УВАЖАЕМОЕ СЛОВО, К ЛИЦУ ЛИ ВАМ ВАША ФОРМА? 2 страница
Работа, как видите, нелегкая. Но это бы еще не беда. Трудность, во-первых, в том, что в звукосочетаниях действуют особые законы, которые могут приводить к резкому изменению звуков. Так, на конце слов звонкие согласные будут оглушаться, и вместо бад и бид получится [бат] и [бит]. Поэтому звонкие согласные можно получить только в начальной позиции. А здесь — другая сложность: перед А, О, У, Ы согласные будут твердыми, а перед И, Е — мягкими. Значит, «слова» бат и бит различаются не только гласными А— И, но и согласными Б — Б . На что же реагирует информант — на различие гласных или согласных? Или на то и другое вместе?
Во-вторых, для того чтобы так оценить все звуки, нужно построить большое количество звукосочетаний, и тогда среди них начинают появляться обычные слова. А в этом случае, понятно, информанты
9
реагируют не на звуки, а на смысл слов. Скажем, если вы спросите информантов, что больше — кит или кот, то получите единодушный ответ — кит и в результате сделаете неверный вывод, что И больше, чем О.
А не попытаться ли как-то оценивать отдельные звуки? Попробовали. Маленьким детям показывают две матрешки — во всем одинаковые, только одна совсем маленькая, другая — большая. Говорят: «Вот две сестрички. Одну зовут А, другую — И. Отгадай, которую зовут И?» И представьте себе — большинство детей показывает на маленькую матрешку.
Одну девочку спросили:
— А почему ты думаешь, что эту матрешку зовут И? Та отвечает:
|
|
|
— А потому что она маленькая.
Вот как прочно связан у нее звук с определенным представлением.
Но все же дети есть дети. Один отвлекся, другой указывает матрешку, не вникая в смысл вопроса, третий закапризничал. А ведь нужно перебрать и предъявить маленьким информантам все (!) возможные в данном языке пары звуков. Да нужно еще придумать, как задать детям и другие признаки, кроме признаков «большой — маленький». Представляете, что это за работа! Она, во-первых, невероятно трудоемка, а во-вторых, дает все же результаты, искаженные разного рода посторонними «шумами».
РЕШЕНИЕ
Однажды теплым летним днем мы гуляли по берегу очаровательной речки Хопёр с психологом Ю. М. Орловым и беседовали о нашумевшей тогда книге американского психолингвиста Ч. Осгуда «Измерение значения», где предлагалось «измерять» значение слова с помощью так называемых признаковых шкал.
— Вообще-то, конечно,— рассуждал Юрий Михайлович,— мы постоянно взвешиваем на весах признаков все, что угодно. Одно нам кажется очень приятным, другое приятным, но не очень, третье — так себе, а что-то представляется просто отвратительным. Одно мы считаем нежным, другое грубым. Что-то мы оцениваем как стремительное, а что-то как медлительное.
|
|
|
Он нагнулся и взял горсть речных камешков.
— Вот хотя бы эти камешки — один округлый, совсем как шарик, другой менее округлый, а вот этот острый, угловатый. Можно их расположить и по признакам светлый — темный, большой — маленький или красивый — некрасивый... Слушай! — Он вдруг остановился.— А звуки? Звуки речи! Пусть информанты располагают на признаковых шкалах все звуки речи.
Так возникла идея оценивать с помощью разных признаков отдельно взятые звуки речи, и оказалось, что это именно тот путь, который позволил не только обнаружить у звуков речи какую-то
10
содержательность, но и буквально измерить эти тонкие, почти не осознаваемые нами свойства звуков.
Давайте вместе с вами пройдем шаг за шагом всю процедуру анализа фонетической значимости, и, если вам будет интересно, вы сможете сами провести такие измерения со своими друзьями.
Инструментом для измерения служит шкала, образованная из двух антонимичных прилагательных типа хороший — плохой, большой — маленький и т. п. Для каждого из прилагательных с помощью слова очень образуются две степени сравнения: очень хороший, хороший; очень плохой, плохой.
|
|
|
Затем строятся шкалы, похожие на шкалу школьных оценок:
очень хороший — 1 очень большой — 1 очень нежный — 1
хороший — 2 большой —2 нежный — 2
никакой — 3 никакой — 3 никакой — 3
плохой — 4 маленький — 4 грубый — 4
очень плохой — 5 очень маленький — 5 очень грубый — 5
И так для многих слов, обозначающих признак предмета: сильный — слабый, светлый — темный, быстрый — медленный, округлый — угловатый, гладкий — шероховатый, легкий — тяжелый и др.
Теперь нужно еще построить список звуков, с которыми предстоит проводить эксперименты. И здесь нас поджидает вот какая трудность. Необходимо отобрать лишь те звуки, которые представляют для нас психологическую реальность, осознаются нами как звуки.
Если спросить любого говорящего по-русски, какие звуки произносятся после С в словах садовод и сыровар, всякий скажет, что в первом слове — А, во втором — Ы. Но на самом деле в первом слове произносится очень слабый, нечеткий (редуцированный) звук, нечто среднее между А, О, Ы. Значит, физически и в том, и в другом случае звучит сходный звук, а психологически осознаются, воспринимаются сознанием два совершенно разных звука (А и Ы). Почему?
|
|
|
Во-первых, мы знаем, что в сильной, ударной позиции в первом случае появится А (сад), а во втором — Ы (сыр), и это знание как бы подсказывает нам выбор звука в неясной, слабой позиции.
Во-вторых, потому, что в словах садовод и сыровар для обозначения сходных звуков пишутся разные буквы. Графический, буквенный образ не может не оказывать влияния на восприятие звука. Когда вы видите букву, у вас в сознании сейчас же звучит соответствующий звук, и наоборот. Буква как бы стабилизирует восприятие звука, помогает выработать в сознании типический образ звука и закрепляет его с помощью графического изображения. Даже если мы не читаем, а слушаем или произносим слова садовод и сыровар, буквы оказывают давление на наше восприятие, заставляя воспринимать разумом не совсем то, что воспринимается слухом.
Это хорошо заметно на таком примере. Буквы Е, Е, Ю, Я изображают в отдельном произношении звукосочетания [йэ], [йо], [йу], [йа]. Но мы привыкли к обозначению каждого такого звукосочетания одной буквой и, хотя слышим два звука, разумом восприни-
11
маем единый звукобуквенный образ. Физически звучит [йу], а психологически мы воспринимаем единый образ — Ю, сформированный в нашем сознании буквой.
Но с другой стороны, буква не отражает всех психологически важных особенностей звуков речи. Например, русскими четко осознаются различия между твердыми и мягкими согласными, поскольку эти различия играют важную смыслоразличительную роль. Мы не спутаем на слух слова угол и уголь, мел и мель, хотя различия в их звучании невелики. А в алфавите это важное свойство звуков — мягкость и твердость — не отражено: и для [л] и для [л'] есть только одна буква — Л.
И тем не менее нашему восприятию эти расхождения между звуком и буквой не помеха. Потому что мы не осознаем отдельно звука или отдельно буквы, а воспринимаем единый звукобуквенный образ.
Это очень хорошо чувствуют поэты. У А. Вознесенского в стихотворении «Мелодия Кирилла и Мефодия» есть такая строчка:
И фырчет «Ф», похожее на филина.
Что здесь «Ф» — звук или буква? Что это за средний род — «похожее»? В стихотворении речь идет о славянской азбуке, созданной Кириллом и Мефодием. Значит, буква? Но тогда нужно было бы написать: «Ф» — похожая на филина». В чем же поэт видит сходство? Очевидно, и в звучании (филин фыркает и пыхтит, будто произносит этот звук), и в зрительном образе («лицо» птицы с двумя светлыми овалами вокруг глаз действительно похоже на эту букву). Получается, что «звукообраз» филина сравнивается со «звукообразом» Ф, т. е. с чем-то средним между звуком [ф'] и буквой Ф. Поэт, надо полагать, был далек от такого рода рассуждений. Просто он почувствовал, что дело здесь не только в букве и не только в звуке — при восприятии важен звукобуквенный психический образ. (Дальше мы увидим, что поэты в стихах, как правило, ориентируются именно на такие звукобуквы.)
Таким образом, придется в наших экспериментах учесть как особенности звучания, так и особенности графического изображения. С одной стороны, придется включить в список для эксперимента твердые и мягкие согласные (Р и Р\ Д и Д', Г и Г' и т. п.), хотя они изображаются одной буквой. С другой стороны — буквы Е, Е, Ю, Я, хотя они изображают по два звука.
Но в дальнейшем, чтобы не усложнять изложение введением нового термина, будем эти звукобуквы именовать звуками, за исключением тех случаев, когда могут возникнуть недоразумения. Тогда уж придется уточнять, что имеется в виду: «чистый» звук, «чистая» буква или звукобуква.
Отобранные для эксперимента звуки нужно расположить в случайной последовательности, чтобы алфавитный порядок не «подсказывал» очередного элемента и не мешал оценкам. Так был получен ряд из 46 звукобукв, фрагмент которого приведен в таблице 1 «Приложения» (см. с. 153).
12
Можно начинать эксперимент. В нем участвуют экспериментатор и информанты — люди, для которых русский язык является родным. Экспериментатор дает информантам одну из шкал и поочередно предъявляет звуки. Информанты записывают очередной звук и ставят ему оценку по шкале, руководствуясь следующей инструкцией (пример для шкалы «светлый — темный»): «На ваших листах записана шкала, с помощью которой вы будете оценивать звуки и буквы, которые я буду произносить и показывать. Если вам почему-либо кажется, что данный звук «очень светлый», то вы приписываете ему оценку 1, если кажется, что звук «очень темный», приписываете оценку 5. Соответственно ставьте и другие оценки шкалы. Если звук не кажется вам ни «светлым», ни «темным», ставьте оценку 3. Старайтесь не раздумывать, а ставить первые пришедшие в голову оценки».
Звуки предъявляются довольно быстро, иначе информанты начнут искать логическое обоснование своих решений, например вспоминать слова с тем звуком, который оценивается. И тогда будет оцениваться значение слова, а не впечатление от звука.
Для того чтобы в сознании информанта возник четкий звуко-буквенный образ, экспериментатор произносит звук, затем показывает соответствующую букву и еще раз произносит звук. Понятно, что эксперимент проходит в полной тишине и все работают строго самостоятельно. Чтобы участники эксперимента работали совершенно свободно, ответы должны быть безымянными.
Почти всегда информанты спрашивают:
— А что значит «светлый» или «темный»?
— Не знаю,— отвечает экспериментатор.
— А как же ставить оценки?
— Ставьте как хотите.
— Ну хорошо, будем ставить наугад. Экспериментатор соглашается: „Что ж, ставьте наугад". Информанты ставят «отметки» всем звукам, которые предъявляет экспериментатор, и на этом эксперимент заканчивается.
Дальше следует обработка результатов. И вот оказывается, что «наугад» (как им кажется) участники эксперимента ставят звуку О, например, почти только 1 и 2, а звуку Ш — почти только 4 и 5!
Теперь посмотрите, как удобно, что восприятие звуков выражено числом. Это дает нам возможность буквально вычислить, насколько «светел» О и насколько «темен» Ш по коллективному мнению всех, кто участвовал в эксперименте. Информанты, сами того не ведая, «измеряют» то, чего не знают!
Действительно, представьте себе, что мы просто задали участникам эксперимента вопрос: «Какие впечатления вызывает у вас звук Д?» Ясно, что ответы будут самыми разными и уловить что-то общее в этом множестве ответов будет очень трудно. А с помощью измерительной шкалы легко можно определить «усредненное мнение» информантов хотя бы путем вычисления среднего арифметического всех поставленных ими оценок.
13
Чтобы такое среднее арифметическое было надежным, необходимо вычислять его по ответам большого числа информантов, ни в коем случае не менее 50. Причем лучше всего, чтобы это число 50 было составлено из ответов двух групп по 25 человек. Тогда можно даже вычислить коэффициент надежности результатов. Этот коэффициент укажет, насколько сходными оказались ответы в двух группах. Ведь если средние оценки, вычисленные по ответам одной группы, резко отличаются от средних, полученных по ответам другой, значит, эти средние случайны, ненадежны, и в разных сериях экспериментов будут получаться разные средние. Если же две разные группы дали сходные ответы, сходные средние оценки, то можно считать, что и в любом другом эксперименте получатся примерно те же результаты.
Конечно, в работе с информантами много тонкостей, не все сразу предусмотришь. Вы заметили, что нумерация делений шкал у нас прямо противоположна шкале школьных оценок: в школе 5 — очень хорошо, а 1 — очень плохо; у нас наоборот — 1 — очень хорошо, а 5 — очень плохо. И это не случайно. Оказывается, если цифры расположить как в школьной шкале, то все средние оценки звуков несколько сдвинутся в «хорошую» сторону. В чем дело? Видимо, оказывают свое влияние школьные пристрастия: информантам приятно ставить пятерки и четверки, а двойки и единицы — рука не поднимается.
Разгадывание таких психологических тонкостей требует проведения все новых и новых серий экспериментов. Так что иногда приходится повторять каждый эксперимент не два, а четыре-пять раз, чтобы получить устойчивые и действительно средние оценки.
А всего нам пришлось обработать более 100 тысяч ответов самых разных людей — учеников и учителей, студентов и профессоров, рабочих, колхозников и т. д.
Так сформировалась таблица, содержащая средние оценки всех русских звукобукв по признаковым шкалам. Всего звукобукв оказалось 346, шкал было взято 25, следовательно, таблица содержит 1150 оценок. Для наглядности в «Приложении» приведен ее фрагмент (см. таблицу 1 на с. 153).
Конечно, измерение можно вести не только по этим шкалам. В принципе чем больше шкал, тем лучше: полнее характеристика содержательности звуков. Но, во-первых, такая погоня за материалом бесконечна, а где-то все же нужно остановиться. Во-вторых, мы старались построить шкалы из слов, обозначающих наиболее важные, наиболее существенные признаки. И ниже будет показано, что в общем-то так оно и получилось.
В верхней строке таблицы указаны некоторые русские звуко-буквы. А цифры таблицы — это средние оценки каждой звукобуквы по каждой шкале.
Что означают эти средние оценки? Допустим, что в ответах пятидесяти человек по шкале «сильный — слабый» для звука Д встретилось 9 единиц, 34 двойки, 5 троек, 2 четверки и ни одной пятерки.
И
Среднее арифметическое составит:
9X1+34X2 + 5X3 + 2X4 =20 50
Это значит, что в общем «среднеарифметический, коллективный» носитель русского языка воспринимает этот звук как «сильный». Несмотря на то, что некоторые посчитали его «никаким», а двое даже «слабым».
Понятно, что если большинство информантов поставит какому-либо звуку тройки, то и средняя будет расположена возле этой оценки, т. е. звук окажется «никаким». Тот же результат получится, если выбор каждой оценки окажется действительно случайным: тогда каждая из оценок будет приписана звуку примерно одинаковое число раз, а это в среднем даст оценку, близкую к тройке («никакой»).
Случись так для всех звуков по всем шкалам, и мы должны были бы констатировать, что звуки не вызывают у нас никаких впечатлений, по любому признаку они «никакие». Но таблица 1 показывает, что средние для большинства звуков и по большинству шкал явно отклоняются от 3,0.
Конечно, здесь нужно решить вопрос о том, какое отклонение считать существенным, значимым. Для решения этой задачи существуют специальные математические приемы, но сущность операции можно пояснить следующим образом. Пока отклонение не достигло половины деления шкалы, средняя еще тяготеет к тройке, а затем уже приближается к значимой оценке. Например, оценки 2,6 или 3,4 ближе к 3,0, чем к 2,0 или 4,0; но 2,4 или 3,6 уже приближаются, соответственно, к 2,0 или 4,0. Значит, границами существенных отклонений логично выбрать 2,5 и 3,5. Эти пояснения наглядно изображает график:
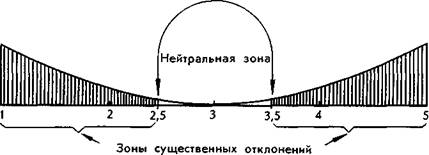
Средняя оценка только тогда является значимой, т. е. свидетельствует о том, что по данному признаку звук вызывает какое-то впечатление, когда эта оценка попадает в одну из зон значимых отклонений. Например, звук А по шкале «хороший — плохой» получил среднюю оценку 1,5. Эта средняя меньше 2,5, следовательно,
15
попадает в зону значимых отклонений, и потому мы можем считать, что звук А большинством говорящих на русском языке оценивается как «хороший». Звук X' по той же шкале получил оценку 4,3. Это больше, чем 3,5, следовательно, этот звук, по мнению большинства участников эксперимента, «плохой». Звук М — «хороший»: его оценка 2,5; тогда как Щ — «плохой»: он получил среднюю оценку 3,5. А вот звуки Р (2,6), В' (3,4), К (3,0) по этой шкале «никакие», поскольку их средние оценки не выходят за пределы нейтральной зоны шкалы.
Здесь, пожалуй, следует немного задержаться, чтобы обсудить одно важное обстоятельство. Содержательность звуков — совсем новая область исследований. Многое здесь непривычно. Никто не удивляется, когда говорят «мягкие и твердые звуки», но часто возникают возражения, когда речь идет о «хороших» и «плохих», «светлых» и «темных» или «нежных» и «грубых» звуках речи.
— Что же «плохого» в звуке Ф ?— удивляется возражающий.— Звук как звук. И мне нравится.
Вполне возможно, что звук Ф' кто-то посчитает «хорошим». Загляните в таблицу. Его оценка по этой шкале 4,2, а не 5. Не все информанты поставили этому звуку пятерки, были и четверки, и тройки, очень редко двойки и даже одна единица. Разные могут быть причины «хорошего» отношения к Ф . Может быть, имя информанта — Федор и ему нравится первый звук своего имени. Или фамилия на этот звук начинается. Или любимый цветок — фиалка. А может, просто отвлекся информант, а то и из озорства или упрямства ответил «наоборот». И такое бывает.
Но если даже один человек твердо убежден, что звук Ф красивый и приятный, а звук Ш — «светлый», это все равно не может опровергнуть выводов эксперимента. Неважно, как некто оценивает Ф или Ш, пусть даже этот некто и крупный авторитет в филологии. Важно, как оценивает эти звуки большинство говорящих по-русски.
Вы можете возразить:
— А как же Коперник? Не только большинство, а все люди его времени были убеждены, что Солнце вращается вокруг Земли, только он один думал иначе. И именно он оказался прав, а не большинство. И это не единственный случай, когда прав один, а большинство заблуждается. Или возьмите «оптические обманы». Все в один голос говорят, что один отрезок больше другого, а на самом деле они равны.
Да, все это так, но только тогда, когда есть вот это — «на самом деле». Когда есть объективная истина, объективный эталон наших суждений.
В языке все обстоит несколько иначе. В языке коллективное — и есть действительное, объективное. Каково «правильное» значение слова век? Оно именно такое, как считают носители русского языка,— «столетие». Может ли один носитель языка придать этому слову другое значение, например «сила»? Пожалуйста, но этого
16
человека никто не поймет, и потому он не станет так делать. Хотя именно такое значение имело в далеком прошлом слово век — «сила», «здоровье». Но бесполезно пытаться в одиночку возродить это «правильное» значение: теперь «правильным» стало новое значение, потому что оно коллективно.
Вот интересный случай. По-русски запоминать — значит «сохранять в памяти», а по-польски сходно звучащее слово zaporninac означает «забывать». А ведь у русского и польского один язык-предок. Кто же сохранил «правильное» значение — мы или поляки? Такой вопрос лишен смысла. Оба значения правильны, поскольку оба — коллективны в своих языках.
Дата добавления: 2018-02-28; просмотров: 304; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!