Статистическое кодирование
Методы статистического кодирования явным образом опираются на теорему Шеннона. Такие методы включают в себя два этапа: оценка вероятности кодируемых элементов (моделирование) и собственно кодирование.
Словарное сжатие
Идея словарного сжатия заключается в замене последовательностей элементов исходных данных на идентификаторы таких фраз некоторого словаря, которые совпадают с замещаемой последовательностью. Методы словарного сжатия построены на использовании факта повторяемости строк символов. Словарь как совокупность фраз может строиться различным образом.
Сжатие табличных данных: метод Хаффмана.
Суть: Вместо того чтобы кодировать все символы одинаковым числом бит, будем кодировать символы, которые встречаются чаще, меньшим числом бит, чем те, которые встречаются реже. Более того, потребуем, чтобы код был оптимален или, другими словами, минимально-избыточен.
Алгоритм: На первом проходе строится частотный словарь и генерируются коды. На втором проходе происходит непосредственно кодирование.
Определение 1: Пусть A={a1,a2,...,an} - алфавит из n различных символов, W={w1,w2,...,wn} - соответствующий ему набор положительных целых весов. Тогда набор бинарных кодов C={c1,c2,...,cn}, такой что:
| (1) | ci не является префиксом для cj, при i!=j |
| (2) | 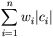
| минимальна (|ci| длина кода ci) |
называется минимально-избыточным префиксным кодом или иначе кодом Хаффмана.
Дата добавления: 2015-12-16; просмотров: 38; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!