Прямой и обратный порядок байтов
Существует два способа адресации байтов в словах, а именно в прямом и обратном порядке (рис. 4.8). Обратным порядком байтов (big-endian) называется система адресации, при которой байты адресуются слева направо, так что самый старший байт слова (расположенный с левого края) имеет наименьший адрес. Прямым порядком байтов (little-endian) называется противоположная система адресации, при которой байты адресуются справа налево, так что наименьший адрес имеет самый младший байт слова (расположенный с правого края). Слова «старший» и «младший» определяют вес бита, то есть степень двойки, соответствующей данному биту, когда слово представляет число. В машинах для коммерческих расчетов используются обе системы адресации. В обеих этих системах адреса байтов 0,4, 8 и т. д. применяются в качестве адресов последовательных слов памяти в операциях чтения и записи слов.
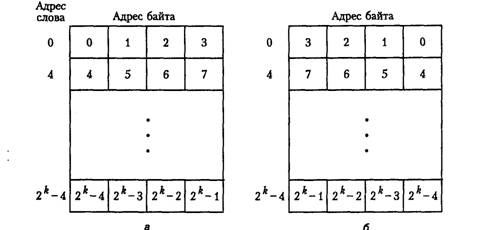
Рис. 4.8. Адресация байтов и слов: обратный порядок байтов (а);
прямой порядок байтов (б)
В компьютерах, использующих процессоры Intel, все данные хранятся так, что младший байт находится по младшему адресу, так что слова записываются задом наперед, то есть сначала (по младшему адресу) записывают последний (младший) байт, а потом (по старшему адресу) записывают первый (старший) байт. Если из программы всегда обращаться к слову как к слову, а к двойному слову как к двойному слову, это не оказывает никакого влияния. Но если вы хотите прочитать первый (старший) байт из слова в памяти, придется увеличить адрес на 1. Двойные и учетверенные слова записываются так же — от младшего байта к старшему.
|
|
|
Наряду с порядком байтов в слове важно также определить порядок битов в байте. Типичный способ расположения битов показан на рис. 4.7, а. Это наиболее естественный порядок битов для кодирования числовых данных, непосредственно соответствующий их разрядам. Этот же порядок использован на рисунке при обозначении битов: b7,b6, …,b0 (слева направо). Однако существуют компьютеры, для которых характерен обратный порядок битов.
Расположение слов в памяти
В случае 32-разрядных слов их естественные границы располагаются по адресам 0, 4, 8 и т. д. (рис. 4.8). При этом мы говорим, что слова выровнены по адресам в памяти. Если говорить, в общем, слова считаются выровненными в памяти в том случае, если адрес начала каждого слова кратен количеству байтов в нем. По практическим причинам, связанным с манипулированием двоично-кодированными адресами, количество байтов в слове обычно является степенью двойки. Поэтому, если длина слова равна 16 (2 байтам), выровненные слова начинаются по байтовым адресам 0, 2, 4,..., а если она равна 64 (23 байтам), то выровненные слова начинаются по байтовым адресам 0, 8, 16, ... .
|
|
|
Не существует причины, по которой слова не могли бы начинаться с произвольных адресов. Такие слова называются невыровненными. Как правило, слова выравниваются по адресам памяти, но в некоторых компьютерах это не так.
Доступ к числам, символам и символьным строкам
Обычно число занимает целое слово. Поэтому, для того чтобы обратиться к нему в памяти, нужно указать адрес слова, по которому оно, это число, хранится. Точно так же доступ к отдельно хранящемуся в памяти символу осуществляется по адресу его байта.
Во многих приложениях необходимо обрабатывать строки символов переменной длины. Для доступа к такой строке нужно указать адрес байта, в котором хранится ее первый символ. Последовательные символы строки содержатся в последовательных байтах. Существует два способа определения длины строки. Первый из них заключается в использовании специального управляющего символа, обозначающего конец строки и являющегося ее последним символом. Второй способ состоит в использовании отдельного слова памяти или регистра процессора, содержащего число, которое определяет длину строки в байтах.
Дата добавления: 2018-02-18; просмотров: 1662; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!