Считывание и декодирование инструкций
ЛЕКЦИЯ. Процессоры Core i7 (Nehalem) фирмы Intel
(ядро Bloomfield,Socket LGA1366).
6 ноября 2008 года корпорация Intel официально представила Core i7 – первые процессоры архитектуры Nehalem. Новая линейка CPU принимает эстафету у суперуспешной разработки Intel Core. Оба поколения процессоров будут продаваться параллельно, вплоть до анонса двухъядерников Havendale, использующих микроархитектуру Intel Nehalem и разъем LGA1366.
Выпуск четырехъядерников Core i7 должен закрепить подавляющее преимущество Intel в секторе наиболее производительных решений. Кроме того, с анонсом Core i7 возвращается подзабытая технология Hyper-Threading, обеспечивающая многопоточную обработку данных в пределах одного физического ядра. Этот факт должен побудить разработчиков ПО к дальнейшей оптимизации софта для процессоров с числом ядер больше двух.
Выход Nehalem полностью согласуется с фирменной концепцией Intel: появление новой архитектуры один раз в два года. Так, эра Intel Core 2 началась в июле 2006-го с выпуском процессоров Conroe. Далее последовал переход на 45-нм технологическую норму (семейство Penryn). И вот, с сегодняшнего дня, мы имеем дело с Core i7 – представителями архитектуры Nehalem на ядре Bloomfield.

|
| Эволюция процессоров Intel |
Архитектура
Согласно официальным сведениям первые процессоры Nehalem обладают, по крайней мере, 731 млн. транзисторов, что на 10,7% меньше, чем у «квадов» Penryn Yorkfield. В то же время, площадь кристалла Core i7 увеличена с 214 до 263 мм2.
|
|
|
Архитектура Nehalem изначально была разработана как модульная. Инженеры Intel хотели создать набор базовых "кирпичей, которые можно собирать как блоки конструктора Lego, чтобы создавать разные версии архитектуры.

|
| Модульная архитектура Nehalem. |
Основной чертой новой архитектуры стала модульность. Главный модуль представляет собой классический одноядерный x86-процессор: он состоит из исполнительного ядра, L1 Cache размером 64 КБ, поделенного на 2 равные части для данных и инструкций и L2 Cache размером 256 КБ.
Прочие блоки могут быть следующими:
1. разделяемый L3 Cache;
2. контроллер памяти;
3. контроллер шины QPI (QuickPath Interconnect);
4. контроллер шины PCI Express (пока не реализовано);
5. контроллер энергопотребления (PCU) и генератор частот;
6. контроллер интегрированной графики.
Впрочем, не следует считать, что это строго фиксированный список, и ни одного пункта больше архитектура Core i7 включить не позволяет. Скорее данный набор базовых элементов явился демонстрацией намерений Intel по дальнейшему усовершенствованию архитектуры – недаром в него вошёл контроллер интегрированной графики, на тот момент ни в одном процессоре Core i7 ещё не присутствующий. Всё это вместе может комбинироваться произвольным образом, причём допускается как наличие, или отсутствие определённых модулей, так и различное их количество внутри процессора. Модель Core i7 920 выглядит, например, так:
|
|
|
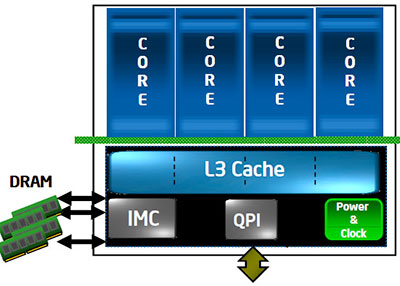
Как легко заметить, она включает в себя четыре процессорных ядра, один трёхканальный контроллер памяти DDR3, один контроллер шины QPI для общения с чипсетом, и модуль отвечающий за генерацию необходимых процессору для работы частот и управление энергопотреблением. С другой стороны, это лишь один из возможных вариантов, реализованный в данной конкретной модели. Например, если на базе новой архитектуры создавать серверный процессор — то не лишним будет увеличить количество не только ядер, но и контроллеров QPI, если же, наоборот, мы разрабатываем мобильный CPU — можно сократить количество ядер, чтобы уменьшить энергопотребление и заменить контроллер чересчур быстрой QPI на обычную PCI Express. Чисто теоретически, никто, наверное, не мешает убрать и L3, оставив всего по минимуму: одно исполнительное ядро, контроллер памяти, PCI-E (Celeron?..) Таким образом, главная цель Intel, похоже, достигнута: у неё есть модульная архитектура с достаточно небольшим количеством основных модулей, из которых, комбинируя их произвольным путём, можно достаточно легко «слепить» как скромный low-end процессор для какого-нибудь неттопа, так и многоядерного серверного монстра. И всё это — из одних и тех же модулей, вот в чём основная прелесть! Однако, разумеется, не только в модульности дело, есть и другие важные изменения. Давайте рассмотрим их подробнее.
|
|
|

|
| Архитектура Core i7. |
Но Intel не только обновила свою архитектуру, взяв у конкурента интересные инновации. С бюджетом более 700 млн. транзисторов (731 млн., если быть точным), инженеры смогли серьёзно улучшить основные характеристики исполнительного ядра, добавив в то же время новую функциональность. Например, поддержка многопоточности (simultaneous multi-threading, SMT), которая впервые появилась в Pentium 4 "Northwood" под названием Hyper-Threading, вновь вернулась. Поскольку физических ядер на кристалле четыре, некоторые версии Nehalem, которые используют два ядра в одной упаковке, смогут выполнять до 16 потоков одновременно.
Первые процессоры Core i7 с ядром Bloomfield имели четырехъядерный дизайн, тогда как структура их предшественников – Core 2 Quad – представляла собой мультичиповый модуль из пары Core 2 Duo. К числу основных элементов кристалла Core i7 принадлежат четыре физических ядра, разделяемый L3 Cache, встроенный контроллер памяти DDR3 и шина QuickPath Interconnect (QPI).
|
|
|

|
| Структура кристалла Core i7 |
Каждое из четырех ядер Bloomfield, в свою очередь, распределяется на меньшие блоки.
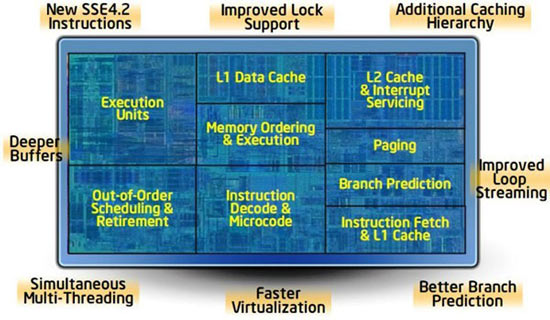
|
| Устройство ядра Bloomfield. |
Трёхуровневая иерархия Cache
Иерархия памяти в Conroe была очень простой; Intel сконцентрировалась на производительности общего L2 Cache, который стал лучшим решением для архитектуры, нацеленной, главным образом, на двуядерные конфигурации. Но в случае с Nehalem инженеры начали с нуля и пришли к такому же заключению, что и конкуренты: общий L2 Cache не очень хорошо подходит для "родной" четырёхъядерной архитектуры. Разные ядра могут слишком часто "вымывать" данные, необходимые другим ядрам, что приведёт к слишком многим проблемам с внутренними шинами и арбитражем, пытаясь обеспечить все четыре ядра достаточной пропускной способностью с сохранением задержек на достаточно низком уровне. Чтобы решить эти проблемы, инженеры оснастили каждое ядро собственным L2 Cache. Поскольку он относительно мал (256 КБ), получилось обеспечить Cache очень высокой производительностью; в частности, задержки существенно улучшились по сравнению с Penryn – с 15 тактов до, примерно, 10 тактов. Объем L1 Cache составляет 64 КБ: по 32 КБ для инструкций и данных.

|
| Трёхуровневая иерархия Cache |
Затем есть огромная Cache–память третьего уровня (8 МБ), отвечающая за связь между ядрами. Архитектура Cache Nehalem – инклюзивная для всех нижних уровней иерархии Cache. Это означает, что если ядро попытается получить доступ к данным, и они отсутствуют в L3 Cache, то нет необходимости искать данные в собственных Cache других ядер – там их нет. Напротив, если данные присутствуют, четыре бита, связанные с каждой строчкой Cache–памяти (один бит на ядро) показывают, могут ли данные потенциально присутствовать (потенциально, но без гарантии) в нижнем Cache другого ядра, и если да, то в каком. Чем выше загрузка L3 Cache, тем эффективнее проявляет себя Core i7 в мультипоточных приложениях.
Эта техника весьма эффективна для обеспечения когерентности персональных Cache каждого ядра, поскольку она уменьшает потребность в обмене информацией между ядрами. Есть, конечно, недостаток в виде потери части Cache-памяти на данные, присутствующие в Cache других уровней. Впрочем, не всё так страшно, поскольку L1 и L2 Cache относительно небольшие по сравнению с L3 Cache – все данные L1 и L2 Cache занимают, максимум, 1,25 Мбайт в L3 Cache из доступных 8 Мбайт. Как и в случае Barcelona, L3 Cache работает на других частотах по сравнению с самим чипом. Следовательно, задержка доступа на данном уровне может меняться, но она должна составлять около 40 тактов.

|
| Организация Cache–памяти |
Единственные разочарования в новой иерархии Cache Nehalem связаны с L1 Cache. Пропускная способность Cache инструкций не была увеличена – по-прежнему 16 байт на такт по сравнению с 32 у Barcelona. Это может создать "узкое место" в серверно-ориентированной архитектуре, поскольку 64-битные инструкции крупнее, чем 32-битные, тем более что у Nehalem на один декодер больше, чем у Barcelona, что сильнее нагружает Cache. Что касается Cache данных, его задержка была увеличена до четырёх тактов по сравнению с тремя у Conroe, облегчая работу на высоких тактовых частотах. Но инженеры Intel увеличили число промахов L1Cache данных, которые архитектура может обрабатывать параллельно.
Подсистема кэширования
Однако наибольшие изменения, естественно, коснулись «основной» подсистемы кэширования, а именно — взаимодействия между L1 Cache и L2 Cache, а также появившимся L3 Cache у Nehalem. Во-первых, теперь снова L2 Cache является «персональной собственностью» конкретного ядра, и оно ни с кем его не делит — разделяемым и общим для всех является Cache следующего уровня — L3 Cache. Во-вторых, Intel немного «переиграла» значения латентности для L1 и L2 Cache— у L1 Cache латентность стала на 1 такт больше, чем в Core 2, а у L2 Cache она наоборот стала в полтора раза ниже.
Но основной интерес, конечно же, вызывает L3 Cache. Он, как и L2 Cache в Core 2, является динамически разделяемым. Более того, он наконец-то является не «не-эксклюзивным», а именно инклюзивным: данные, находящиеся в L1/L2 Cache — обязаны присутствовать в L3 Cache. Intel даже объясняет причину подобного решения (далее на рисунках левый соответствует эксклюзивному Cache, а правый — инклюзивному).

Рассмотрим первую ситуацию: ядро 0 запрашивает данные из L3 Cache, и они там не обнаруживаются.

В случае с эксклюзивным Cache (слева) это ещё ничего не значит: данные могут находится в L1/L2 Cache других ядер. Инклюзивный Cache такую ситуацию исключает, поэтому никаких дополнительных проверок не требуется.

Рассмотрим другую ситуацию: ядро 0 запрашивает данные из L3 Cache, и они там обнаружены. В случае с эксклюзивным Cache, проблем, наоборот, нет никаких: если данные обнаружены в L3 Cache — то больше их нигде нет. В случае с инклюзивным Cache могла бы возникнуть проблема: данные, наоборот, наверняка есть в L1/L2 Cache одного из ядер. Которого?..

Для Nehalem эта проблема проблемой не является: каждая строка L3 Cache содержит биты core valid (по количеству физических ядер), которые указывают, копией содержимого L1/L2 какого ядра является данная строчка. Поэтому нет никакой необходимости опрашивать на предмет нахождения данных каждое ядро.
В общем, Intel придерживается достаточно последовательных взглядов в вопросе об оптимальной архитектуре Cache: лучше проиграть в объёме, чем в скорости. Быть может, это связано с тем, что у неё и так хорошо получается делать большие Cache?. Некоторое разочарование вызывает тот факт, что L3 Cache у Core i7 будет работать не на частоте процессора, а на некой фиксированной для целого ряда моделей частоте. Впрочем, эту ложку дёгтя насколько компенсируют два факта: во-первых, у AMD Phenom L3 Cache тоже работает на фиксированной частоте, а во-вторых — у Core i7 эта частота выше (2,66 ГГц).
Технология Turbo Boost
Intel шла к идее оверклокинга медленно, но верно: сначала оверклокерские функции появились в её платах, теперь вот — прямо в процессорах. Ну а если серьёзно, то именно наличие в составе Nehalem PCU, позволило реализовать ещё одну интересную особенность данного процессора: он может повышать частоту работы одного или нескольких ядер в том случае, если остальные простаивают. При этом, насколько нам удалось понять, доступны два варианта «турбирования» ядер: повышение частоты нескольких ядер на одну ступень (+133 МГц) и повышение частоты работы одного ядра на две ступени (+266 МГц).
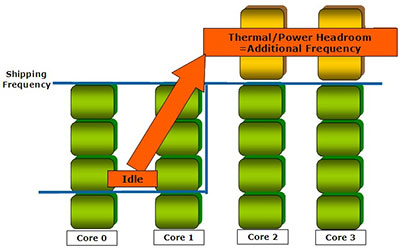
При этом подчёркивается, что совершенно не обязательно, чтобы остальные ядра были полностью разгружены: Turbo Mode включается в тех случаях, когда уровень загрузки ядер позволяет повысить частоту некоторых из них, не выходя за пределы максимального TDP. Дополнительным бонусом является то, что технология Turbo Boost, как и работа PCU — совершенно не связана ни с какой внешней поддержкой т.е. функционирует внутри процессора полностью самостоятельно и не требует каких-либо дополнительных программных или аппаратных средств.
Исполнительное ядро
В «исполнительном ядре» происходят не только собственно вычисления, но и декодирование инструкций. Теперь рассмотрим более детально новую архитектуры, начиная с первых ступеней конвейера – часть, которая отвечает за считывание инструкций из памяти и подготовку их для выполнения.

|
Считывание и декодирование инструкций
В отличие от перемен, которые произошли при переходе от микроархитектур с Core на Core 2, Intel не очень сильно переделала переднюю часть конвейера Nehalem. Здесь есть те же самые четыре блока декодирования, которые появились вместе с Conroe – три простых и один сложный. По-прежнему поддерживается функция слияния макроопераций (macro–ops fusion), обеспечивается теоретическая максимальная пропускная способность 4+1 инструкций x86 за такт.

|
На первый взгляд никаких революционных изменений не произошло, однако нужно обратить внимание на детали. Как мы уже не раз упоминали, повышение числа исполнительных блоков – очень неэффективный способ поднять производительность. Накладные расходы при этом очень велики, а прирост всё больше срезается с каждым добавлением. Поэтому вместо добавления новых блоков декодирования, инженеры сконцентрировали своё внимание на оптимизации существующих.
Начнём с того, что была добавлена поддержка слияния макроопераций (macro-ops fusion) для 64-битного режима, что вполне оправданно для архитектуры, подобной Nehalem. Но на этом не остановились. Если архитектура Conroe могла выполнять слияние только весьма ограниченного набора инструкций, архитектура Nehalem поддерживает большее число вариантов, то есть слияние макроопераций может выполняться чаще.
Ещё одна новая функция, представленная с Conroe, тоже была улучшена: Loop Stream Detector. За этим названием скрывается буфер, содержащий несколько инструкций (18 инструкций x86 в архитектуре Core2). Когда процессор определяет цикл, он отключает некоторые части конвейера. Поскольку цикл подразумевает выполнение одинаковых инструкций указанное число раз, вряд ли имеет смысл выполнять предсказание ветвлений или забирать инструкции из L1 Cache при каждой итерации цикла. Поэтому Loop Stream Detector работает как небольшая Cache-память, которая "замыкает" первые ступени конвейера в подобных ситуациях. При реализации этой техники получается двоякий прирост: снижается энергопотребление, поскольку процессор не работает над бесполезными задачами, а также увеличивается производительность путём снижения нагрузки на Cache инструкций L1.

|
С архитектурой Nehalem Intel улучшила функциональность Loop Stream Detector. Был увеличен буфер – теперь он вмещает 28 инструкций. Но, более того, изменилось его расположение в конвейере. В Conroe буфер располагался как раз за ступенью выборки инструкций (instruction fetch). Теперь же буфер находится после ступени декодирования; такое расположение позволило отключать большую часть конвейера. В Nehalem Loop Stream Detector хранятся уже не инструкции x86, а микрооперации. В данном отношении технология чем-то напоминает концепцию Cache с отслеживаниями (trace cache) как у Pentium 4. В Nehalem можно найти ряд инноваций, появившихся с архитектурой NetBurst, поскольку команда в Хиллсборо (Hillsboro), отвечающая за Nehalem, занималась и проектом Pentium 4. Однако если Pentium 4 использовал Cache с отслеживаниями эксклюзивно, поскольку он мог рассчитывать только на один декодер в случае промаха Cache, Nehalem выигрывает от мощи четырёх декодеров, хотя Loop Stream Detector можно назвать только дополнительной оптимизацией для некоторых ситуаций.
Исполнение инструкций.
Блоки, отвечающие за исполнение инструкций, в Nehalem оставлены практически без изменений. Из чего следует один простой вывод: в тех ситуациях, когда Core 2 и так успешно справляется с предвыборкой инструкций и данных, декодированием и предсказанием ветвлений — практически никакого преимущества все вышеперечисленные «новшества» Core i7 не дадут, и производительность его (при равной с Core 2 частоте) будет примерно такая же.
Однако некоторые изменения всё же были внесены, и связано это как раз с введением поддержки Hyper–Threading. Изменения, разумеется, самые что ни на есть очевидные: Reorder Buffer расширен до 128 микроопераций, Reservation Station – до 36 инструкций (было 32). Ну и буферы для данных, соответственно: Load с 32 до 48, Store – с 20 до 32. Для чего это нужно, также очевидно: чтобы увеличить количество команд и данных в очереди на исполнение, тем самым повысив вероятность того, что какие-то из них можно будет выполнить параллельно.

|
Предсказание ветвлений
Последнее улучшение в передней части конвейера касается предсказания ветвлений. Эффективность алгоритмов предсказания ветвлений критична для архитектур, где используется высокий уровень параллелизма инструкций. Ветвления разрывают параллелизм, поскольку необходимо ждать результат предыдущей инструкции, прежде чем продолжить выполнение потока инструкций. Предсказание ветвлений прогнозирует, будет взята ветвь или нет, и если ветвь будет взята, то быстро вычисляет дальнейший адрес для продолжения выполнения. Для этого не требуется каких-либо сложных техник; всё что нужно - массив ветвлений, так называемый Branch Target Buffer (BTB), который сохраняет результаты ветвлений по мере продолжения выполнения кода (взята ветвь или нет, а также целевой адрес). К массиву прилагается алгоритм определения результата следующего ветвления.
Intel не обеспечила деталей по поводу алгоритма, используемого в новых блоках предсказания ветвлений, но широко известно, что теперь есть два уровня предсказаний. Первый уровень не изменился с архитектуры Conroe, но был добавлен новый уровень с медленным доступом, который позволяет хранить большую историю ветвлений. По информации Intel, эта конфигурация улучшает предсказание ветвлений в некоторых приложениях, которые используют массивные участки кода, таких как базы данных. Другое улучшение касается Return Stack Buffer, который хранит адрес возврата функций, когда они вызываются. В некоторых случаях этот буфер может переполняться, что приводит к ошибочным предсказаниям. Чтобы ограничить такую возможность, AMD увеличила его размер до 24 записей, а в Nehalem появилась система переименования для этого буфера.
Возвращение Hyper–Threading
Итак, первые ступени конвейера были не очень сильно изменены. То же самое касается и замыкающих ступеней. Здесь используются такие же исполнительные блоки, что и в самых последних процессорах Core, но, опять же, инженеры вновь поработали над их более эффективным использованием.
С Nehalem вернулась технология Hyper–Threading. Впервые она появилась в версии Northwood архитектуры Intel NetBurst. Технология Hyper–Threading, известная как Simultaneous Multi–Threading (SMT), позволяет использовать параллелизм на уровне потоков, чтобы оптимизировать нагрузку исполнительных блоков ядра, в результате чего на уровне приложений одно физическое ядро превращается в два виртуальных.
Принцип ее работы заключается в распределении операций с данными между двумя виртуальными потоками одного физического ядра. В частности, четырехъядерные модели Core i7 будут функционировать в 8 потоков.
Чтобы поддерживать параллельное выполнение потоков, некоторые ресурсы, такие как регистры, должны быть продублированы. Другие ресурсы можно совместно использовать двумя потоками, сюда входит вся логика внеочередного выполнения (буфер изменения порядка инструкций/instruction reorder buffer, исполнительные блоки и Cache). Внедрение SMT было обусловлено простым наблюдением: чем "шире" (больше исполнительных блоков) и "глубже" (больше ступеней конвейера) становятся процессоры, тем сложнее получать достаточную степень параллелизма для загрузки исполнительных блоков на каждом такте.

|
| Механизм работы технологии Hyper-Threading |
Если Pentium 4 был очень "глубоким", конвейер превысил 20 ступеней, у Nehalem он очень "широкий". У процессора доступно шесть исполнительных блоков, которые способны одновременно выполнять три операции работы с памятью и три операции вычисления. Если механизм выполнения не сможет обеспечить параллелизм инструкций на должном уровне, с загрузкой всех блоков, в конвейере появляются так называемые "пузырьки" – холостые такты.
Чтобы преодолеть эту проблему, SMT пытается обеспечить параллелизм инструкций из двух потоков, а не из одного, с целью максимально уменьшить число холостых тактов. Этот подход оказывается очень эффективным, когда два потока связаны с заданиями разной природы. С другой стороны, если два потока выполняют, например, интенсивные вычисления, это лишь увеличит нагрузку на те же самые вычислительные блоки, которые будут бороться между собой за доступ к кэшу. Вряд ли стоит лишний раз говорить, что SMT в данной ситуации имеет мало интереса и может даже негативно повлиять на производительность.
Впрочем, в большинстве ситуаций влияние SMT на производительность положительное, а себестоимость технологии по ресурсам невысокая, что и объясняет её возвращение. Но программистам следует быть внимательными, поскольку в случае Nehalem не все потоки создаются одинаковыми. Intel обеспечивает способ точно определить топологию процессора (число физических и логических процессоров), а программисты могут использовать механизм привязки ОС (affinity), позволяющий привязать поток к виртуальному ядру.
Так как SMT сильнее нагружает внеочередной исполнительный движок, Intel увеличила размер некоторых встроенных буферов, чтобы они не превратились в "узкое место". Так, буфер изменения порядка команд (reorder buffer), который отслеживает все выполняемые инструкции, был увеличен с 96 записей у Core 2 до 128 записей у Nehalem. На практике, поскольку буфер статически распределён, чтобы ни один из потоков не смог монополизировать все ресурсы, его размер уменьшен до 64 записей для каждого потока в SMT. Вполне понятно, что в случае выполнения одного потока обеспечивается доступ ко всем записям, то есть потенциально устранены специфические случаи, в которых Nehalem дал бы меньшую производительность, чем предшественник.
Станция резервации (reservation station), которая отвечает за привязку инструкций к разным исполнительным блокам, тоже была увеличена с 32 до 36 записей. Но, в отличие от буфера изменения порядка команд, здесь распределение уже динамическое, поэтом поток может использовать больше или меньше записей как функцию его потребностей.
Два других буфера тоже были изменены: буфер загрузки (load buffer) и буфер хранения (store buffer). Первый получил 48 записей против 32 у Conroe, а второй – 32 вместо 20. Здесь, опять же, распределение ресурсов между потоками статическое.
Hyper-Threading позволяет эффективно обрабатывать разнотипные данные в пределах одного ядра. В то же время, интенсивные вычисления схожей природы увеличивают нагрузку на буфер изменения порядка команд (reorder buffer) вследствие соперничества операционных блоков за первоочередной доступ к кэшу. В подобных условиях активация HT приносит мало пользы, а в некоторых игровых приложениях даже приводит к снижению производительности.
Впрочем, основная масса программ положительно реагирует на многопотоковый алгоритм вычислений. Учитывая невысокую себестоимость внедрения Hyper-Threading и приобретенный инженерами Intel опыт, нет повода сомневаться в целесообразности нововведения.
С течением времени все большее количество разработчиков ПО будут адаптировать свою продукцию для процессоров с Simultaneous Multithreading. Уже сейчас список подобных приложений содержит, по крайней мере, полсотни наименований. Мы же приведем самые известные из них:
SSE 4.2.
Nehalem поддерживает SSE 4.2, то есть весь перечень потоковых SIMD-расширений v.4.1, которые присутствовали у Penryn (SSE4.1) плюс ещё семь новых инструкций.

|
| Возможности SSE 4.2 |
Благодаря SSE 4.2, процессоры Core i7 быстрее обрабатывают XML-код и введенный, с целью распознавания, рукописный текст. Идеально подходят для сложных математических вычислений: генный анализ, расчет расстояния Хэмминга или моделирование динамики роста населения, а также обладают расширенными коммуникационными возможностями – ускоренной работой с NAS-хранилищами и механизмом экономии электропитания.
Переходя к описанию платформы Intel LGA1366 в целом, выделим два архитектурных блока, связывающих кристалл процессора с другими компонентами системы, – это QuickPath Interconnect (QPI) и Integrated Memory Controller (IMC).
Соединения QuickPath.
Хотя архитектура Core была эффективной c шиной Front Side Bus (FSB), которая соединяет процессор с северным мостом, но для многопроцессорных конфигураций архитектура с трудом справлялась с увеличением нагрузок. Процессорам приходилось совместно использовать эту шину не только для доступа в память, но и для обеспечения когерентности данных, находящихся в соответствующей Cache–памяти.
В данной ситуации поток транзакций по шине быстро приводил к насыщению. Долгое время Intel обходила эту проблему просто переходом на более скоростную шину или на большую Cache–память, но настало время исправить причину этой проблемы, полностью переработав механизм общения процессоров с памятью и другими компонентами.
Решение, выбранное Intel под названием QuickPath Interconnect (QPI), представляет собой встроенный контроллер памяти и очень быструю последовательную двунаправленную 20-битную шину с топологией соединения «точка-точка», при этом 16 бит в каждую сторону несут полезную информацию, и ещё 4 бита служат для коррекции ошибок и прочих служебных целей. Работая со скоростью 6,4 миллиарда транзакций в секунду, QPI обеспечивает скорость передачи данных 12,8 ГБ/с в каждую сторону, и, соответственно, 25,6 ГБ/с в сумме.

|
| Функциональная схема QuickPath Interconnect |
Поэтому интерфейс QPI даёт пропускную способность почти в два раза выше шины FSB, если запись и чтение сбалансированы должным образом. Теоретически, когда есть только операции чтения или записи, пропускная способность будет идентична FSB. Но следует помнить, что шина FSB использовалась как для доступа к памяти, так и для передачи всех данных на периферию или между процессорами. В случае Nehalem, интерфейс QPI исключительно предназначается для передачи данных на периферию, а за работу с памятью отвечает интегрированный в процессор контроллер. Связь между несколькими CPU в многосокетной конфигурации осуществляется ещё одним интерфейсом QPI. Даже в самой тяжёлой ситуации QPI должен показать лучшую производительность, чем FSB.
Таким образом, Nehalem был разработан с учётом гибкой и масштабируемой архитектуры, поэтому число доступных интерфейсов QPI меняется в зависимости от ориентации на тот или иной сегмент рынка – от одного интерфейса для связи с чипсетом в односокетных конфигурациях до целых четырёх для четырёхсокетных серверов. Это позволяет создавать полносвязные четырёхпроцессорные системы, когда каждый процессор может получать доступ к любой области памяти через один QPI, поскольку каждый процессор напрямую подключён к трём остальным.

|
Ядро настольных Core i7 имеет одну шину QPI, а вот в серверных процессорах содержатся два одноименных интерфейса. Один из них, по-прежнему, отвечает за связь с чипсетом, а второй служит «мостиком» между процессорами. В любом случае, производительности QuickPath Interconnect вполне достаточно, чтобы обеспечить жизнедеятельность платформ с несколькими CPU.

|
| Принцип работы QPI в настольных и серверных платформах |
Разумеется, для десктопного процессора такая пропускная способность в подавляющем большинстве случаев избыточна, особенно учитывая тот факт, что QPI будет использоваться исключительно для связи с чипсетом — контроллер памяти уже встроен в процессор. (Актуальность данное решение имеет только для ситуации, когда чипсет обеспечивает большое количество линий PCI Express 2.0, как это реализовано в чипсете для платформы Nehalem — Intel Х58). Процессоры на базе новой архитектуры, предназначенные для использования в серверном сегменте, будут содержать несколько контроллеров QPI, что позволит им быть связанными между собой напрямую «каждый с каждым» для оптимальной реализации архитектуры памяти Non-Uniform Memory Access (NUMA).
Встроенный контроллер памяти
Последний важный элемент процессорного кристалла Bloomfield – Integrated Memory Controller (IMC). Напомним, что это первый опыт Intel в переносе управляющих структур памяти из северного моста в тело CPU.
Дебютное воплощение IMC предлагает трехканальный (192-битный) режим работы оперативной памяти.
Заложив в конструкцию контроллера памяти Nehalem сразу три канала с поддержкой DDR3-1333 (серверные версии под кодовым наименованием Nehalem-EP) или DDR3-1066 (десктопные Nehalem), Intel скорее всего рассчитывал избавиться от необходимости кардинально переделывать данный узел хотя бы в ближайшие годы, или, по крайней мере, переделывать крайне незначительно. Например, добавление будущим CPU поддержки более высокочастотной DDR3 при желании можно реализовать таким образом, чтобы ради их установки не пришлось менять системную плату.
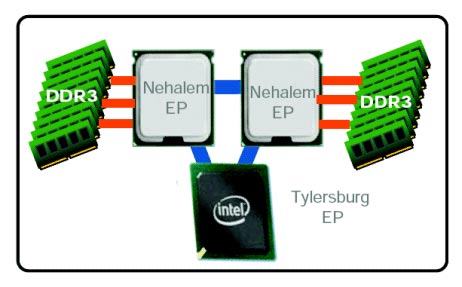
|
| Встроенный контроллер памяти |
Поэтому считается, что лучшими наборами модулей RAM для платформы Nehalem LGA1366 станут комплекты DDR3, состоящие из трех планок. Впрочем, предварительные тесты показывают лишь небольшой, 1-5-процентный, прирост производительности при переходе с двух- на трехканальную организацию подсистемы памяти.
В целом, сниженная латентность доступа к RAM, возникшая за счет переноса IMC в тело процессора, дает значительный прирост пропускной способности памяти. Интересно другое: в большинстве приложений DDR3-1066 CL7 ничуть не уступает DDR3-1600 CL8, следовательно, потребность мощных систем в высокочастотных модулях памяти отходит на второй план.
Платформа LGA1366
Жизнеспособность процессоров линейки Core i7 обеспечивают соответствующие материнские платы на базе чипсета Intel X58 Express (Tylersburg). Упомянутый набор логики, в свою очередь, состоит из северного моста X58 IOH и южного моста ICH10(R), знакомого по актуальным предложениям на 775-м сокете.
Официально Core i7 рекомендуется использовать с планками DDR3-1066 (8,5 Гбит/с), однако существуют достоверные сведения об успешной работе на платах Intel X58 модулей памяти номиналом 1600 МГц и выше. В расчете на трехканальные комплекты оперативной памяти предусматривается, как правило, 3 или 6 слотов RAM; максимальный объем устанавливаемой DDR3 – 4 ГБ на один слот. На всякий случай отметим, что материнские платы LGA1366 под DDR2 выпускаться не будут, т.к. поддержка второго поколения DDR не реализована на уровне контроллера.
Графическая подсистема включает в себя от 2 до 4 слотов PCI-Express 2.0 (всего 36 линий, с возможностью расширения), совместимых с конфигурацией ATI CrossFireX и опционально с NVIDIA SLI. Производители материнских плат могут выбирать между программным и аппаратным способом реализации SLI. Впрочем, оба пути сопряжены с существенными материальными затратами, поэтому тандем видеокарт GeForce мы, скорее всего, увидим только на флагманских изделиях.
Модельный ряд Core i7.
В таблице представлены основные параметры четырехядерных процессоров Intel Core i7 (архитектура Bloomfield) на основе сокета LGA1366.
| Модель CPU/Параметры | Intel Core i7-975 Extreme Edition | Intel Core i7-965 Extreme Edition | Intel Core i7-960 | Intel Core i7-950 | Intel Core i7-940 | Intel Core i7-920 |
| Частота ядра, ГГц | 3,30 | 3,20 | 3,20 | 3,06 | 2,93 | 2,66 |
| L1 Cache, КБ | 32/32 | 32/32 | 32/32 | 32/32 | 32/32 | 32/32 |
| L2 Cache, КБ | 4 x 256 | 4 x 256 | 4 x 256 | 4 x 256 | 4 x 256 | 4 x 256 |
| L3 Cache, МБ | 8 | 8 | 8 | 8 | 8 | 8 |
| Пропускная способность QPI, ГТ/с | 6,4 | 6,4 | 4,8 | 4,8 | 4,8 | 4,8 |
| TDP | 130 Вт | 130 Вт | 130 Вт | 130 Вт | 130 Вт | 130 Вт |
Процессор Intel Core i7-920 – представитель семейства Core i7 в ближайшее время покинет каталог производителя. Замена этой модели должна появиться в первом квартале 2010 года под обозначением Core i7-930, который будет рассчитан на установку в процессорное гнездо LGA 1366 и тактовую частоту 2,88 ГГц (напомним, Core i7-920 рассчитан на частоту 2,66 ГГц). Он получит четыре ядра, способных исполнять восемь потоков команд, 8 МБ кэш-памяти третьего уровня, встроенный трехканальный контроллер памяти DDR3. Значение TDP составит 130 Вт. Пока неизвестно, какой техпроцесс будет использован в производстве нового процессора — 45-нанометровый или 32-нанометровый. Цена изделия на момент дебюта составит $255.
Выводы
Conroe стал серьёзным фундаментом для новых процессоров, и Nehalem построен как раз на нём. Здесь используется такая же эффективная архитектура, но теперь она более модульная и масштабируемая, что должно гарантировать успех в разных рыночных сегментах.
Компания Intel впервые применила встроенный контроллер памяти, причем, сразу же трехканальный, и отказалась от использования шины FSB. Внедрение новых энергосберегающих функций и технологий позволят, как снизит нагрев, так и повысить быстродействие при выполнении однопоточных приложений. Кроме того, была возвращена технология Hyper-Threading, которая использовалась в процессорах Pentium 4. Несмотря на серверную архитектуру, новые CPU имеют все шансы стать именно настольными после внедрения многопоточной обработки в обычные и игровые приложения, которые поднимут эффективность данных процессоров.
Вполне очевидно, что самый серьёзный прирост будет в тех ситуациях, где основным "узким местом" была оперативная память. Кроме добавления встроенного контроллера памяти, который, без сомнения, даст наибольший прирост касательно операций доступа к данным, есть и множество других улучшений, как крупных, так и мелких – новая архитектура Cache и TLB, и блоки предварительной выборки.
Процессоры Core i7 изготовлены по 45 нм технологии, но в отличие от своих предшественников все четыре ядра расположены на одном кристалле. Тогда как Core 2 Quad состоит из двух ядер Core 2 Duo, объединенных в одном корпусе. Кроме того, процессоры Nehalem содержат Cache–память третьего уровня объемом 8 МБ, встроенный трехканальный контроллер памяти DDR3 и контроллер шины Quick Path Interconnect (QPI), которые потребовали значительное увеличение контактов – до 1366, из-за чего размеры CPU нового поколения стали больше и по форме он уже напоминает прямоугольник, а не квадрат как у Core 2. Естественно, ни о какой совместимости разъемов речи не идет.
Дата добавления: 2018-04-15; просмотров: 417; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!