Интеллектуальный анализ данных
Nbsp; Питання до модульної контрольної роботи № 2 з курсу «Основи проектування інтелектуальних систем»
Теоретичні питання
- Процес набуття знань. Його мета, основні складнощі. Функції його учасників.
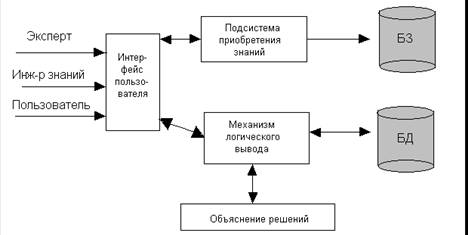
Експерт визначає знання (дані та правила), що характеризують проблемну область, забезпечує повноту та правильність введених в ЕС знань.
Інженер по знаннях допомагає експерту виявити і структурувати знання, необхідні для роботи ЕС; здійснює вибір того ІС, яке найбільш підходить для даної проблемної області, і визначає спосіб представлення знань у цьому ІС; виділяє і програмує (традиційними засобами) стандартні функції (типові для даної проблемної області), які будуть використовуватися в правилах, що вводяться експертом.
Програміст розробляє ІС (якщо ІВ розробляється заново), що містить в межі всі основні компоненти ЕС, і здійснює його пару з тим середовищем, в якій вона буде використана.
Термин извлечение знаний (knowledge elicitation) относится именно к одному из способов передачи знаний — опросу экспертов в определенной проблемной области, который выполняется аналитиком или инженером по знаниям. Последний затем создает компьютерную программу, представляющую такие знания (или поручает это кому-нибудь другому, обеспечивая его всей необходимой информацией).
Применяется и для обозначения процесса взаимодействия эксперта со специальной программой, целью которого является:
|
|
|
- извлечь каким-либо систематическим способом знания, которыми обладает эксперт, например, предлагая эксперту репрезентативные задачи и фиксируя предлагаемые способы их решения;
- сохранить полученные таким образом знания в некотором промежуточном виде;
- преобразовать знания из промежуточного представления в вид, пригодный для практического использования в программе, например в набор порождающих правил.
- Основні стадії процесу набуття знань та їх взаємодія.
Процесс приобретения знаний в терминах модели процесса проектирования экспертной системы:

Рис. 10.1. Стадии приобретения знаний
(1) Идентификация. Анализируется класс проблем, которые предполагается решать с помощью проектируемой системы, включая данные, которыми нужно оперировать, и критерии оценки качества решений. Определяются ресурсы, доступные при разработке проекта, — источники экспертных знаний, трудоемкость, ограничения по времени, стоимости и вычислительным ресурсам.
(2) Концептуализация. Формулируются базовые концепции и отношения между ними. Сюда же входят и характеристика различных видов используемых данных, анализ информационных потоков и лежащих в их основе структур в предметной области в терминах причинно-следственных связей, отношений частное/целое, постоянное/временное и т.п.
|
|
|
(3) Формализация. Предпринимается попытка представить структуру пространства состояний и характер методов поиска в нем. Выполняется оценка полноты и степени достоверности (неопределенности) информации и других ограничений, накладываемых на логическую интерпретацию данных, таких как зависимость от времени, надежность и полнота различных источников информации.
(4) Реализация. Преобразование формализованных знаний в работающую программу, причем на первый план выходит спецификация методов организации управления процессом и уточнение деталей организации информационных потоков. Правила преобразуются в форму, пригодную для выполнения программой в выбранном режиме управления. Принимаются решения об используемых структурах данных и разбиении программы на ряд более или менее независимых модулей.
(5) Тестирование. Проверка работы созданного варианта системы на большом числе репрезентативных задач. В процессе тестирования анализируются возможные источники ошибок в поведении системы. Чаще всего таким источником является имеющийся в системе набор правил. Оказывается, что в нем не хватает каких-то правил, другие не совсем корректны, а между некоторыми обнаруживается противоречие.
|
|
|
- Види методів витягу знань з експерта.
1. Комунікативні методи – охоплюють методи і процедури контактів інженера зі знань з безпосереднім джерелом знань – експертом. Комунікативні методи поділяються на активні і пасивні.
1.1 Пасивні методи включають такі методи, де ведуча роль у процедурі витягу фактично передається експерту, а інженер зі знань тільки фіксує судження експерта під час роботи з прийняття рішень. До цієї групи відносяться: спостереження, аналіз протоколів "думок уголос" і лекції.
1.1.1 Метод спостереження полягає в тому, що інженер зі знань знаходиться безпосередньо поруч з експертом під час його професійної діяльності або імітації цієї діяльності. При підготовці до сеансу експерту необхідно пояснити мету спостережень і попросити його максимально коментувати свої дії; під час сеансу аналітик записує всі дії експерта і його пояснення. Рекомендується використовувати магнітофонний запис і відеозапис у реальному масштабі часу. Протоколи спостережень після сеансу ретельно розшифровуються, а потім обговорюються з експертом.
|
|
|
1.1.2 Метод протоколювання "думок уголос" полягає в тому, що експерта просять не тільки прокоментувати свої дії і рішення але й пояснити, як це рішення було знайдено. Іноді цей метод називають "вербальні звіти". Основними труднощами при протоколюванні "думок уголос" є принципова складність для людини пояснити, як вона думає, оскільки відомо, що люди не завжди здатні достовірно описувати розумові процеси.
1.1.3 Метод витягу знань у формі лекцій використовується при розробці бази знань як ефективний метод швидкого занурення інженера зі знань у предметну область. Курс лекцій звичайно дуже короткий і не перевищує 2–5 лекцій тривалістю до 1,5 годин кожна.
1.2 Активні методи витягу знань припускають, що ініціатива знаходиться цілком у руках інженера зі знань, який активно контактує з експертом різними способами. Активні методи підрозділяють на індивідуальні і групові.
1.2.1 Індивідуальні активні методи можна розділити на анкетування, інтерв’ю, вільний діалог та ігри з експертом.
1.2.1.1 Анкетування передбачає, що інженер зі знань заздалегідь складає запитальник або анкету, розмножує її і використовує для опитування декількох експертів. Експерт самостійно заповнює анкету після попереднього інструктування.
1.2.1.2. Інтерв’ю – специфічна форма спілкування інженера зі знань і експерта, у якій інженер зі знань задає експерту серію заздалегідь підготовлених питань з метою витягу знань про предметну область. На якість проведення інтерв’ю впливають три основних характеристики питання: мова питання (зрозумілість, лаконічність, термінологія), порядок питань (логічна послідовність і немонотонність), доречність питань (етика, увічливість).
1.2.1.3 Вільний діалог – метод витягу знань у формі бесіди інженера зі знань і експерта, у якій немає твердого регламентованого плану і запитальника.
1.2.2 Групові методи витягу знань забезпечують можливість одночасного використання знань декількох експертів, взаємодія яких забезпечує принципову новизну одержуваної інформації від накладення різних поглядів і позицій. До групових методів відносяться дискусії за "круглим столом", "мозкові штурми" і рольові ігри.
1.2.2.1 Метод "круглого столу" передбачає обговорення якої-небудь проблеми з обраної предметної області, у якому беруть участь з рівними правами кілька експертів. Задача дискусії – колективно, з різних точок зору, під різними кутами досліджувати спірні гіпотези предметної області. Спочатку учасники висловлюються у визначеному порядку, а потім переходять до вільного обговорення.
1.2.2.2 "Мозковий штурм" – один з найбільш розповсюджених методів розкріпачення й активізації творчого мислення. Основна ідея штурму – це відділення процедури генерування ідей у замкнутій групі фахівців від процесу аналізу й оцінювання висловлених ідей. Тривалість "штурму" до 40 хвилин. Учасникам (до 10 осіб) пропонується висловити будь-які ідеї на задану тему (критику заборонено). Регламент – до 2 хвилин на виступ. При аналізі відповідей лише 10–15% ідей виявляються розумними, але серед них можуть бути дуже оригінальні. Оцінює результати група експертів
- Оболонки експертних систем. Система EMYSIN, як універсальна оболонка.
Оболочки экспертных систем
На раннем этапе становления экспертных систем проектирование каждой очередной системы начиналось практически с нуля, в том смысле, что проектировщики для представления знаний и управления их применением использовали самые примитивные структуры данных и средства управления, которые содержались в обычных языках программирования. В редких случаях в существующие языки программирования включались специальные языки представлений правил или фреймов.
Такие специальные языки, как правило, обладали двумя видами специфических средств:
- модулями представления знаний (в виде правил или фреймов);
- интерпретатором, который управлял активизацией этих модулей.
Совокупность модулей образует базу знаний экспертной системы, а интерпретатор является базовым элементом машины логического вывода. Невольно напрашивается мысль, что эти компоненты могут быть повторно используемыми, т.е. служить основой для создания экспертных систем в разных предметных областях. Использование этих программ в качестве базовых компонентов множества конкретных экспертных систем позволило называть их оболочкой системы.
Система EMYCIN
Примером такой оболочки может служить система EMYCIN, которая является предметно-независимой версией системы MYCIN, т.е. это система MYCIN, но без специфической медицинской базы знаний [van Melle, 1981]. (Само название EMYCIN толкуется авторами системы как "Empty MYCIN" , т.е. пустая MYCIN.) По мнению разработчиков, EMYCIN вполне может служить "скелетом" для создания консультационных программ во многих предметных областях, поскольку располагает множеством инструментальных программных средств, облегчающих задачу проектировщика конкретной экспертной консультационной системы. Она особенно удобна для решения дедуктивных задач, таких как диагностика заболеваний или неисправностей, для которых характерно большое количество ненадежных входных измерений (симптомов, результатов лабораторных тестов и т.п.), а пространство решений, содержащее возможные диагнозы, может быть достаточно четко очерчено.
Некоторые программные средства, впервые разработанные для EMYCIN, в дальнейшем стали типовыми для большинства оболочек экспертных систем. Среди таких средств следует отметить следующие.
- Язык представления правил. В системе EMYCIN такой язык использует систему обозначений, аналогичную языку ALGOL. Этот язык, с одной стороны, более понятен, чем LISP, а с другой— более строг и структурирован, чем тот диалект обычного английского, который использовался в MYCIN.
- Индексированная схема применения правил, которая позволяет сгруппировать правила, используя в качестве критерия группировки параметры, на которые ссылаются эти правила. Так, правила, применяемые в MYCIN, разбиваются на группы: CULRULES — правила, относящиеся к культурам бактерий, ORGRULES — правила, касающиеся организмов, и т.д.
- Использование обратной цепочки рассуждений в качестве основной стратегии управления. Эта стратегия оперирует с И/ИЛИ-деревом, чьи листья представляют собой данные, которые могут быть найдены в таблицах или запрошены пользователем.
- Интерфейс между консультационной программой, созданной на основе EMYCIN, и конечным пользователем. Этот компонент оболочки обрабатывает все сообщения, которыми обмениваются пользователь и программа (например, запросы программы на получение данных, варианты решения, которые формирует программа в ответ на запросы пользователя, и т.п.).
Интерфейс между разработчиком и программой, обеспечивающий ввод и редактирование правил, редактирование знаний, представленных в форме таблиц, тестирование правил и выполнение репрезентативных задач.
- Система TEIRESIAS як універсальний інтерфейс експертної системи.
В составе TEIRESIAS имеются и средства, которые помогают оболочке EMYCIN следить за поведением экспертной системы в процессе применения набора имеющихся правил.
- Режим объяснения (EXPLAIN). После выполнения каждого очередного задания — консультации — система дает объяснение, как она пришла к такому заключению. Распечатываются каждое правило, к которому система обращалась в процессе выполнения задания, и количественные параметры, связанные с применением этого правила, в том числе и коэффициенты уверенности.
- Режим тестирования (TEST). В этом режиме эксперт может сравнить результаты, полученные при прогоне отлаживаемой программы, с правильными результатами решения этой же задачи, хранящимися в специальной базе данных, и проанализировать имеющиеся отличия. Оболочка EMYCIN позволяет эксперту задавать системе вопросы, почему она пришла к тому или иному заключению и почему при этом не были получены известные правильные результаты.
- Режим просмотра (REVIEW). В этом режиме эксперт может просмотреть выводы, к которым приходила система при выполнении одних и тех же запросов из библиотеки типовых задач. Это помогает просмотреть эффект, который дают изменения, вносимые в набор правил в процессе наладки системы. В этом же режиме можно проанализировать, как отражаются изменения в наборе правил на производительности системы.
- Що таке дані? Набори даних, види даних.
Данные – это краткая информация, пригодная для дальнейшей обработки. Как правило, данные предоставляются в структурированном виде, через заполнение какой-либо формы.
Набор данных - это коллекция записей из одной или нескольких таблиц базы данных.
Наборы данных можно получить с помощью компонент TADOTable, TADOQuery или TADOStoredProc, который необходим для архитектуры клиент-сервер. Каким образом получаются наборы данных? Когда мы открываем таблицу, то есть, присваиваем True свойству Active компонента TADOTable, например, специальный механизм делает выборку записей в соответствии с заданными параметрами, и возвращает нам эти записи в виде таблицы.
Наборы данных - это прослойка между нашим приложением и реальными таблицами, хранящимися в базе данных. Все указанные выше компоненты являются наборами данных, имеют общего предка - класс TDataSet и заимствовали от него свойства, методы и события, добавляя собственные возможности. Об этом и поговорим на этой лекции.
Виды данных (информация) – это текстовая,числовая,графическая,звуковая и видео информация.
- Дані. Шкалування даних.
Нейронные сети способны обрабатывать данные, полученные из самых разных источников. Однако, данные должны быть представлены в определенном формате. Более того, вид представления данных оказывает существенное влияние на ход обучения сети. Следовательно, важно выбрать метод подготовки данных (кодирования) перед предъявлением их сети.
Шкалирование данных.
Выходные данные должны быть шкалированы (преобразованы) к диапазону, который соответствует диапазону выходных значений сжимающей функции активации выходного слоя. Сигмоидальная функция, например, имеет диапазон выходных значений от 0 до 1. Часто бывает удобным привести входные данные к тому же диапазону. Шкалирование может быть линейным или нелинейным, в зависимости от распределения данных. Наиболее часто используемые методы шкалирования - линейное, логарифмическое и "мягкое" (softmax). Можно также разделить данные на несколько диапазонов с различными факторами шкалирования.
- Інтелектуальний аналіз даних. Основні стадії.
Интеллектуальный анализ данных
— это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
ИАД (Data Mining) - это процесс поддержки принятия решений, основанный на поиске в данных скрытых закономерностей (шаблонов информации). При этом накопленные сведения автоматически обобщаются до информации, которая может быть охарактеризована как знания.
В общем случае процесс ИАД состоит из трёх стадий:
1) выявление закономерностей (свободный поиск);
2) использование выявленных закономерностей для предсказания неизвестных значений (прогностическое моделирование);
3) анализ исключений, предназначенный для выявления и толкования аномалий в найденных закономерностях.
Иногда в явном виде выделяют промежуточную стадию проверки достоверности найденных закономерностей между их нахождением и использованием (стадия валидации).
- Задачі інтелектуального аналізу даних.
ИАД решает следующие задачи:
- Выявление паттернов (пригодных к использованию сведений в крупных наборах данных), поиск скрытых закономерностей на основе анализа данных и классификаторов.
- Повышение качества информации - выявление закономерностей (в виде правил вывода) в данных для использования в моделях прогнозирования, системах поддержки принятия решений и т.д.
- Верификация данных - система выявления ошибок в оперативно поступающих данных, оценивание вероятности и риска. Например, с помощью нейронных сетей и индуктивного вывода правил строятся приблизительные прогнозы, которые сравниваются с поступающими данными. Большие отклонения рассматриваются как возможные ошибки.
- Задача класифікації, як задача інтелектуального аналізу даних.
Задача классификации – одна из наиболее распространенных задач в анализе данных и распознавании образов. Для решения этой задачи требуется создание классифицирующей функции, которая присваивает каждому набору входных атрибутов значение метки одного из классов. Классификация входных значений производится после прохождения этапа «обучения», в процессе которого на вход обучающего алгоритма подаются входные данные с уже приписанными им значениями классов.
На сегодняшний день разработано большое число подходов к решению задач классификации, использующие такие алгоритмы как
деревья решений,
нейронные сети,
логистическая регрессия,
метод опорных векторов,
дискриминантный анализ,
ассоциативные правила.
- Процесс розв’язання задачі класифікації інтелектуального аналізу даних
Классификация — отнесение входного вектора (объекта, события, наблюдения) к одному из заранее известных классов
Для задач классификации характерно «обучение с учителем», при котором построение (обучение) модели производится по выборке, содержащей входные и выходные векторы.
С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
Процесс классификации
Цель процесса классификации - построить модель, которая использует прогнозирующие атрибуты в качестве входных параметров и получает значение зависимого атрибута. Процесс классификации заключается в разбиении множества объектов на классы по определенному критерию.
Классификатором называется некая сущность, определяющая, какому из предопределенных классов принадлежит объект по вектору признаков.
Для проведения классификации с помощью математических методов необходимо иметь формальное описание объекта, которым можно оперировать, используя математический аппарат классификации. Таким описанием выступает база данных. Каждый объект (запись базы данных) несет информацию о некотором свойстве объекта.
Набор исходных данных (или выборку данных) разбивают на два множества: обучающее и тестовое.
Обучающее множество (training set) - множество, которое включает данные, использующиеся для обучения (конструирования) модели.
Такое множество содержит входные и выходные (целевые) значения примеров. Выходные значения предназначены для обучения модели.
Тестовое (test set) множество также содержит входные и выходные значения примеров. Здесь выходные значения используются для проверки работоспособности модели.
Процесс классификации состоит из двух этапов: конструирования модели и ее использования.
- Конструирование модели: описание множества предопределенных классов.
- Каждый пример набора данных относится к одному предопределенному классу.
- На этом этапе используется обучающее множество, на нем происходит конструирование модели.
- Полученная модель представлена классификационными правилами, деревом решений или математической формулой.
- Использование модели: классификация новых или неизвестных значений.
- Оценка правильности (точности) модели.
- Известные значения из тестового примера сравниваются с результатами использования полученной модели.
- Уровень точности - процент правильно классифицированных примеров в тестовом множестве.
- Тестовое множество, т.е. множество, на котором тестируется построенная модель, не должно зависеть от обучающего множества.
- Если точность модели допустима, возможно использование модели для классификации новых примеров, класс которых неизвестен.


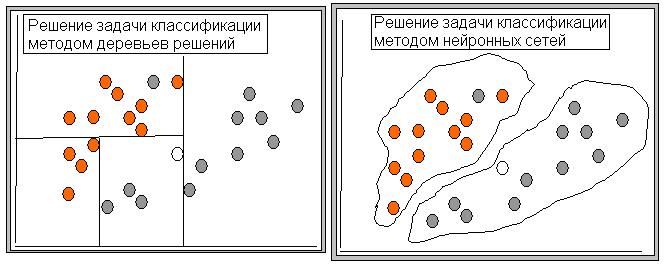
- Задача кластерізації, як задача інтелектуального аналізу даних.
Кластеризация — разделение множества входных векторов на группы (кластеры) по степени «похожести» друг на друга.
Для задач кластеризации и применяется «обучение без учителя», при котором построение модели производится по выборке, в которой нет выходного параметра. Значение выходного параметра («относится к кластеру …», «похож на вектор …») подбирается автоматически в процессе обучения. Классы изучаемого набора данных заранее не предопределены.
Задача кластеризации
Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или классы). Если данные выборки представить как точки в признаковом пространстве, то задача кластеризации сводится к определению "сгущений точек".
Цель кластеризации - поиск существующих структур.
Кластер можно охарактеризовать как группу объектов, имеющих общие свойства.
Характеристиками кластера можно назвать два признака:
- внутренняя однородность;
- внешняя изолированность.
Кластеры могут быть непересекающимися, или эксклюзивными (non-overlapping, exclusive), и пересекающимися (overlapping)

В результате применения различных методов кластерного анализа могут быть получены кластеры различной формы.
- Порівняння задач класифікації та кластерізації.
Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных.
В таблице приведено сравнение некоторых параметров задач классификации и кластеризации.
| Таблица 5.2. Сравнение классификации и кластерзации | ||
| Характеристика | Классификация | Кластеризация |
| Контролируемость обучения | Контролируемое обучение | Неконтролируемое обучение |
| Стратегия | Обучение с учителем | Обучение без учителя |
| Наличие метки класса | Обучающее множество сопровождается меткой, указывающей класс, к которому относится наблюдение | Метки класса обучающего множества неизвестны |
| Основание для классификации | Новые данные классифицируются на основании обучающего множества | Дано множество данных с целью установления существования классов или кластеров данных |
На рис. схематически представлены задачи классификации и кластеризации.

- Характеристика методів кластерізації. Оцінка якості кластерізації.
На сегодняшний день разработано более сотни различных алгоритмов кластеризации.
Приведем краткую характеристику подходов к кластеризации.
Дата добавления: 2018-05-12; просмотров: 511; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!