Оценка качества кластеризации
Оценка качества кластеризации может быть проведена на основе следующих процедур:
- ручная проверка;
- установление контрольных точек и проверка на полученных кластерах;
- определение стабильности кластеризации путем добавления в модель новых переменных;
- создание и сравнение кластеров с использованием различных методов. Разные методы кластеризации могут создавать разные кластеры, и это является нормальным явлением. Однако создание схожих кластеров различными методами указывает на правильность кластеризации.
- Дерево прийняття рішень як апроксимація булевської функції.
При помощи данного метода решаются задачи классификации и прогнозирования.
Если зависимая, т.е. целевая переменная принимает дискретные значения, при помощи метода дерева решений решается задача классификации.
Если же зависимая переменная принимает непрерывные значения, то дерево решений устанавливает зависимость этой переменной от независимых переменных, т.е. решает задачу численного прогнозирования.
В наиболее простом виде дерево решений - это способ представления правил в иерархической, последовательной структуре. Основа такой структуры - ответы "Да" или "Нет" на ряд вопросов.
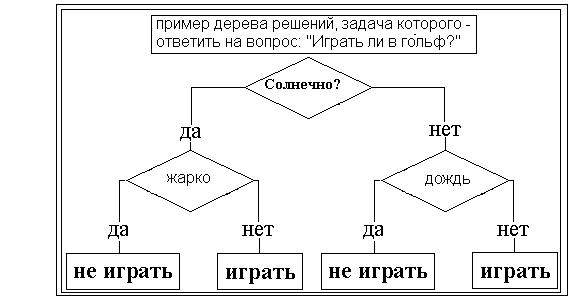
В результате прохождения от корня дерева (иногда называемого корневой вершиной) до его вершины решается задача классификации, т.е. выбирается один из классов - "играть" и "не играть".
|
|
|
Деревья принятия решений обычно используются для решения задач классификации данных или, иначе говоря, для задачи аппроксимации заданной булевой функции. Ситуация, в которой стоит применять деревья принятия решений, обычно выглядит так: есть много случаев, каждый из которых описывается некоторым конечным набором дискретных атрибутов, и в каждом из случаев дано значение некоторой (неизвестной) булевой функции, зависящей от этих атрибутов. Задача — создать достаточно экономичную конструкцию, которая бы описывала эту функцию и позволяла классифицировать новые, поступающие извне данные.
Дерево принятия решений — это дерево, на ребрах которого записаны атрибуты, от которых зависит целевая функция, в листьях записаны значения целевой функции, а в остальных узлах — атрибуты, по которым различаются случаи.
Чтобы классифицировать новый случай, надо спуститься по дереву до листа и выдать соответствующее значение.

- Дерева прийняття рішень. Ентропія, як характеристика цільової функції.
Для того чтобы получить оптимальные деревья принятия решений, нужно на каждом шаге выбирать атрибуты, которые «лучше всего» характеризуют целевую функцию. Это требование формализуется посредством понятия энтропии.
|
|
|
Определение 1.1. Предположим, что имеется множество А из n элементов, m из которых обладают некоторым свойством S. Тогда энтропия множества A по отношению к свойству S — это
| 1 |

Энтропия зависит от пропорции, в которой разделяется множество. По мере возрастания этой пропорции от 0 до 1 /2 энтропия тоже возрастает, а после 1 /2 — симметрично убывает.
Если свойство S не бинарное, а может принимать s различных значений, каждое из которых реализуется mi случаях, то энтропия обобщается:

Понятие энтропии тесно связано с теорией информации, энтропия — это среднее количество битов, которые требуются, чтобы закодировать атрибут S у элемента множества А. Если вероятность появления 5 равна 1/2, то энтропия равна 1, и нужен полноценный бит; а если S появляется не равновероятно, то можно закодировать последовательность элементов А более эффективно.
При выборе атрибута для классификации нужно выбирать его так, чтобы после классификации энтропия стала как можно меньше (свойство s в данном случае — значение целевой булевской функции). Энтропия при этом будет разной в разных потомках, и общую сумму нужно считать с учётом того, сколько исходов осталось в рассмотрении в каждом из потомков.
|
|
|
- Критерій приросту інформації. Проблеми з критерієм приросту інформації.
Определение 1.2. Предположим, что множество А элементов, некоторые из которых обладают свойством s, классифицировано посредством атрибута Q, имеющего q возможных значений. Тогда прирост информации (information gain) определяется как
Gain(А,Q)=Н(А,S) 
где Аi — множество элементов А, на которых атрибут Q имеет значение i.
На каждом шаге жадный алгоритм должен выбирать тот атрибут, для которого прирост информации максимален.


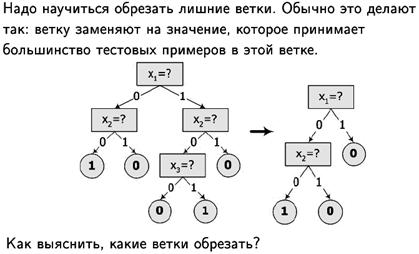
- Дерева прийняття рішень. Оверфіттінг.




- Генетичний алгоритм. Загальна схема генетичного алгоритма.
Работа ГА представляет собой итерационный процесс, который продолжается до тех пор, пока не
выполнятся заданное число поколений или какой-либо иной критерий останова. На каждом поколении
ГА реализуется отбор пропорционально приспособленности, кроссовер и мутация.
Алгоритм работы простого ГА выглядит следующим образом:

Рис. 1. Алгоритм работы классического ГА
- Генетична операція «кросовер».

Различают несколько видов кроссовера:
1. Одноточечный кроссовер
|
|
|
Оператор скрещивание (crossover) осуществляет обмен частями хромосом между двумя (может быть и больше) хромосомами в популяции. Может быть одноточечным или многоточечным. Одноточечный кроссовер работает следующим образом. Сначала, случайным образом выбирается одна из l-1 точек разрыва. Точка разрыва - участок между соседними битами в строке. Обе родительские структуры разрываются на два сегмента по этой точке. Затем, соответствующие сегменты различных родителей склеиваются и получаются два генотипа потомков.

2. Двухточечный кроссовер: выбираются 2 точки раздела, и родители обмениваются промежутками между ними:
010.1001.1011 -> 010.1011.1011110.1011.0100 110.1001.0100При этом определяющая длина измеряется в кольце – для шаблона 1*****1 при двухточечном кроссовере она будет равна 1, хотя при одноточечном была 6.
3. Однородный кроссовер: один из детей наследует каждый бит с вероятностью p0 у первого родителя и с (1 - p0) у второго, второй ребенок получает не унаследованные первым биты. Обычно p0 = 0.5.
Однородный кроссовер в большинстве случаев разрушает шаблон, поэтому плохо предназначен для отбора гиперплоскостей, однако при малом размере популяции он препятствует преждевременному схождению.
- Представлення даних у вигляді бітових рядків.
Наиболее распространённая операция мутации является инвертирование случайного бита строки
(Соперник = ниже)^(игра=дома)^(лидеры=есть)^(дождь=нет)=>Победа=true
[10101]
Допустим требуется закодировать несколько правил
[011001 001101] l1*n
[001101 111010 010011] l2*n
Т.е. требуется скрестить две строки длиной
l1*n и l2*n
n – длина правила
l1 и l2 - колличество правил закодированніх в правило.
Нужно получить другое правило
[011001][001101 111001 001110] l3*n
Если использовать двухточечный кроссовер и выбирает случайным образом 2 точки 1 гипотезы, то во второй гипотизе нужно выбирать также точки чтобы расстояние от левой точки до левого правого правила, а также растояние от правой точки до правого правила растояние должно быть одно и то же
[011001]
[001101 11001 001110 010011] l3*n
- Відбір, як основний елемент генетичного алгоритму.
Отбор в генетичиском алгоритме производится на основе функции приспособлености

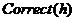 - колличество примеров которые правильно распредены гипотизей.
- колличество примеров которые правильно распредены гипотизей.
TotalExamples – общее колличество примеров
- Покажіть на прикладі «метод рулетки» та «ранговий метод», як методи відбору генетичного алгоритму.
Метод рулетки (roulette-wheel selection) - отбирает особей с помощью n "запусков" рулетки. Колесо рулетки содержит по одному сектору для каждого члена популяции. Размер i-ого сектора пропорционален соответствующей величине Psel(i) вычисляемой по формуле:

При таком отборе члены популяции с более высокой приспособленностью с большей вероятностью будут чаще выбираться, чем особи с низкой приспособленностью.
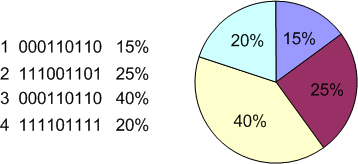
Рис. 1. Оператор селекции типа колеса рулетки
с пропорциональными функции приспособленности секторами
- Відображення теорій Ламарка та Болдуіна у генетичних алгоритмах.


Практичні завдання.
- Побудова найпростішого дерева розв’язків на основі статистичної інформації.
- Побудова дерева розв’язків для заданої булевської функції. (Зверніть увагу на це питання!)
- Виконання кросоверу з різними масками для рядків однієї довжини.
- Виконання кросоверу для рядків різної довжини.
- Вибір атрибута для поділу дерева на основі критерію приросту інформації Gain.
- Вибір атрибута для поділу дерева на основі критерію приросту інформації GainRatio. (Зверніть увагу на це питання!)
- Відбір особин з популяції на основі методу рулетки.
- Відбір особин з популяції на основі рангового методу.
Дата добавления: 2018-05-12; просмотров: 635; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!