке помножене на коефіцієнт 0,8, а в якості нижнього порогу визначеності 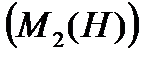 - значення максимальної вірогідності, яке помножено на коефіцієнт 0,2. Гіпотеза вважається прийнятною, якщо траєкторія, що обчислюється дає значення вірогідності гіпотези, таке що перевищує значення верхнього порогу, і відторгнутою, якщо значення вірогідності гіпотези менше значення нижнього порогу. Таким чином всі траєкторії, що обчислюються діляться на 3 класи траєкторія, що приводять до прийняття, відторгнення чи невизначеності гіпотези.
- значення максимальної вірогідності, яке помножено на коефіцієнт 0,2. Гіпотеза вважається прийнятною, якщо траєкторія, що обчислюється дає значення вірогідності гіпотези, таке що перевищує значення верхнього порогу, і відторгнутою, якщо значення вірогідності гіпотези менше значення нижнього порогу. Таким чином всі траєкторії, що обчислюються діляться на 3 класи траєкторія, що приводять до прийняття, відторгнення чи невизначеності гіпотези.
|
|
|
Додаток Г
ПЕРСЕПТРОНРОЗЕНБЛАТТА
Однієї з перших штучних мереж, здатних до перцепції (сприйняттю) і формуванню реакції на сприйнятий стимул, з'явився PERCEPTRON Розенблатта (F.Rosenblatt, 1957). Персептрон розглядався його автором не як конкретний технічний обчислювальний пристрій, а як модель роботи мозку. Потрібно помітити, що після декількох десятиліть досліджень сучасні роботи зі штучних нейронних мереж рідко переслідують таку мету.
|
|
|
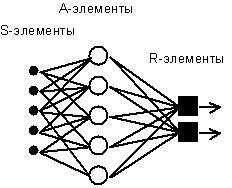
Рис. 1. Елементарний персептрон Розенблатта.
Найпростіший класичний персептрон містить нейроподібні елементи трьох типів (див. Рис. 1), призначення яких у цілому відповідає нейронам рефлекторної нейронної мережі. S-елементи формують сітківку сенсорних кліток, що приймають двійкові сигнали від зовнішнього миру. Далі сигнали надходять у шар асоціативних або A-елементів (для спрощення зображення частина зв'язків від вхідних S-кліток до A-кліток не показана). Тільки асоціативні елементи, що представляють собою формальні нейрони, виконують нелінійну обробку інформації й мають змінювані ваги зв'язків. R-елементи з фіксованими вагами формують сигнал реакції персептрона на вхідний стимул.
Розенблатт називав таку нейронну мережу тришарової, однак по сучасній термінології, представлена мережа звичайно називається одношарової, тому що має тільки один шар нейропроцесорних елементів. Одношаровий персептрон характеризується матрицею синаптических зв'язків W від S- до A-елементів. Елемент матриці відповідає зв'язку, що веде від і-го S-елемента до j-му A-елемента.
У Корнельской авіаційної лабораторії була розроблена електротехнічна модель персептрона MARK-1, що містила 8 вихідних R-елементів й 512 A-елементів, які можна було з'єднувати в різних комбінаціях. На цьому персептроні була проведена серія експериментів по розпізнаванню букв алфавіту й геометричних образів.
У роботах Розенблатта був зроблений висновок про те, що нейронна мережа розглянутої архітектури буде здатна до відтворення будь-якої логічної функції, однак, як було показано пізніше М. Мінським і С. Пейпертом (M.Mіnsky, S.Papert, 1969), цей висновок виявився неточним. Були виявлені принципові непереборні обмеження одношарових персептронів, і в наслідку став в основному розглядатися багатошаровий варіант персептрона, у якому є кілька шарів процесорних елементів.
Із сьогоднішніх позицій одношаровий персептрон представляє скоріше історичний інтерес, однак на його прикладі можуть бути вивчені основні поняття й прості алгоритми навчання нейронних мереж.
Теорема про навчання персептрона.
Навчання мережі складається в підстроюванні вагових коефіцієнтів кожного нейрона. Нехай є набір пар векторів (xa, ya), a= 1..p, називаний навчальною вибіркою. Будемо називати нейронну мережу навченої на даній навчальній вибірці, якщо при подачі на входи мережі кожного вектора xa, на виходах щораз виходить відповідний вектор ya.
Запропонований Ф.Розенблаттом метод навчання складається в ітераційному підстроюванні матриці ваг, що послідовно зменшує помилку у вихідних векторах. Алгоритм включає кілька кроків:
| Крок 0. | Початкові значення ваг всіх нейронів  покладаються випадковими. покладаються випадковими.
|
| Крок 1. | Мережі пред'являється вхідний образ xa, у результаті формується вихідний образ 
|
| Крок 2. | Обчислюється вектор помилки  , що робиться мережею на виході. Подальша ідея полягає в тому, що зміна вектора вагових коефіцієнтів в області малих помилок повинне бути пропорційно помилці на виході, і дорівнює нулю якщо помилка дорівнює нулю. , що робиться мережею на виході. Подальша ідея полягає в тому, що зміна вектора вагових коефіцієнтів в області малих помилок повинне бути пропорційно помилці на виході, і дорівнює нулю якщо помилка дорівнює нулю.
|
| Крок 3. | Вектор ваг модифікується по наступній формулі: 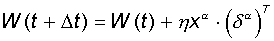 .
Тут .
Тут  - темп навчання. - темп навчання.
|
| Крок 4. | Кроки 1-3 повторюються для всіх навчальних векторів. Один цикл послідовного пред'явлення всієї вибірки називається епохою. Навчання завершується після закінчення декількох епох: а) коли ітерації зійдуться, тобто вектор ваг перестає змінюватися; б) коли повна сумування по всіх векторах абсолютна помилка стане менше деякого малого значення. |
Використовувана на кроці 3 формула враховує наступні обставини:
а) модифікуються тільки компоненти матриці ваг, що відповідають ненульовим значенням входів;
б) знак приросту ваги відповідає знаку помилки, тобто позитивна помилка (d> 0, значення виходу менше необхідного) проводить до посилення зв'язку;
в) навчання кожного нейрона відбувається незалежно від навчання інших нейронів, що відповідає важливому з біологічної точки зору, принципу локальності навчання.
Даний метод навчання був названий Ф. Розенблаттом “методом корекції зі зворотною передачею сигналу помилки”. Пізніше більш широко стала відомо назва “d - правило ”. Представлений алгоритм ставиться до широкого класу алгоритмів навчання із учителем, оскільки відомі як вхідні вектора, так і необхідні значення вихідних векторів (є вчитель, здатний оцінити правильність відповіді учня).
Доведена Розенблаттом теорема про збіжність навчання по d - правилу говорить про те, що персептрон здатний навчиться будь-якому навчальному набору, що він здатний представити.
Додаток Д
БАГАТОШАРОВИЙ ПЕРСЕПТРОН
Розглянемо ієрархічну мережеву структуру, у якій зв'язані між собою нейрони (вузли мережі) об'єднані в кілька шарів (Рис. 1). На можливість побудови таких архітектур указав ще Ф.Розенблатт, однак їм не була вирішена проблема навчання. Міжнейронні синаптичні зв'язки мережі влаштовані таким чином, що кожен нейрон на даному рівні ієрархії приймає й обробляє сигнали від кожного нейрона більше низького рівня. Таким чином, у даній мережі є виділений напрямок поширення нейроімпульсів - від вхідного шару через один (чи декілька) прихованих шарів до вихідного шару нейронів. Нейромережу такої топології ми будемо називати узагальненим багатошаровим персептроном або, якщо це не буде викликати непорозумінь, просто персептроном.
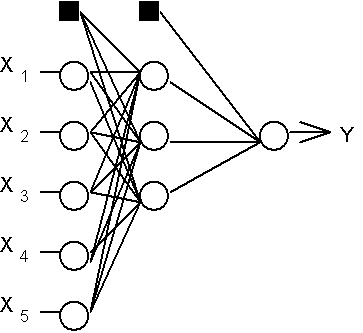
Рис.1. Структура багатошарового персептрона з п'ятьма входами, трьома нейронами в схованому шарі, і одним нейроном вихідного шару.
Персептрон представляє собою мережу, що складається з декількох послідовно з'єднаних шарів формальних нейронів МакКаллока й Питтса. На нижчому рівні ієрархії перебуває вхідний шар, що складається із сенсорних елементів, задачею якого є тільки прийом і поширення по мережі вхідної інформації. Далі є один або, рідше, кілька схованих шарів. Кожен нейрон на схованому шарі має кілька входів, з'єднаних з виходами нейронів попереднього шару або безпосередньо із вхідними сенсорами X1..Xn, і один вихід. Нейрон характеризується унікальним вектором вагових коефіцієнтів w. Ваги всіх нейронів шаруючи формують матрицю, що ми будемо позначати V або W. Функція нейрона складається в обчисленні зваженої суми його входів з подальшим нелінійним перетворенням її у вихідний сигнал:
 (5.1)
(5.1)
Виходи нейронів останнього, вихідного, шару описують результат класифікації Y=Y(X). Особливості роботи персептрона полягають у наступному. Кожен нейрон підсумовує сигнали, що до нього поступили від нейронів попереднього рівня ієрархії з вагами, обумовленими станами синапсів, і формує відповідний сигнал (переходить у збуджений стан), якщо отримана сума вище граничного значення. Персептрон перетворює вхідний образ, що визначає ступені порушення нейронів самого нижнього рівня ієрархії, у вихідний образ, обумовлений нейронами самого верхнього рівня. Число останніх, звичайно, порівняно невелике. Стан порушення нейрона на верхньому рівні говорить про приналежність вхідного образа до тієї або іншої категорії.
Традиційно розглядається аналогова логіка, при якій припустимі стани синаптичних зв'язків визначаються довільними дійсними числами, а ступені активності нейронів - дійсними числами між 0 й 1. Іноді досліджуються також моделі з дискретною арифметикою, у якій синапс характеризується двома булевими змінними: активністю (0 або 1) і полярністю (-1 або +1), що відповідає тризначній логіці. Стану нейронів можуть при цьому описуватися однієї булевої змінної. Даний дискретний підхід робить конфігураційний простір станів нейронної мережі кінцевим (не говорячи вже про переваги при апаратній реалізації).
Дата добавления: 2018-04-15; просмотров: 361; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!