КОРРЕЛЯЦИОННЫЙ И РЕГРЕССИОННЫЙ АНАЛИЗ В EXCEL
Цель работы – научиться использовать возможности MS Excel для проведения корреляционного и регрессионного анализа иссле- довательских данных.
5.1. Краткое изложение основных теоретических и методических аспектов работы
Параметрический корреляционный анализ
Одна из наиболее распространенных задач статистического исследования состоит в изучении связи между выборками (набо- рами числовых данных каких-либо величин). Обычно связь меж- ду выборками носит не функциональный, а вероятностный (или стохастический) характер. В этом случае нет строгой, однозначной зависимости между величинами. При изучении стохастических за- висимостей различают корреляцию и регрессию.
|
Y. Существует несколько типов коэффициентов корреляции, при- менение которых зависит от измерения (способа шкалирования) величин X и Y.
Для оценки степени взаимосвязи величин X и Y, измеренных в количественных шкалах, используется коэффициент линейной корреляции (коэффициент Пирсона), предполагающий, что вы- борки X и Y распределены по нормальному закону.
Линейный коэффициент корреляции – параметр, который ха- рактеризует степень линейной взаимосвязи между двумя выборка- ми, рассчитывается по формуле
|
|
|

 å(x i - x)× (y i - y)
å(x i - x)× (y i - y)
 r xy = , (5.1)
r xy = , (5.1)
|
|

 маемые в выборке Y; x – средняя по X; y – средняя по Y.
маемые в выборке Y; x – средняя по X; y – средняя по Y.
Коэффициент корреляции изменяется от -1 до 1. Когда при расчете получается величина большая +1 или меньшая -1 – следо- вательно, произошла ошибка в вычислениях. При значении 0 ли- нейной зависимости между двумя выборками нет.
Знак коэффициента корреляции очень важен для интерпретации полученной связи (табл. 1). Если знак коэффициента линейной кор- реляции «+», то связь между коррелирующими признаками такова,
что большей величине одного признака (переменной) соответствует
большая величина другого признака (другой переменной). Иными словами, если один показатель (переменная) увеличивается, то, со- ответственно, увеличивается и другой показатель (переменная). Та- кая зависимость носит название прямо пропорциональной.
Таблица 1
Теснота связи и величина коэффициента корреляции
| Коэффициент корреляции r xy | Теснота связи | ||
| +(0,91…1,00) | Очень сильная | ||
| +(0,81…0,90) | Весьма сильная | ||
| +(0,65…0,80) | Сильная | ||
| +(0,45…0,64) | Умеренная | ||
| +(0,25…0,44) | Слабая | ||
| До + 0,25 | Очень слабая | ||
| «+» – прямая зависимость; «–» – обратная зависимость
| |||
Если же получен знак «–», то большей величине одного при- знака соответствует меньшая величина другого. Иначе говоря, при наличии знака минус, увеличению одной переменной (признака, значения) соответствует уменьшение другой переменной. Такая за- висимость носит название обратно пропорциональной.
T-статистика Стьюдента
Для того чтобы оценить наличие связи между двумя перемен- ными, также можно использовать t-статистику Стьюдента, которая оценивает отношение величины линейного коэффициента корре- ляции к среднему квадратическому отклонению и рассчитывается по формуле
t расч
r xy ×
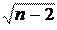
 =
=
. (5.2)
Полученную величину tрасч сравнивают с табличным значением tтабл критерия Стьюдента с n – 2 степенями свободы. Если tрасч > tтабл, то практически невероятно, что найденное значение обусловлено только случайными совпадениями величин X и Y в выборке из ге- неральной совокупности, т. е. существует зависимость между X и Y. И наоборот, если tрасч < tтабл, то величины X и Y независимы.
|
|
|
Исследование связей между двумя переменными в Excel
Условие задачи: По 10 интернет-магазинам были определены затраты на рекламную раскрутку сайтов и количество покупателей, воспользовавшихся после ее проведения услугами каждого мага- зина. Определить коэффициент корреляции между исследуемыми признаками.
Ход выполнения
1. Открываем новую книгу MS Excel и создаем таблицу соглас- но рис. 2.
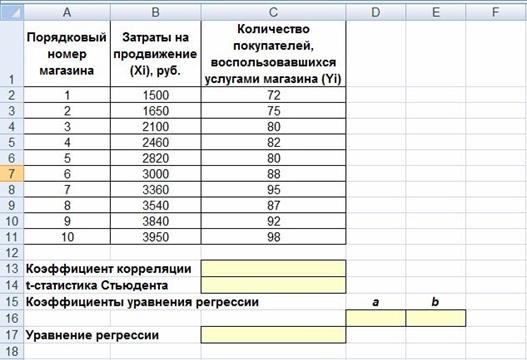 |
Рис. 2. Исходные данные для исследования связей между двумя переменными
2. Рассчитываем в ячейке С12 коэффициент корреляции, ис- пользуя функцию КОРРЕЛ из категории Статистические. Син- таксис функции: КОРРЕЛ (<массив 1>;<массив 2>), где <массив 1> – ссылка на диапазон ячеек первой выборки (X); <массив 2> – ссылка на диапазон ячеек второй выборки (Y).
В нашей задаче формула будет иметь вид: =КОРРЕЛ(B2:B11;C2: C11) (рис. 3).
 |
Рис. 3. Вычисление коэффициента корреляции
3. Сделаем вывод о тесноте связи между затратами на реклам- ную раскрутку сайтов и количеством покупателей.
После ввода формулы получаем в ячейке C13 значение коэф- фициента корреляции, равное 0,93. По табл. 2 делаем вывод, что связь между переменными очень сильная, т. е. имеет место линей- ная зависимость (прямая пропорциональность).
|
|
|
4. Оценим значимость коэффициента корреляции. С этой це-
|
|
ную Н : r
¹ 0. Для проверки гипотезы Н0 рассчитаем в ячейке С14
1 xy
t-статистику Стьюдента по формуле, указанной в п. 3.1.2. В нашем
случае число степеней свободы n = n – 2 = 10 – 2 = 8 и формула
будет следующей: =C13*КОРЕНЬ(10-2)/КОРЕНЬ(1-(C13*C13)). После ввода формулы получаем в ячейке C13 t-статистику Стью- дента (tрасч)? равную 7,12 (рис. 4).
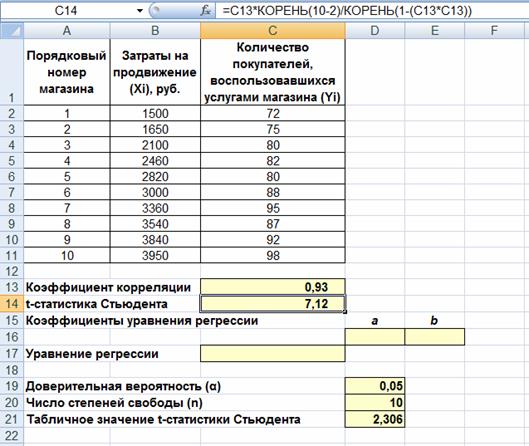 |
Рис. 4. Вычисление t-статистики Стьюдента (tрасч)
5. Сравним полученное значение с критическим значением tn,a,табл распределения Стьюдента (при n = 8 и доверительной вероят- ности a = 0,05, tn,a,табл = 2,306). tn,a,табл можно найтилибо в специальной таблице (прил. 1), либо воспользовавшись встроенной статистичес- кой функцией: СТЬЮДРАСПОБР(вероятность;степени_свободы). В нашем случае это будет формула: =СТЬЮДРАСПОБР(D19;D20-2).
6. Сделаем вывод о наличии связи между исследуемыми ве- личинами: так как tрасч > tn,a,табл (7,12 > 2,306), между переменны- ми существует зависимость и найденный коэффициент корреля- ции значим.
Регрессионный анализ
Цель регрессионного анализа – определить количественные связи между зависимыми случайными величинами. Одна из этих величин полагается зависимой и называется откликом, другие – независимые, называются факторами. Для установления степени зависимости между откликом и факторами используются вычисля- емые величины ковариации и коэффициент корреляции. Если ко- эффициент корреляции по абсолютной величине близок к едини- це, то для построения зависимости используется линейная модель. Для других случаев используются более сложные нелинейные мо- дели (например, полиномиальные и экспоненциальные). В данной работе изучим линейную модель.
Уравнение линейной регрессии имеет вид
Y = a1X1 + a2X2 + … + a k X k,
|
наименьших квадратов (МНК).
Обычно находят первые два параметра, которые принято обоз- начать a и b. В этом случае уравнение линейной регрессии имеет вид Y = a×X + b.
Коэффициенты a и b вычисляются следующим образом:
n n n
nå x i y i - å x i å y i
a = i = 1 i= 1 i= 1 ;
(5.3)
n æ n ö2
nå x2 - ç å x ÷
i
i =1
ç i ÷
è i =1 ø
n n
å y i å
x 2 -
n n
å x i å x i y i
|
(5.4)
n æ n ö2
nå x2 - çå x ÷
i
i=1
ç i ÷
è i=1 ø
|
|
мерении, n – число измерений при моделировании системы.
В среде MS Excel для нахождения моделирегрессии (т. е. фактичес- ки коэффициентов a и b) можно использовать несколько способов:
- использовать встроенную функцию ЛИНЕЙН;
- графический способ – построение линии тренда на диаграмме с показом уравнения регрессии;
- инструмент «Регрессия» из «Пакета анализа»;
- использовать встроенную функцию СУММКВРАЗН и инстру- мент «Поиск решения»;
- использовать встроенные функции НАКЛОН (вычисляет коэф- фициент a) и ОТРЕЗОК (вычисляет коэффициент b).
Построение регрессионной модели средствами Excel
Рассмотрим на примере первые три из перечисленных спосо- бов нахождения модели регрессии.
1-й способ. Функция ЛИНЕЙН
В первом способе для получения коэффициентов а и b линей- ного уравнения регрессии Y = a×X + b, описывающего зависимость количества привлеченных покупателей от затрат на рекламную рас- крутку сайтов, воспользуемся статистической функцией ЛИНЕЙН. Для этого выделите две ячейки D16:E16 и выполните вставку функ- ции ЛИНЕЙН с аргументами согласно рис. 5.
 |
Рис. 5. Аргументы функции ЛИНЕЙН
Здесь « Известные _ значения _y» – диапазон значений « Коли - чество покупателей », « Известные _ значения _x» – диапазон значе- ний « Затраты на продвижение ». Нажмите комбинацию клавиш SHIFT+CTRL+ENTER.
Получаем следующие значения коэффициентов регрессии –
a = 0,01 (ячейка D16), b = 59,32 (ячейка E16). В ячейку D17 введем
уравнение Y = 0,01×X + 59,31, чтобы продемонстрировать уравне- ние регрессии:
 |
2-й способ (графический). Построение линии тренда
1. Для получения уравнения регрессии построим корреляцион- ное поле переменных X (затраты на продвижение) и Y (количество покупателей).
2. Выделим диапазон ячеек В2:С11, запустим мастер диаграмм и выберем тип диаграммы – точечная (в Excel 2007 выберем на панели инструментов «Вставка» кнопку «Точечная» и подтип «То- чечная с маркерами», диаграмма будет создана и помещена на те- кущий лист, после чего ее можно будет дооформить). Задаем для диаграммы имя – « Корреляционное поле », название оси Х – « За - траты на продвижение , руб .», оси Y – « Количество покупателей » (в Excel 2007 данные действия выполняются на вкладке «Макет» после выделения диаграммы – команды «Название диаграммы» и «Названия осей»). На последнем шаге мастера указываем место расположения – текущий лист.
3. Добавим линию тренда на точечный график (рис. 6). Для этого необходимо выделить диаграмму и выполнить команду меню «Диа- грамма/Добавить линию тренда» (в Excel 2007 на вкладке «Макет» выберите команду «Анализ» и далее «Линия тренда» и «Линейное приближение»), либо выполнить данную команду из контекстного меню «Добавить линию тренда…», щелкнув по любой точке графи- ка правой кнопкой мыши. Линия тренда – графическое представ- ление направления изменения ряда данных.
4. Выбираем тип тренда «Линейный», который используется для аппроксимации данных по методу наименьших квадратов в со- ответствии с уравнением Y = a×X + b, где a – угол наклона (в радиа- нах) и b – координата пересечения оси абсцисс (оси Y).
5. На вкладке «Параметры» устанавливаем флажки «Показать уравнение на диаграмме» и «Поместить на диаграмму величину до- стоверности аппроксимации R2». Щелкаем по кнопке ОК. Далее
можно отформатировать эти уравнения, выделив их и в контекс- тном меню выбрав «Формат подписи линии тренда». R2 – это число от 0 до 1, которое отражает близость линии тренда к фактическим данным. Линия тренда наиболее соответствует действительности, когда значение близко к 1.
6. Сравниваем уравнение регрессии, полученное графическим методом, с уравнением, рассчитанным с помощью функции ЛИ- НЕЙН. Как видим, эти уравнения одинаковые.
 |
Рис. 6. Диаграмма с линией и уравнением тренда
3-й способ. Инструмент анализа «Регрессия»
1. Прежде чем мы начнем использовать этот инструмент, нужно убедиться, что был активизирован пакет анализа (вменю «Сервис» есть команда «Анализ данных»). Если нет, то выполните команду
«Сервис/Надстройки». В диалоговом окне «Надстройки» установите флажок «Пакет анализа» и щелкните по кнопке ОК (в Excel 2007 этот инструмент находится на вкладке «Данные» – «Анализ данных»).
2. Далее выполните команду «Сервис/Анализ данных». Вы- берите инструмент анализа «Регрессия» из списка «Инструменты анализа». Щелкните по кнопке ОК.
3. На экране появится диалоговое окно «Регрессия» (рис. 7):
- в текстовом поле «Входной интервал Y» введите диапазон со зна- чениями зависимой переменной $C$2:$C$211;
- в текстовом поле «Входной интервал Х» введите диапазон со зна- чениями независимых переменных $В$2:$В$11;
- убедитесь, что в поле Уровень надежности введено 95% и пере- ключатель «Параметры вывода» установлен в положении «Но- вый рабочий лист»;
- щелкните по кнопке ОК.
4. В результате на новом листе будут отображены результаты ис- пользования инструмента «Регрессия» (рис. 8).
5. Среди полученных результатов после применения инструмен- та «Регрессия» есть столбец «Коэффициенты», содержащий значе- ние b в строке «Y-пересечение», а – в строке «Переменная Х1».
6. Сравним полученные результаты с ранее рассчитанными ко- эффициентами a и b – они полностью совпадают.
7. Следует обратить также внимание на следующие показатели:
1) столбец «df» – число степеней свободы (используется при проверке адекватности модели по статистическим таблицам):
- в строке «Регрессия» находится k1 – количество коэффициентов уравнения, не считая свободного члена b;
- в строке «Остаток» находится k2 = n – k1 – 1, где n – количество исходных данных;
2) столбец «SS» (сумма квадратов):
-  в строке «Регрессия»:
в строке «Регрессия»:  , где – модельные
, где – модельные
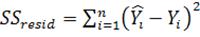 значения Y, полученные путем подстановки значений Х в пост- роенную модель;
значения Y, полученные путем подстановки значений Х в пост- роенную модель;  – среднее значение Y;
– среднее значение Y;
- в строке «Остаток»: ;
3) столбец «MS» – вспомогательные величины:
- в строке «Регрессия»:  ;
;
- в строке «Остаток»:  ;
;
4) столбец «F» – критерий Фишера. Используется для проверки адекватности модели:  ;
;
5) столбец « Значимость F» – оценка адекватности построенной модели. Находится по значениям F и с помощью функции FРАСП. Если значимость F меньше 0,05, то модель может считаться адек- ватной с вероятностью 0,95;
6) « Стандартная ошибка », «t- статистика » – это вспомогатель- ные величины, используемые для проверки значимости коэффи- циентов модели;
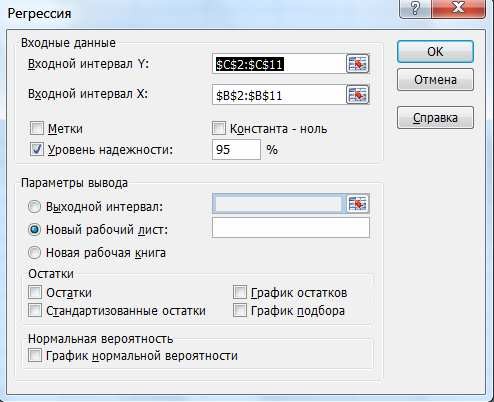
Рис. 7. Диалоговое окно инструмента анализа «Регрессия»
 |
Рис. 8. Вывод итогов инструмента «Регрессия»
7) « Р - Значение » – оценка значимости коэффициентов модели. Если «Р-Значение» меньше 0,05, то с вероятностью 0,95 можно считать, что соответствующий коэффициент модели значим (т. е. его нельзя считать равным нулю и Y значимо зависит от соответс- твующего Х);
9) нижние и верхние 95% – доверительные интервалы для ко- эффициентов модели.
Прогнозирование данных
Кроме нахождения уравнения регрессии, часто необходимо на основании этого уравнения предсказать теоретические значения Y при известных значениях X.
Это можно сделать тремя способами (рис. 9).
 |
Рис. 9. Исходные данные для прогнозирования
Способ 1. Создать в Excel обычную формулу, основанную на уравнении регрессии Y = a×X + b, типа C13=$A$19*B13+$B$19, где C13 – адрес ячейки c прогнозным значением функции Y, B13 – ад- рес ячейки со значением переменной X, для которого мы хотим спрогнозировать значение Y, $A$19 – абсолютный адрес ячейки со значением коэффициента a, $B$19 – абсолютный адрес ячейки со значением коэффициента b. В нашем случае нужно округлить до целого с помощью функции ОКРУГЛ($A$19*B13+$B$19;0). После чего скопируем формулу в ячейки С14 и С15.
Способ 2. Также можно вычислить теоретическое значение Y при X из ячейки B13 с помощью функции ПРЕДСКАЗ. Ее синтак- сис – ПРЕДСКАЗ(Xi;<массив Y>;<массив X>). Аргумент X i – это точка данных из массива X, для которой предсказывается теорети-
|
Способ 3. Еще один способ прогнозирования – вычислить значения уравнения линейной регрессии Y для целого диапазона значений независимой переменной X с помощью функции ТЕН- ДЕНЦИЯ. Ее синтаксис – ТЕНДЕНЦИЯ(<массив Y>;<массив X>;<новые значения X>;[<константа>]). Аргумент <новые значе- ния X > – это массив значений X, для которых функция ТЕНДЕН- ЦИЯ возвращает соответствующие значения Y. Новые значения зависимой переменной вычислим в ячейках E13:B15 по формуле
=ТЕНДЕНЦИЯ(E3:E12;B3:B12;B13:B15). Важно оформить эту функцию в ячейках E13:E15 как массив, для чего после ввода фор- мулы в ячейку B12 нажать клавишу ENTER, выделить ячейки E13: E15, нажать клавишу F2, после этого нажать комбинацию клавиш SHIFT+CTRL+ENTER.
Сравним полученные результаты для всех трех способов (рис. 10). Видим, что все три способа дают одинаковые результаты, что не уди- вительно, так как во всех случаях используется линейная регрессия.
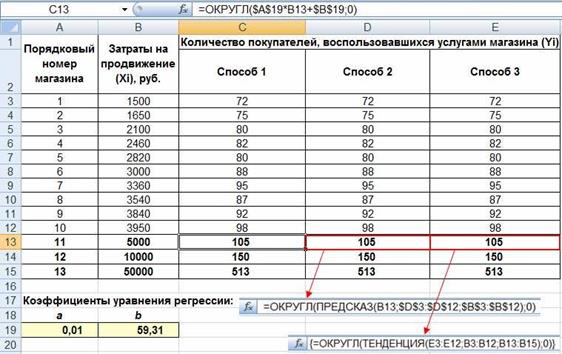 |
Рис. 10. Результаты прогнозирования тремя способами
Контрольные вопросы
1. В чем цель корреляционного анализа?
2. Что такое коэффициент корреляции?
3. Для чего используется t-статистика Стьюдента?
4. Какими способами можно определить коэффициент корреляции в MS Excel?
5. В чем цель регрессионного анализа?
6. Опишите уравнение линейной регрессии.
7. Какими способами можно найти модель регрессии в MS Excel?
Коротко опишите эти способы.
8. В чем задача прогнозирования данных?
9. Какими способами осуществить прогнозирование в MS Excel?
5.2. Порядок выполнения задания
1. Перед выполнением задания изучить п. 5.1 практикума и от- ветить на контрольные вопросы.
2. Открыть новую книгу Excel и сохранить под именем «Стат-
функции.xls».
3. В книге выполнить задание со следующими условиями. Имеются данные по двум экономическим показателям X и Y:
| Цена (X) | 995 | 983 | 1001 | 1012 | 1011 | 1017 | 978 | 997 | 1010 | 989 | 900 | 1100 | 5000 |
| Спрос (Y) | 122 | 144 | 114 | 100 | 100 | 90 | 150 | 130 | 95 | 155 | ? | ? | ? |
Необходимо:
- вычислить коэффициент корреляции;
- построить корреляционное поле (диаграмму) на отдельном листе;
- построить регрессионную модель (с использованием функции ЛИНЕЙН);
- спрогнозировать значение Y для трех новых значений X с помо- щью функции ПРЕДСКАЗ.
Все действия (в том числе форматирование таблицы) необходи- мо выполнять, опираясь на образец.
4. На диаграмме разместить линию тренда с уравнением рег- рессии и оформить их как показано в образце. Дополнить диаграм- му спрогнозированными данными (кроме последнего значения цены – 5000).
5. Используя инструмент «Регрессия», на отдельном листе пос- троить регрессионную модель с учетом новых спрогнозированных значений. Записать на листе уравнение регрессии на основании данных из «Вывода итогов».
6. Направить файл с выполненной работой преподавателю для
оценки.
5.3. Требования к оформлению, процедура защиты
Отчет о данной работе должен содержать распечатку каждого листа книги «Статфункции.xls». При защите необходимо дать тре- буемые пояснения к содержанию каждого листа книги, продемонс- трировать выполнение работы в файле книги «Статфункции.xls» и ответить на контрольный вопрос.
Практическая работа 6
Дата добавления: 2021-02-10; просмотров: 253; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!