Проверить выполнимость предпосылок МНК.
ВАРИАНТ № 4.
Для анализа зависимости объема потребления y (д.е.) домохозяйства от располагаемого дохода х (д.е.)отобрана выборка n = 10.
| у | 120 | 112 | 133 | 123 | 126 | 140 | 131 | 133 | 114 | 120 |
| х | 88 | 87 | 110 | 101 | 93 | 118 | 93 | 111 | 93 | 102 |
1. Оценить силу линейной зависимости между х и y .
Оценить значимость коэффициента линейной корреляции при уровне значимости б = 10%.
Для оценки тесноты линейной зависимости между х и y вычислим коэффициент корреляции по формуле:


Представим исходные данные и расчетные показатели в виде расчетной таблицы.
Таблица 1
| № п/п | х | y | x 2 | xy | y2 |
| 1 | 88 | 120 | 7744 | 10560 | 14400 |
| 2 | 87 | 112 | 7569 | 9744 | 12544 |
| 3 | 110 | 133 | 12100 | 14630 | 17689 |
| 4 | 101 | 123 | 10201 | 12423 | 15129 |
| 5 | 93 | 126 | 8649 | 11718 | 15876 |
| 6 | 118 | 140 | 13924 | 16520 | 19600 |
| 7 | 93 | 131 | 8649 | 12183 | 17161 |
| 8 | 111 | 133 | 12321 | 14763 | 17689 |
| 9 | 93 | 114 | 8649 | 10602 | 12996 |
| 10 | 102 | 120 | 10404 | 12240 | 14400 |
| Сумма | 996 | 1252 | 100210 | 125383 | 157484 |
| Среднее | 99,6 | 125,2 | 10021 | 12538,3 | 1574,84 |
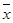
| 
| 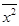
| 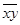
| 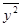
|
Имеем:
уx2 =  -
- 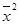 = 10021 – 99,62 = 100,84;
= 10021 – 99,62 = 100,84;
уy2 = -  = 15748,4 – 125,22 = 73,36
= 15748,4 – 125,22 = 73,36
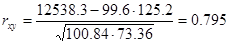
Значение коэффициента корреляции позволяет сделать вывод о достаточно тесной (прямой) линейной зависимости х и y.
Для проверки значимости коэффициента корреляции вычислим наблюдаемое значение статистики.

При б = 0,1, k = n – 2 = 8 по таблицам критических точек распределения Стьюдента находим t кр. = 1,86. Поскольку 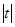 > t кр, то коэффициент корреляции r х y статистически значим, то есть имеется линейная зависимость между переменными x и y.
> t кр, то коэффициент корреляции r х y статистически значим, то есть имеется линейная зависимость между переменными x и y.
|
|
|
2. Построить линейную регрессионную модель: предварительно расположить значения y в порядке возрастания значений x .
По методу МНК на основе имеющихся данных
Рассчитать оценки параметров модели.
Согласно МНК для определения параметров a и b линейной регрессии ŷ = а + b х решаем систему нормальных уравнений вида:
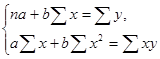
Решение системы:
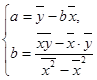
Представим исходные и расчетные данные в виде таблицы, предварительно расположив значения y в порядке возрастания значений х.
Таблица 2.
| № п/п | x | y | x2 | xy | y2 | ŷ | y - ŷ | (y–ŷ )2 | A | (y- )2
|
| 1 | 87 | 112 | 7569 | 9744 | 12544 | 116,656 | -4,656 | 21,68 | 4,16 | 174,24 |
| 2 | 88 | 120 | 7744 | 10560 | 14400 | 117,334 | 2,666 | 7,11 | 2,22 | 27,04 |
| 3 | 93 | 126 | 8649 | 11718 | 15876 | 120,724 | 5,276 | 27,84 | 4,19 | 0,64 |
| 4 | 93 | 131 | 8649 | 12183 | 17161 | 120,724 | 10,276 | 105,60 | 7,84 | 33,64 |
| 5 | 93 | 114 | 8649 | 10602 | 12996 | 120,724 | -6,724 | 45,21 | 5,90 | 125,44 |
| 6 | 101 | 123 | 10201 | 12423 | 15129 | 126,149 | -3,149 | 9,92 | 2,56 | 4,84 |
| 7 | 102 | 120 | 1044 | 12240 | 14400 | 126,827 | -6,827 | 46,61 | 5,69 | 27,04 |
| 8 | 110 | 133 | 12100 | 14630 | 17689 | 132,252 | 0,748 | 0,56 | 0,56 | 60,84 |
| 9 | 111 | 133 | 12321 | 14763 | 17689 | 132,930 | 0,070 | 0,005 | 0,05 | 60,84 |
| 10 | 118 | 140 | 13924 | 16520 | 19600 | 137,677 | 2,323 | 5,40 | 1,66 | 219,04 |
| Сумма | 996 | 1252 | 100210 | 125383 | 157484 | 1252 | 0,00 | 269,94 | 34,83 | 733,6 |
| Среднее | 99,6 | 125,2 | 10021 | 12538,3 | 15748,4 | 125,2 | 0,00 | 26,994 | 3,48 | 73,36 |
|
|
|
Находим:
b =  = 0,6781;
= 0,6781;
a = 125,2 – 0,6781·99,6 = 57,661
Уравнение парной линейной регрессии имеет вид:
ŷ = 57,661 + 0,6781х.
Подставляя в уравнение регрессии фактические значения х, определим теоретические (расчетные) значения ŷ (Таблица 2).
На одном чертеже отобразить график модели
И наблюдаемые значения.
Нанесем точки наблюдений (хi ; yi ), (где i = 1, 2, … 10) на декартову систему координат и отобразим график модели:
ŷ = 57,661 + 0,6781х. (рис. 1)
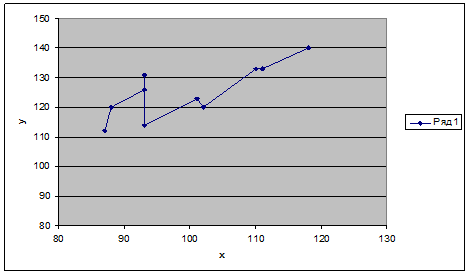
Рис. 1
4. Оценить качество уравнения регрессии:
а) Мерой общего качества уравнения регрессии является коэффициент детерминации R2 . В случае парной линейной регрессии
R2 = 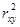
Получим: R2 = 0,7952 = 0,632
Таким образом, вариация зависимой переменной у – объема потребления – на 63,2% объясняется изменчивостью объясняющей переменной х – располагаемым доходом домохозяйства.
|
|
|
Значение коэффициента детерминации свидетельствует о достаточно хорошем общем качестве построенного уравнения регрессии.
б) Оценим на уровне б = 0,05 значимость уравнения регрессии.
Уравнение регрессии значимо, если наблюдаемое значение статистики
F = 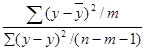 > Fб; k1; k2 ;
> Fб; k1; k2 ;
где Fб; k1; k2 - табличное значение F – критерия Фишера, определенное на уровне значимости б при k1 = m и k2 =n – m -1 степенях свободы (n – число наблюдений, m – число параметров при переменных x).
Вычислим необходимые суммы квадратов. В таблице 2 найдены:
У(у - ŷ)2 = 269,94
У(у - )2 = 733,6
У(ŷ - )2 = 733,6 – 269,94 = 463,66
Получим:
F = 
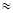 13,74
13,74
По таблице F – распределения F0,05;1;8 = 5,32.
Так как F > F0,05; 1; 8, то уравнение регрессии значимо, то есть достаточно качественно отражает динамику изменения зависимой переменной.
в) Рассчитаем величину средней ошибки аппроксимации по формуле:
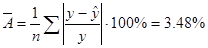
(Расчет представлен в Таблице 2)
То есть в среднем расчетные значения ŷ отклоняются от фактических у на 3,48%.
Величина 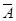 не превышает 5%, что говорит о хорошем подборе модели к исходным данным.
не превышает 5%, что говорит о хорошем подборе модели к исходным данным.
|
|
|
Проверить выполнимость предпосылок МНК.
Предпосылки МНК.
I . Случайное отклонение Еi есть величина случайная, а объясняющая переменная хi – величина не случайная. (i=1,2,…n).
II . Математическое ожидание случайного отклонения Еi равно нулю: М(Еi) = 0.
III . Дисперсия случайного отклонения постоянна для всех наблюдений: D(Еi) = D(Еj) = у2.
IV . Случайные отклонения Еi и Еj некоррелированы.
V . Случайное отклонение Еi - есть нормально распределенная случайная величина.
После оценки параметров модели разность фактических и теоретических значений зависимой переменной, то есть еi = уi - ŷ, определяет оценки случайного отклонение Еi (или остаток регрессии).
I . Проверим случайный характер остатков.
С этой целью строится график зависимости остатков еi от теоретических значений зависимой переменной ŷi. (рис. 2).
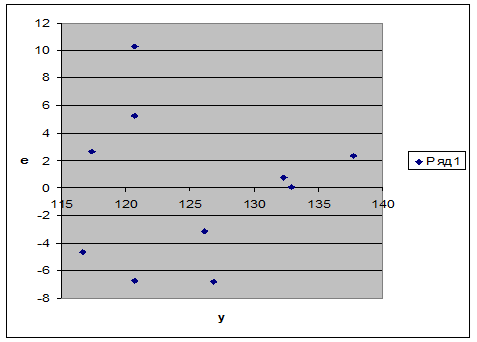
Рис. 2
На рисунке 2 остатки представляют собой случайные величины.
II . Вторая предпосылка МНК означает, что У (у - ŷ) = У еi = 0.
По данным таблицы 2, У (у - ŷ) = 0, то есть вторая предпосылка выполнена.
III . Дисперсия случайных отклонений Еi должна быть постоянной для всех наблюдений, то есть D(Еi) = D(Еj) = у2.
Выполнимость данного условия называется гомоскедастичностью, невыполняемость – гетероскедастичностью.
Наличие гетероскедастичности можно наглядно видеть из поля корреляции.
Поле корреляции представлено на рис. 1, на котором приведена зависимость переменной у от х, упорядоченных по возрастанию.
Представленная на рис. 1 диаграмма имеет пики, в целом подобный рисунок может соответствовать как гомо-, так и гетероскедастичной выборке. Чтобы определить, какая же именно ситуация имеет место, будем использовать тест ранговой корреляции Спирмена.
В качестве нулевой гипотезы H0 будем использовать гипотезу об отсутствии гетероскедастичности. Предполагается, что дисперсия случайного отклонения будет либо увеличиваться, либо уменьшаться с увеличением значений х, поэтому для регрессии, абсолютные величины остатков еi и значении хi будут коррелированны.
Значения еi и хi ранжируются (упорядочиваются по величинам) и определяется коэффициент ранговой корреляции:
схе=1 - 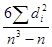
где di – разность между рангами еi и хi.
Представим исходные данные и расчетные показатели в виде таблицы.
Таблица 3.
| № п/п | х i . | 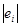
| Ранг х i . | Ранг е i |  d d 
|
| 1 | 87 | 4,656 | 1 | 6 | 25 |
| 2 | 88 | 2,666 | 2 | 4 | 4 |
| 3 | 93 | 5,276 | 4 | 7 | 9 |
| 4 | 93 | 10,276 | 4 | 10 | 36 |
| 5 | 93 | 6,724 | 4 | 8 | 16 |
| 6 | 101 | 3,149 | 6 | 5 | 1 |
| 7 | 102 | 6,827 | 7 | 9 | 4 |
| 8 | 110 | 0,748 | 8 | 2 | 36 |
| 9 | 111 | 0,070 | 9 | 1 | 64 |
| 10 | 118 | 2,323 | 10 | 3 | 49 |
| Сумма | - | - | - | - | 244 |
Находим: схе = 1 - 
Оценим значимость схе:
t = 
tkp (при б = 0,05; k = 8) = 2,31
Так как 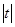 = 1,55 < tkp = 2,31, то схе – незначим, в этом случае гипотеза об отсутствии гетероскедастичности принимается (III предпосылка выполнена).
= 1,55 < tkp = 2,31, то схе – незначим, в этом случае гипотеза об отсутствии гетероскедастичности принимается (III предпосылка выполнена).
IV. Предпосылка – отсутствие автокорреляции остатков.
Оценим наличие автокорреляции с помощью статистики DW Дарбина – Уотсона:
DW =  ;
;
Составим расчетную таблицу.
Таблица 4.
| № п/п | е i | ei-1 | ( е i - ei-1)2 |
| 1 | -4,66 | - | - |
| 2 | 2,67 | -4,66 | 53,73 |
| 3 | 5,28 | 2,67 | 6,81 |
| 4 | 10,28 | 5,28 | 25 |
| 5 | -6,72 | 10,28 | 289 |
| 6 | -3,15 | -6,72 | 12,74 |
| 7 | -6,83 | -3,15 | 13,54 |
| 8 | 0,75 | -6,83 | 57,46 |
| 9 | 0,07 | 0,75 | 0,46 |
| 10 | 2,32 | 0,07 | 5,06 |
| Сумма | - | - | 463,8 |
Получим: DW = 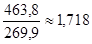
По таблице критических точек Дарбина – Уотсона при n = 10 и уровне значимости б = 0,05 критические значения dн = 0,879 и dВ = 1,32. То есть фактически найденное DW = 1,718 находится в пределах от dВ до 4 - dВ (1,32 < 1,718 < 2,68). В этом случае гипотеза об отсутствии автокорреляции не отклоняется, то есть имеются основания считать, что автокорреляция остатков отсутствует.
Дата добавления: 2019-02-12; просмотров: 185; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!