РЕАЛИЗАЦИЯ СТОХАСТИЧЕСКОГО ГРАДИЕНТНОГО СПУСКА
Министерство образования и науки РФ
Федеральное государственное автономное образовательное учреждение
Высшего образования
«КАЗАНСКИЙ (ПРИВОЛЖСКИЙ) ФЕДЕРАЛЬНЫЙ УНИВЕРСИТЕТ»
ВЫСШАЯ ШКОЛА ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ И ИНФОРМАЦИОННЫХ СИСТЕМ
Специальность: 09.03.03. – Прикладная информатика
КУРСОВАЯ РАБОТА
Стохастический градиентный спуск. Варианты реализации.
Студент 2 курса
Группа 11-507
«__» __________20__г. __________ (Ибрагимов Э.Р.)
Научный руководитель
(преподаватель/куратор лаборатории)
«__» __________20__г. ___________ (Новиков П.А.)
Оглавление
ВВЕДЕНИЕ. 3
1 СТОХАСТИЧЕСКИЙ ГРАДИЕНТНЫЙ СПУСК.. 4
1.1 Предпосылки. 5
1.2 Итерационный метод. 7
1.3 Варианты реализации. 8
1.4 Momentum.. 9
1.5 AdaGrad. 10
1.6 RMSProp. 12
2 РЕАЛИЗАЦИЯ СТОХАСТИЧЕСКОГО ГРАДИЕНТНОГО СПУСКА.. 13
2.1 Реализация стандартного стохастического градиентного спуска. 13
2.2 Реализация Momentum.. 17
2.3 Реализация AdaGrad. 18
2.4 Реализация RMSProp. 19
3 ТЕСТИРОВАНИЕ И СРАВНЕНИЕ. 20
3.1 Тестирование стандартного стохастического градиентного спуска. 20
3.2 Тестирование Momentum.. 21
3.3 Тестирование AdaGrad. 22
3.4 Тестирование RMSProp. 23
ЗАКЛЮЧЕНИЕ. 24
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ.. 25
ВВЕДЕНИЕ
Градиентный спуск — метод нахождения локального экстремума (минимума или максимума) функции с помощью движения вдоль градиента.
|
|
|
Из всех методов локальной оптимизацииявляется наиболее простым в реализации. Имеет довольно слабые условия сходимости, но при этом скорость сходимости достаточно мала.
Градиентный спуск является популярным алгоритмом для широкого спектра моделей машинного обучения, в том числе нахождение опорных векторов, логистической регрессии и графических моделей . В сочетании с алгоритмом обратного распространения, это стандартный алгоритм для обучения искусственных нейронных сетей.Стохастический градиентный спуск конкурирует с алгоритмом L-BFGS, который также широко используется. Стохастический градиентный спуск был использован, по крайней мере, в 1960 для обучения линейных регрессионных моделей, первоначально под названием Adaline.
Целью данной курсовой работы является рассмотрение реализации нескольких вариантов стохастического градиентного спуска, последующее их сравнение, выяснение преимуществ и недостатков.
СТОХАСТИЧЕСКИЙ ГРАДИЕНТНЫЙ СПУСК
Стохастический градиентный спуск относится к оптимизационным алгоритмам и нередко используется для настройки параметров модели машинного обучения.
При стандартном градиентном спуске для изменения параметров модели используется градиент. Градиент обычно вычисляется как сумма градиентов, вызванных каждым элементом обучения. Вектор параметров изменяется в направлении антиградиента с заданным шагом. Поэтому стандартному градиентному спуску требуется один проход по обучающим данным до того, как он сможет менять параметры.
|
|
|
При стохастическом градиентном спуске значение градиента приближенно вычисляется градиентом функции стоимости, вычисленном только на одном элементе обучения. Затем параметры изменяются пропорционально приближенному градиенту. Таким образом параметры модели изменяются после каждого объекта обучения. Для больших массивов данных стохастический градиентный спуск может дать значительное преимущество в скорости по сравнению со стандартным градиентным спуском.
Между этими двумя видами градиентного спуска существует компромисс, называемый иногда «mini-batch». В этом случае градиент аппроксимируется суммой для небольшого количества обучающих образцов.
Предпосылки
Статистические оценки и машинное обучение рассматривают задачу минимизации функции , которая имеет вид:

где параметр  , который сводит к минимуму
, который сводит к минимуму  , должен быть оценен. Каждое слагаемое
, должен быть оценен. Каждое слагаемое  как правило ассоциируется с i-ым наблюдением в наборе данных (используется для обучения).
как правило ассоциируется с i-ым наблюдением в наборе данных (используется для обучения).
|
|
|
В классической статистике, проблема минимизации сумм возникает в методе наименьших квадратов, а так же в методе максимального правдоподобия (для независимых наблюдений). Общий класс оценок, которыйявляется результатом минимизации сумм, называется M-оценкой. Однако в статистике, уже давно признано, что требование даже локальной минимизации слишком ограничено для некоторых задач оценки максимального правдоподобия. Таким образом, современные статистические теоретики часто рассматривают стационарные точки на функции правдоподобия (нули производной, функция оценки и другие оценочные уравнения).
Проблема минимизации сумм возникает также в минимизации эмпирического риска . В этом случае,  это значение функции потерь при i-омнаборе, и эмпирический риск.
это значение функции потерь при i-омнаборе, и эмпирический риск.
При минимизации функции, стандартный (или «batch») градиентный спуск будет выполнять следующие итерации:

где  это размер шага (иногда называемый скоростью обучения в машинном обучении).
это размер шага (иногда называемый скоростью обучения в машинном обучении).
Во многих случаях функция слагаемого имеет простую модель, которая включаетнесложныевычисления функции суммы и суммы градиентов. Например, в статистике, экспоненциальные семейства с одним параметромдопускают экономичные вычисления функции и градиентов.
|
|
|
Тем не менее, в других случаях, оценки суммарного градиента могут потребовать дорогостоящую оценку градиентов от всех функций слагаемых. Когда обучающий набор огромен и не существует простых формул, оценка суммы градиентов становится очень дорогой, потому что оценка градиента требует оценки всех градиентов функций слагаемым. Для того, чтобы сэкономить на стоимости вычислений на каждой итерации, в стохастическом градиентном спускевыборкой является подмножество функций слагаемых на каждом шагу. Это очень эффективно в случае крупномасштабных задач машинного обучения.
Итерационный метод
В стохастическом градиентном спуске, истинный градиент приближенно выражается градиентом на данном примере:

Поскольку алгоритм несется через обучающий набор, он выполняет вышеописанные обновления для каждого учебного примера. Несколько проходов могут быть сделаны по обучающему множеству , пока алгоритм не будет сходится. Данные могут быть перемешены для каждого прохода, чтобы предотвратить циклы. Типичные реализации могут использовать адаптивную скорость обучения так , чтобы алгоритм сходился.
В псевдокоде стохастический градиентный спуск может быть представлен следующим образом:
1) Выбрать исходный вектор параметра и скорость обучения .
2) Повторять до тех пор, пока не будетприблизительно получено минимальное:
2.1 ) Случайно перетасовать примеры в обучающем наборе.
2.2 ) Для i = 1,2, ...,n, делать:
Сходимость стохастического градиентного спуска была проанализирована с помощью теории выпуклой минимизации и стохастической аппроксимации. Когда скорость обученияубывает с подходящей скоростью, и при относительно слабых допущении, стохастический градиентный спуск сходится к глобальному минимуму, когда функция является выпуклой или псевдо выпуклой, а в противном случае сходится к локальному минимуму.
Варианты реализации
Множество улучшенийбыло предложено и использовано по сравнению с основным методом стохастического градиентного спуска. В частности, в машинном обучении, необходимость установить скорость обучения (размер шага) было признано проблематичным.
Если задать этот параметр слишком большим, то это может привести к тому, что алгоритм будет расходиться. Если наоборот, то алгоритм будет медленно сходиться.
Концептуально простое расширение стохастического градиентного спуска сделать скорость обучения в виде убывающей функции  , зависящая от числа итераций m.
, зависящая от числа итераций m.
Проделав данную операцию, видно, что первые итерации вызывают большие изменения в параметрах, в то время как более поздние делаютболее только тонкую настройку.
В рамках данной работы будут рассмотрены следующие варианты реализации стохастического градиентного спуска:
1) Momentum
2) AdaGrad
3) RMSProp
Momentum
Momentum,так же известный как метод импульса, появился благодаряамериканскому психологу Дэвиду Рамелхарту, а так же на основе работ Джеффри Хинтонаи Роналда J Уильямсаприизучении метода обратного распространения. Стохастический градиентный спуск с импульсом запоминает обновления 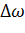 на каждой итерации, и определяет следующее обновление в виде линейной комбинации градиента и предыдущего обновления:
на каждой итерации, и определяет следующее обновление в виде линейной комбинации градиента и предыдущего обновления:


Что приводит к:

где параметр , который сводит к минимуму , должен быть оценен и размер шага (иногда называемый скоростью обучения в машинном обучении).
Название импульс происходит по аналогии с импульсом в физике: вектор веса . Мысль о том, что перемещение материальной точки через пространство параметров, влечет за собой ускорение благодаря силе, в качестве которой выступает градиент потерь.
В отличие от классического метода стохастического градиентного спуска, он стремится держать движение в одном направлении, предотвращая колебания. Momentum был успешно применен в течение нескольких десятилетий.
AdaGrad
AdaGrad представляет собой модифицированный стохастический градиентный спуск с предварительным параметром скорости обучения. Впервые опубликован в 2011. Неформально, он увеличивает скорость обучения для более разреженных параметров и уменьшает скорость обучения менее разреженный из них. Эта стратегия часто повышает вероятность сходимости по сравнению со стандартным алгоритмом стохастического градиентного спуска в тех местах , где данные немногочисленны и редкие параметры являются более информативными.
Примеры таких применений включают обработку естественного языка и распознавание образов.
Он по-прежнему имеет базу скорости обучения , но умножается на элементы вектора 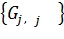 , который является диагональю тензорного произведения матрицы.
, который является диагональю тензорного произведения матрицы.

где  градиент при итерации m.
градиент при итерации m.
Диагональ задается в виде:

Вектор обновляется после каждой итерации. Формула для обновления теперь выглядит так:

или записывается в виде обновления предварительного параметра,

Каждый  повышает масштабируемость коэффициента для скорости обучения , который применяется к одному параметру
повышает масштабируемость коэффициента для скорости обучения , который применяется к одному параметру  .
.
Так как знаменатель  является евклидовой нормой предыдущих производных, предельные значения параметров обновления сдерживают, в то время как параметры, у которых были небольшие обновления получают более высокий уровень обучения.
является евклидовой нормой предыдущих производных, предельные значения параметров обновления сдерживают, в то время как параметры, у которых были небольшие обновления получают более высокий уровень обучения.
В то время как велась работа над проблемами выпуклой оптимизации, AdaGrad был успешно использован к задачам невыпуклой оптимизации.
RMSProp
RMSProp также является способом, в котором скорость обучения адаптирована для каждого из параметров. Идея заключается в том, чтобы разделить скорость обучения для определенного веса на скользящую среднюю величин последних градиентов для этого веса. Таким образом, первая скользящая средняя рассчитывается в виде квадрата:

где  это параметр экспоненциального взвешивания, или параметр «забывания» («forgetting factor»)
это параметр экспоненциального взвешивания, или параметр «забывания» («forgetting factor»)
Параметры обновляются с помощью формулы ниже:

RMSProp показал отличную адаптацию скорости обученияв различных приложениях. RMSProp можно рассматривать как обобщение Rprop и так же он способен работать с таким вариантом градиентного спуска как mini-batch, который противопоставлен обычному градиентному спуску.
РЕАЛИЗАЦИЯ СТОХАСТИЧЕСКОГО ГРАДИЕНТНОГО СПУСКА
На данном этапе будут выполнены реализации нескольких вариантов стохастического градиентного в виде программного кода на языке программирования Python.
Дата добавления: 2018-04-05; просмотров: 1285; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!