Производная показательной функции.
y=a x, [a x]/=a xlna.
Производные тригонометрических функций.
y=sinx, y=tgx, y=ctg
(cosx)/=−sinx. (tgx)/=1cos2x. (ctgx)/=−1sin2x.
Производные обратных тригонометрических функций.
y=arcsinx. y=arccosx, y=arctgx, y=arcctgx,
x=siny, x=cosy, x=tgy, x=ctgy,
9)Цепное правило (правило дифференцирования сложной функции) позволяет вычислить производную композиции двух и более функций на основе индивидуальных производных. Если функция f имеет производную в точке x0, а функция g имеет производную в точке y0 = f(x0), то сложная функция h(x) = g(f(x)) также имеет производную в точке x0.
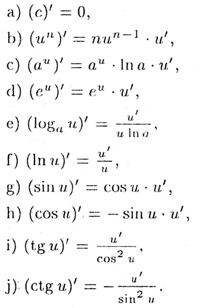
10) Замена переменной в неопределенном интеграле производится с помощью подстановок двух видов:
а) 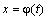 , где
, где
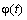 – монотонная, непрерывно дифференцируемая функция новой переменной t. Формула замены переменной в этом случае: ;
– монотонная, непрерывно дифференцируемая функция новой переменной t. Формула замены переменной в этом случае: ;
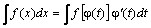
б) 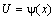 , где U – новая переменная. Формула замены переменной при такой подстановке: .
, где U – новая переменная. Формула замены переменной при такой подстановке: .
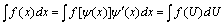
Найти интеграл .
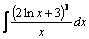
Решение. Перепишем данный интеграл в виде

. Так как производная выражения
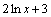
равна 2/х, а второй множитель 1/х отличается от этой производной только постоянным коэффициентом 2, то нужно применить подстановку
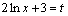
. Тогда .
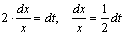
Следовательно,
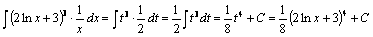
11)Интегри́рование по частя́м — один из способов нахождения интеграла. Суть метода в следующем: если подынтегральная функция может быть представлена в виде произведения двух непрерывных и гладких функций (каждая из которых может быть как элементарной функцией, так и композицией), то справедливы следующие формулы
|
|
|
для неопределённого интеграла:
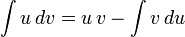
для определённого:
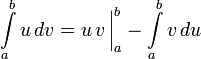
Предполагается, что нахождение интеграла
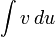
проще, чем
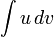
.
12)
Функция распределения полностью характеризует случайную величину, однако, имеет один недостаток. По функции распределения трудно судить о характере распределения случайной величины в небольшой окрестности той или иной точки числовой оси.
Определение. Плотностью распределения вероятностей непрерывной случайной величины Х называется функция f(x) – первая производная от функции распределения F(x).
Плотность распределения также называют дифференциальной функцией. Для описания дискретной случайной величины плотность распределения неприемлема.
Смысл плотности распределения состоит в том, что она показывает как часто появляется случайная величина Х в некоторой окрестности точки х при повторении опытов.
После введения функций распределения и плотности распределения можно дать следующее определение непрерывной случайной величины.
|
|
|
Определение. Случайная величина Х называется непрерывной, если ее функция распределения F(x) непрерывна на всей оси ОХ, а плотность распределения f(x) существует везде, за исключением( может быть, конечного числа точе
Зная плотность распределения, можно вычислить вероятность того, что некоторая случайная величина Х примет значение, принадлежащее заданному интервалу.
13)
Математическое ожидание , среднее значение, одна из важнейших характеристик распределения вероятностей случайной величины. Для случайной величины X, принимающей последовательность значений y1, y2, ..., yk, ... с вероятностями, равными соответственно p1, p2, ...,pk
Свойства:
1) M(C) = C, C - постоянная;
2) M(CX) = CM(X);
3) M(X1 + X2) = M(X1) + M(X2), где X1, X2 - независимые случайные величины;
4) M(X1X2) = M(X1)M(X2).
Дисперсия . - в статистике дисперсия есть среднее арифметическое из квадратов отклонений наблюденных значений (x1, x2,...,xn) случайной величины от их среднего арифметического
Свойства:
1) D(C) = 0;
2) D(CX) = C2D(X);
3) D(X1 + X2) = D(X1) + D(X2), где X1, X2 - независимые случайные величины.
Среднее квадратическое отклонение случайной величины Х - называется квадратный корень из дисперсии.
|
|
|
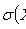
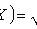
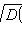

14) ?
равномерное распределение – n случайных чисел выпадает с одной и той же вероятностью p=1/n; характеризуется нижней и верхней границей; примером является появление чисел 1, 2, …, 6 при бросании игральной кости (p=1/6);
биномиальное распределение моделирует взаимосвязь числа успешных испытаний m и вероятностей успеха каждого испытания p при общем количестве испытаний
нормальное (гауссово) распределение описывает процессы, в которых на результат воздействует большое число независимых случайных факторов, среди которых нет сильно выделяющихся
распределение Пуассона, предсказывает число случайных событий на определенном отрезке времени или на определенном пространстве, позволяет аппроксимировать биномиальное распределение
экспоненциальное (показательное) распределение, моделирует временные задержки между событиями, описывает процессы в задачах массового обслуживания и в задачах с «временем жизни»
распределение хи-квадрат, связано с нормальным, возвращает одностороннюю вероятность распределения и используется для сравнения предполагаемых и наблюдаемых значений
|
|
|
распределение Стьюдента, связано с нормальным, возвращает вероятность для t-распределения Стьюдента и используется для проверки гипотез при малом объеме выборки
F-распределение (Фишера), связано с нормальным и может быть использовано в F-тесте, который сравнивает степени разброса двух множеств данных
15)Корреля́ция (корреляционная зависимость) — статистическая взаимосвязь двух или нескольких случайных величин (либо величин, которые можно с некоторой допустимой степенью точности считать таковыми). При этом изменения значений одной или нескольких из этих величин сопутствуют систематическому изменению значений другой или других величин.[1] Математической мерой корреляции двух случайных величин служит корреляционное отношение [2], либо коэффициент корреляции (или )[1]. В случае, если изменение одной случайной величины не ведёт к закономерному изменению другой случайной величины, но приводит к изменению другой статистической характеристики данной случайной величины, то подобная связь не считается корреляционной, хотя и является статистической[3].
Впервые в научный оборот термин «корреляция» ввёл французский палеонтолог Жорж Кювье в XVIII веке. Он разработал «закон корреляции» частей и органов живых существ, с помощью которого можно восстановить облик ископаемого животного, имея в распоряжении лишь часть его останков. В статистике слово «корреляция» первым стал использовать английский биолог и статистик Фрэнсис Гальтон в конце XIX века.[4]
Регре́ссия (лат. regressio — обратное движение, отход), в теории вероятностей и математической статистике, зависимость среднего значения какой-либо величины от некоторой другой величины или от нескольких величин. В отличие от чисто функциональной зависимости y=f(x), когда каждому значению независимой переменной x соответствует одно определённое значение величины y, при регрессионной связи одному и тому же значению x могут соответствовать в зависимости от случая различные значения величины y. Если при каждом значении x=xi наблюдается ni значений yi1…yin1 величины y, то зависимость средних арифметических =(yi1+…+yin1)/ni от x=xi и является регрессией в статистическом понимании этого термина[1].
Этот термин в статистике впервые был использован Френсисом Гальтоном (1886) в связи с исследованием вопросов наследования физических характеристик человека. В качестве одной из характеристик был взят рост человека; при этом было обнаружено, что в целом сыновья высоких отцов, что не удивительно, оказались более высокими, чем сыновья отцов с низким ростом. Более интересным было то, что разброс в росте сыновей был меньшим, чем разброс в росте отцов. Так проявлялась тенденция возвращения роста сыновей к среднему (regression to mediocrity), то есть «регресс». Этот факт был продемонстрирован вычислением среднего роста сыновей отцов, рост которых равен 56 дюймам, вычислением среднего роста сыновей отцов, рост которых равен 58 дюймам, и т. д. После этого результаты были изображены на плоскости, по оси ординат которой откладывались значения среднего роста сыновей, а по оси абсцисс — значения среднего роста отцов. Точки (приближённо) легли на прямую с положительным углом наклона меньше 45°; важно, что регрессия была линейной.
16) Центра́льные преде́льные теоре́мы (Ц.П.Т.) — класс теорем в теории вероятностей, утверждающих, что сумма достаточно большого количества слабо зависимых случайных величин, имеющих примерно одинаковые масштабы (ни одно из слагаемых не доминирует, не вносит в сумму определяющего вклада), имеет распределение, близкое к нормальному.
Так как многие случайные величины в приложениях формируются под влиянием нескольких слабо зависимых случайных факторов, их распределение считают нормальным. При этом должно соблюдаться условие, что ни один из факторов не является доминирующим. Центральные предельные теоремы в этих случаях обосновывают применение нормального распределения.
Ц.П.Т. Ляпунова
Пусть выполнены базовые предположения Ц.П.Т. Линдеберга. Пусть случайные величины
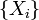
имеют конечный третий момент. Тогда определена последовательность
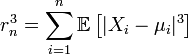
. Если предел

(условие Ляпунова),
то
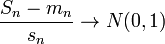
по распределению при .
17)
18)Интервальное оценивание — один из видов статистического оценивания, предполагающий построение интервала, в котором с некоторой вероятностью находится истинное значение оцениваемого параметра.
Сущность задачи интервального оценивания параметров
Интервальный метод оценивания параметров распределения случайных величин заключается в определении интервала (а не единичного значения), в котором с заданной степенью достоверности будет заключено значение оцениваемого параметра. Интервальная оценка характеризуется двумя числами – концами интервала, внутри которого предположительно находится истинное значение параметра. Иначе говоря, вместо отдельной точки для оцениваемого параметра можно установить интервал значений, одна из точек которого является своего рода "лучшей" оценкой. Интервальные оценки являются более полными и надежными по сравнению с точечными, они применяются как для больших, так и для малых выборок. Совокупность методов определения промежутка, в котором лежит значение параметра Т, получила название методов интервального оценивания. К их числу принадлежит метод Неймана.
19)
20) Критерий Пирсона, или критерий χ² (Хи-квадрат) — наиболее часто употребляемый критерий для проверки гипотезы о законе распределения. Во многих практических задачах точный закон распределения неизвестен, то есть является гипотезой, которая требует статистической проверки.
Обозначим через X исследуемую случайную величину. Пусть требуется проверить гипотезу
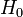
о том, что эта случайная величина подчиняется закону распределения
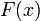
. Для проверки гипотезы произведём выборку, состоящую из n независимых наблюдений над случайной величиной X. По выборке можно построить эмпирическое распределение
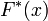
исследуемой случайной величины. Сравнение эмпирического распределения и теоретического (или, точнее было бы сказать, гипотетического - т.е. соответствующего гипотезе
) распределения
производится с помощью специального правила — критерия согласия. Одним из таких критериев и является критерий Пирсона.
Для проверки критерия вводится статистика:

Дата добавления: 2018-09-23; просмотров: 142; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!