Процессоры Intel новой архитектуры Sandy Bridge («песчаный мост»)
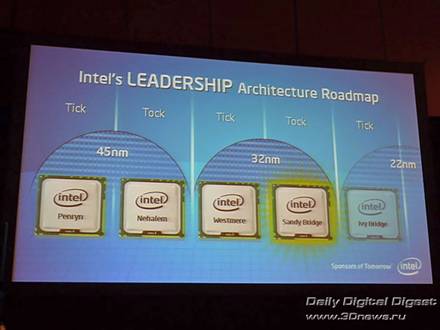
Процессоры новой архитектуры Sandy Bridge («песчаный мост») пришли на смену текущим Nehalem (45 нм) и Westmere (32 нм). В соответствии с правилом выпуска «тик-так», Sandy Bridge является «та́ком» – новой микроархитектурой, выпущенной на уже отработанном техпроцессе (32 нм). Впрочем, уже в конце 2011 года ожидается очередной «тик» – чуть обновлённая 22-нанометровая версия Sandy Bridge под названием Ivy Bridge (плющевый мост).
 |
 |
Краткий список реальных достоинств по сравнению с текущим поколением ЦП Intel:
- В чип теперь встроен северный мост чипсета вместе с видеоядром.
- Само графическое ядро (GPU) обновлено, но при этом оставлена возможность подключить и внешнюю графику.
- Ядра общего назначения поддерживают расширение AVX (Advanced Vector Extensions). Будучи эволюционным развитием набора команд SSE, это нововведение позволит повысить производительность процессоров при той же тактовой частоте. Кроме того, новые процессоры унаследуют механизм поддержки шифрования AES, впервые реализованный в Westmere.
- Кэш L3 увеличил пропускную способность за счёт высокоскоростного подключения к ядрам (в т.ч. к GPU).
- Технология авторазгона TurboBoost улучшена и позволяет теперь автоматически повышать/снижать частоты ядер x86 и графики, причём даже выше уровня номинального теплопакета (TDP), если общие температурные условия это позволяют. Также появилась дополнительная технология в рамках Turbo Boost, которая для максимальной отзывчивости системы в интерактивных задачах может на короткое время, но очень агрессивно повышать частоты процессора.
Вот по этим и более мелким пунктам и пройдёмся.
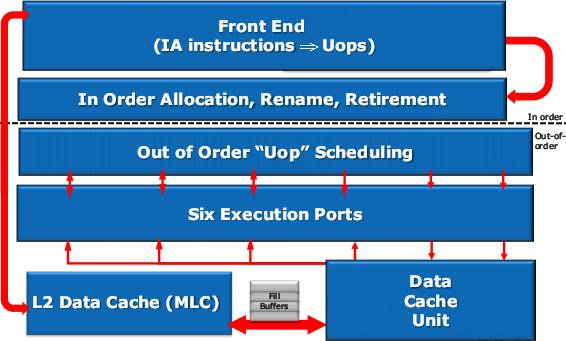
Крупноблочное ядро ЦП не изменилось. Всё дело в деталях.
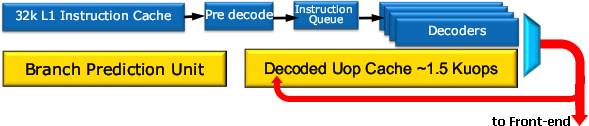
Во фронте главное нововведение – кэш на 1536 мопов, буферизирующий результаты работы декодеров. Также переработан предсказатель переходов, хранящий теперь вдвое больше целевых адресов и более долгую историю поведения команд. К нему подключен блок, определяющий попадания в моп–кэш, и в этих случаях кэш L1I, предекодер-длиномер и декодеры отключаются, экономя энергию. Также увеличивается производительность за счёт улучшения реакции на неверно предсказанный переход (правильная ветвь может оказаться в моп-кэше) и освобождения от необходимости декодировать длинные команды за несколько тактов при каждом их исполнении.
Тыл конвейера поменялся сильнее. Первое явное изменение: переход от полного буфера ROB (хранящего мопы и значения меняемых ими регистров) к комбинации сокращённого ROB (хранящего только мопы в оригинальном порядке) и двух физических регистровых файлов (PRF, хранящих содержимое переименованных регистров, на которые мопы ссылаются) – целочисленного и векторно-вещественного. Смысл перехода в том, что вместо пересылок мопов вместе с данными пересылаются только ссылки на регистры, а сами мопы и данные остаются на месте вплоть до отставки – в результате удаления ненужных пересылок экономится энергия. А за производительность отвечает вполне дежурное увеличение размеров всего разнообразия буферов и очередей.
 |
На уровне функциональных устройств главная новость – поддержка AVX, нового дополнения системы команд x86-64. В отличие от очередного SSE, просто добавляющего новые команды, AVX позволяет:
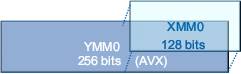
- обращается к 256-битным векторным регистрам ymm, расширяющим привычные xmm для SSE;
- использовать во всех векторных командах 3-4 операнда в недеструктивной форме, когда результат операции не уничтожает исходные аргументы;
- сэкономить на размере векторных команд за счёт компактизации кода (особенно для SSSE3 и далее).
 |
Разумеется, есть и новые инструкции – для распределения элементов в векторе и маскированных операций с памятью.
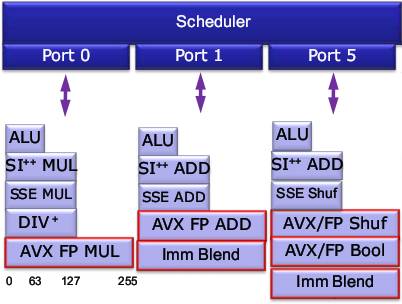
Чтобы благие начинания не остались только на уровне распознавания команд AVX, блок ФУ переделан для обработки регистров ymm с такой же скоростью, как и xmm. Для этого 128-битные сумматор, умножитель, АЛУ и перетасовщики удвоили разрядность, соответственно подняв пиковую производительность ядра.
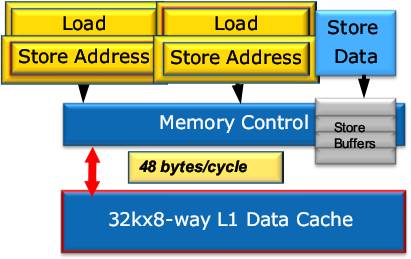
Кэш L1D на 50% повысил полную пропускную способность — теперь это 32 байта чтения + 16 байт записи за такт. Для этого в LSU (контроллер L1D) поставлен второй 16-байтовый порт чтения. Это позволит в нужном темпе насыщать ФУ данными при исполнении AVX-кода.
Во внеядре (так Intel называет остальную часть ЦП, не вошедшую в ядра общего назначения) список изменений открывает как-бы-новая (появившаяся ещё в марте 2010 г. в 8-ядерных серверных чипах Nehalem-EX) 32-байтовая кольцевая шина, связывающая кэш L3, вычислительные и графическое ядра и «системный агент» (бывший северный мост с ИКП для памяти типа DDR3). L3 Cache, обозначенный как LLC (last level cache, кэш последнего уровня), состоит из нескольких банков (по числу ядер общего назначения) с портом доступа в каждом. Связывающая всё это кольцевая шина работает на частоте, сравнимой с частотой ядер, и в идеале за такт передаёт количество данных, равное произведению 32 на число банков. Этим способом производительность разделяемого L3 Cache увеличивается пропорционально числу ядер, а вот обещанное уменьшение задержек (по крайней мере в тактах) сомнительно по сравнению с централизованным контроллером L3.
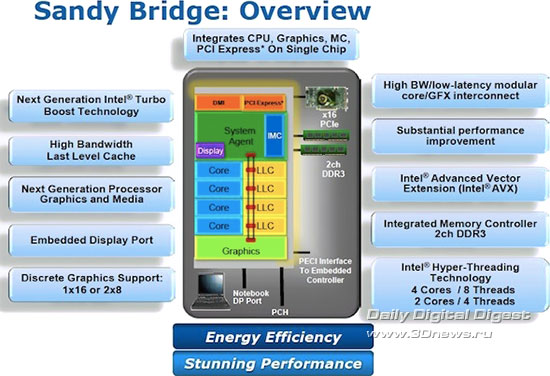
Sandy Bridge является первой архитектурой, которая интегрирует на одном кристалле как CPU, так и GPU. Чипы с архитектурой Sandy Bridge будут выпускаться по нормам 32 нм технологии, однако, в отличие от существующих аналогов, интегрированное графическое ядро в них будет создаваться по тем же 32 нм нормам и разместится на одном кристалле с вычислительными ядрами.
Эти два компонента могут делить общую Cache -память, интегрированную на кристалле, что повышает общую эффективность работы системы благодаря превосходству Cache над ОЗУ (Intel говорит о четырёхкратном увеличении эффективности пропускной способности). Поскольку GPU теперь располагается на кристалле процессора, а не на отдельном, как в нынешних Core i3/i5, L3 Cache может быть использован в т.ч. и для графики, что сглаживает недостаток пропускной способности системной памяти по сравнению со специализированной видеопамятью, редко доступной для встроенного GPU.
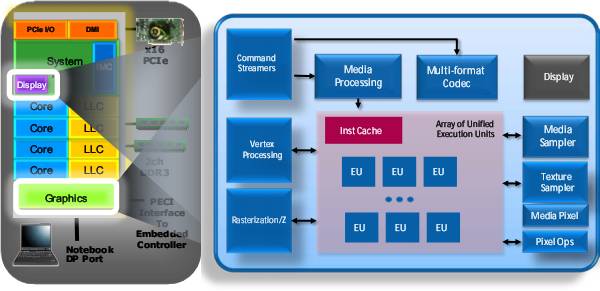
Видеоядру обещана удвоенная производительность, и не только за счёт быстрого L3 Cache, но и от удвоения числа исполнительных блоков до 12 – правда, не во всех моделях. Также внедрена поддержка DirectX 10 (а на дворе уже 11-й…) и новых форматов HD-видео для энергоэффективного аппаратного ускорения (де)кодирования.
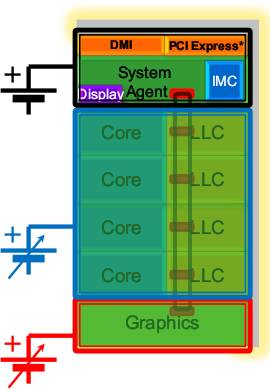
ЦП будет получать тройное питание – для ядер общего назначения и L3, для GPU, а также для системного агента с контроллерами всевозможных шин.
Контроллер терморежима и питания реализует обновлённую версию технологии TurboBoost, учитывающую переходные процессы. Она позволит в течение короткого времени (20–60 с) разогнать ядра (включая GPU) до частот, при которых тепловыделение даже выше номинального пика (TDP), если до этого ЦП некоторое время простаивал. Это обеспечит бо́льшую отзывчивость коротким по времени выполнения, но вычислительно интенсивным задачам.
Конструктивно, смена поколений процессоров будет связана с заменой процессорного гнезда. На смену разъему LGA 1156 придет разъем LGA 1155. При внешнем сходстве и одинаковых размерах, эти разъемы совершенно несовместимы между собой. Процессоры будут поставляться с широким диапазоном значений TDP и частот в разных (не совместимых с современными) корпусах для новых материнских плат – LGA1155 (частоты 2,3–3,4 ГГц). При этом все выпускаемые сейчас системные платы станут морально устаревшими.

Список чипсетов для системных плат с гнездом LGA 1155 включает модели P67, H67, H61 и Q67. Примечательно, что поддержка SATA 6 Гбит/с будет реализована в южном мосте, а USB 3.0 — нет. Не будет там и системного тактового генератора, также перекочевавшего на чип ЦП – это означает невозможность разгона через базовую частоту, т.к. она зафиксирована на значении 100 МГц. Однако Intel оставляет возможность разгона за счёт множителя, который будет разблокирован в моделях с буквой K и может достигать значения 57. Кстати о моделях – их названия так и останутся в виде Core i3/i5/i7, но номер модели теперь 4-значный. Помимо буквы K, его может дополнять S (низкий TDP), T (ещё более экономный) или M (мобильный). Чуть позже выйдут серверные и бюджетные варианты.
Преемником процессорного гнезда LGA 1366 станет LGA 2011. Существенное увеличение количества контактов объясняется наличием у процессора 256-разрядной шины памяти (четыре канала DDR3) и интеграцией в процессор функций северного моста. Корневой блок интерфейса PCI-Express 2.0 предоставит разработчикам системных плат 32 линии (у LGA-1155 их будет 16).
Что в итоге? Intel серьёзно обновила Nehalem – без революционных прорывов, а просто последовательно обновляя детали микроархитектуры и внедряя все нововведения последних двух лет. В результате получили ещё более быстрые, но остающиеся в тех же тепловых рамках, процессоры.
Sandy Bridge, как и старые чипы Nehalem и Westmere, по-прежнему имеют интегрированные на кристалл контроллеры PCI Express, 2-канальный DDR3, а также теперь и DisplayPort. Решение об использовании 2-канального контроллера памяти принято на том основании, что большей части клиентов Intel не нужны 3 канала памяти, да и рынок LGA 1366 слишком мал.
Sandy Bridge являются первыми процессорами Intel с поддержкой набора инструкций AVX (продвинутых векторных расширений), улучшающих производительность в ряде высокопараллельных простейших операций, часто применяемых в мультимедиа-приложениях.
Концепция кольцевой шины также серьёзно упрощает создание на базе Sandy Bridge различных кристаллов. К примеру, несмотря на то, что прототипы новых процессоров имеют 4 вычислительных ядра x86, технически очень легко сделать 2-ядерный вариант или добавить/убрать какие-либо блоки в будущем.
Серверные чипы Sandy Bridge будут основаны на том же дизайне кольцевой шины и смогут иметь в обозримом будущем множество ядер (упоминались чипы с 10 ядрами).
Каждое ядро Sandy Bridge имеет 256 КБ кэш-памяти данных второго уровня. Для обращения к кэш-памяти третьего уровня необходимо 25 полных машинных циклов. Процессор оснащен интегрированным контроллером PCI Express 2.0 и двухканальным контроллером памяти с поддержкой памяти DDR3-1600. Рассчитанный на производство по нормам 32 нм, четырехъядерный микропроцессор займет на кристалле кремния площадь 225 кв.мм. Потребляемая мощность составит 85 Вт.
Эти конструктивные особенности, как полагают, позволят повысить производительность и эффективность процессоров Sandy Bridge.
Ожидается, что новые процессоры вместе с переходом на новую архитектуру получат другую номенклатуру: вместо трехзначной маркировки модели после указания серии (Core i3, Core i5 или Core i7), появится четырехзначная, вида 2ХХ0. Таким образом Intel попытается избежать путаницы с названиями моделей процессоров архитектур Westmere и Sandy Bridge.
Как было сказано выше, поначалу новое поколение процессоров Intel будет представлено пятью моделями:
- Core i7-2600: четырехъядерный процессор с поддержкой технологии Hyper-Threading, тактовая частота — 3,2 ГГц, объем кэш-памяти третьего уровня — 8 МБ ;
- Core i5-2400: четырехъядерный процессор без поддержки технологии Hyper-Threading, тактовая частота — 3,1 ГГц, объем кэш-памяти третьего уровня — 6 МБ;
- Core i5-2500: четырехъядерный процессор без поддержки технологии Hyper-Threading, тактовая частота — 3,3 ГГц, объем кэш-памяти третьего уровня — 6 МБ ;
- Core i3-2100: двухъядерный процессор с поддержкой технологии Hyper-Threading, тактовая частота — 3,1 ГГц, объем кэш-памяти третьего уровня — 3 МБ ;
- Core i3-2120: двухъядерный процессор с поддержкой технологии Hyper-Threading, тактовая частота — 3,3 ГГц, объем кэш-памяти третьего уровня — 3 МБ .
Таким образом, первые модели на архитектуре Sandy Bridge будут представлены двух- и четырехъядерными процессорами с поддержкой технологии многопоточности Hyper-Threading (или без нее), работающие на частоте свыше 3 ГГц. Потом к ним, очевидно, присоединятся более мощные шести- и восьмиядерные модели с 16 и 24 МБ кэш-памяти третьего уровня.
Дата добавления: 2018-04-15; просмотров: 247; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!