УКАЗАТЕЛИ И ССЫЛОЧНЫЕ СТРУКТУРЫ ДАННЫХ
Указатели и адреса
До этого мы уже работали с указателями и адресами, но не вникали подробно в их суть. Теперь же пришло время.
Когда мы просто объявляем переменные, например int x= 5; то мы работаем со статической памятью. Где-то в оперативной памяти высвободилась ячейка, которую мы назвали x и которая предназначена для хранения данных типа int, т.е. целых чисел. В с++ есть возможность самому выбирать, где именно, в какой области оперативной памяти, мы хотим выделить ячейку. Это называется динамической памятью и для этого мы как раз и используем указатели и адреса.
Также при статической памяти мы не можем удалять переменные. Мы можем создать 1000 чисел типа int и они так и останутся висеть в оперативной памяти, нагружая её. Это не имеет значения, когда программа и количество переменных в ней маленькое. А если в программе нам нужно постоянно создавать новые переменные в каком-то цикличном процессе, например в игре. Тогда память быстро перегрузится и программа не сможет продолжать работу. Особенно это важно при работе с массивами. Для этого мы тоже используем динамическую память- тут мы имеем возможность удалять переменные и массивы.
Мы уже создавали динамические массивы, например: int *x= new int [n]. По сути тут мы создаём ссылку на некий объект и выделяем под него n новых ячеек типа int. Можно этот массив удалить: delete []x;
Аналогично мы можем создать так одну переменную, например int *x= new int; И так же можно эту переменную удалить: delete x; *x= NULL;
|
|
|
Чтобы присвоить ссылочной (с указателем) переменной значение, можно написать так:
int *a= new int(5); или так int *a= new int; *a= 5;
Для вывода значения нужно писать: cout << *a << endl;
Арифметические операции со ссылочными переменными тоже производятся со звёздочками и для каждой переменной делается команда new:
int *a= new int(4); int *b= new int(7); int *c= new int; *c= *a + *b; cout << *c << endl;
...
Мы можем посмотреть адрес переменной. int a= 6; cout << &a << endl; Адрес выводится в 16-ричной системе счисления и показывает, в какой по счёту ячейке находится переменная. На самом же деле число типа int занимает 4 байт, т.е. 4 ячейки подряд. Узнать это можно через sizeof(int);
Чтобы работать с этими адресами, вводятся указатели. В переменной с типом указателя мы уже можем хранить адреса и далее с этим работать. Например, сохраним адрес созданной переменной a:
int *b; b= &a; cout << b << endl;
Чтобы посмотреть чему равно значение по данному адресу, мы делаем так:
cout << *b << endl;
Мы также можем менять значение, например: *b= 10; cout << a << endl; и увидим что значение a тоже стало равно 10.
...
Поначалу может быть непонятно, зачем это всё нужно, где это можно применить. До этого мы использовали уже это неосознанно в динамических массивах, но это далеко не единственное применение. Например, мы также неосознанно делали изменение самой переменной в функции, а не её копии. Делали и возвращение массива, что значительно расширяет программистские возможности. Хотя по сути там происходит возвращение не самого массива как всех значений, а возвращение ссылки на этот массив. По этой ссылке мы уже и можем получать сами значения.
|
|
|
С помощью указателей можно также строить более эффективные для некоторых задач структуры данных такие как списки, очереди, деревья. Мы можем точечно работать с оперативной памятью, создавая переменные именно в тех ячейках, где мы хотим, меняя значения по определённым адресам и это открывает новые возможности для разработки. Со временем это всё больше будет становиться понятно.
...
Нужно помнить, что в памяти компьютера вся информация хранится в виде нулей и единиц, т.е. намагничивание либо есть, либо нет. Соответственно, все цифры и буквы переводятся в двоичный код и именно с двоичным кодом производятся операции. Для удобства также используется вспомогательная 16-ричная система, где 16 цифр и каждая кодируется 4 двоичными цифрами: 0= 0000, 1= 0001 и т.д. до F= 1111. Ну и 16-ричные цифры начинаются с 0x, это ты можешь видеть при выводе адреса какой-нибудь переменной.
|
|
|
Если 1 ячейка занимает 8 бит, т.е. 8 двоичных цифр, то как же разместить число типа int, которое занимает больше 8 бит? Оно просто делится по ячейкам. Например, число 235412. Переведём в двоичную систему с помощью калькулятора:
111001011110010100
Или разделим группами по 8 цифр, начиная справа: 11 10010111 10010100. Ячейки будут заниматься, начиная справа: в первую ячейку мы поместим 10010100, во вторую 10010111. Ну а на свободные места ставятся нули, т.е. третья ячейка будет хранить: 00000011. И четвёртая ячейка в типе int тоже должна быть занята, но т.к. число уже кончилось, то там будут чисто нули. Всё не совсем так, т.е. нужно ещё учитывать знак числа, порядок, но это такое простое объяснение на пальцах.
Можно поэкспериментировать. Создадим это число: int a= 235412. Выведем адрес и запомним: int b= &a; cout << b << endl; Имеем: 0x9ffe44. Если мы проинкрементируем адрес, то у нас прыгнет сразу на 4 ячейки, т.е. b++; cout << b << endl; покажет уже 0x9ffe48, т.к. тип int занимает 4 ячейки.
Если проделать такое с типом double, то прыгнет уже на 8 ячеек:
double a= 235412; double *b; b= &a; cout << b << endl; // 0x9ffe40
b++; cout << b << endl; // 0x9ffe48
|
|
|
Т.е. логика должна быть понятна. Можно теперь даже посмотреть что в этой новой ячейке через 8: cout << *b << endl; Вывелось 5.18044e-317, т.е. некое очень маленькое число, а по сути какая-то бессмыслица для нас. Эта информация из нулей и единиц находилась в оперативной памяти, начиная с ячейки 0x9ffe48 и в типе double она получила представление как 5.18044e-317. Это значит 5.18044 * 10^(-317)
При этом типы не смешиваются, т.е. такое не прокатит:
int a= 235412; char *c; c= &a; cout << c << endl;
Если мы делаем массив, то там все элементы лежат подряд. Это можно увидеть, создав что-нибудь и выведя адреса. Например:
int m[4]; for (int i=0; i<4; i++) cout << &m[i] << endl;
И выведется:
0x9ffe20
0x9ffe24
0x9ffe28
0x9ffe2c
Как ты можешь видеть, эти адреса отличаются на размер типа int в байтах (ячейках), т.е. на 4 (0x9ffe24 - 0x9ffe20 = 0x9ffe28 - 0x9ffe24 = 4)
Сам же адрес массива представляет из себя адрес первой ячейки. Можно вывести и посмотреть: cout << &m << endl; Получим 0x9ffe20.
...
Теперь вот щас вообще будет круто: научимся присваивать переменной нужные адреса. Например, я хочу сохранить адрес 0x9ffe21 в какую-то переменную. Для этого переведём 9ffe21 в десятичную систему через опять же встроенный калькулятор на компьютере: 10485281.
Теперь запишем:
int *a; a= (int*)10485281; cout << a << endl; // выведется наш адрес в шестнадцатеричной (hex) системе. Можно даже посмотреть, что лежит по этому адресу: cout << *a << endl; у меня вывелось 0, т.е. значит там пусто.
Можно было вывести адрес короче:
int *a= (int*)10485281; cout << a << endl;
Тут нужно помнить, что порядковый номер адреса мы должны перевести в тип со звёздочкой, иначе это воспринимается просто как число, а не адрес. Поэтому пишем: (int*)10485281. Ну и для других типов double, char и т.д. аналогично.
...
Благодаря инкрементированию адресов (или вообще благодаря арифметике с ними) мы можем перебирать значения массива, не обращаясь напрямую к самим значениям. Например:
int m[4]= {10,20,30,40}; int *a= &m[0];
cout << *a << endl; // выведет 10, т.е. первый элемент массива
a++;
cout << *a << endl; // выведет уже 20
...
Ну и напоследок стоит рассмотреть того что ещё не было- возвращение по ссылке. Т.е. функция может быть с амперсентом. Например, вернём n-й элемент массива:
int& fnc (int a[], int n) { return a[n]; }
И можно сделать далее:
int a[3]= {10,20,30}; fnc(a,1)++; cout << a[1] << endl; // выведется уже 21, т.е. мы 1-й элемент массива со значением 20 инкрементировали через функцию
Тут возвращается уже не копия, а само число. Это может быть полезно при перегрузке операции массивных скобочек для какого-нибудь класса, чтобы потом можно было производить операции с этим элементом.
Линейные связные списки
Эта тема наверное самая сложная в основах программирования, которую я встретил, поэтому я вывел её в конец. При этом ещё никто не может нормально объяснить, поэтому наверное тема кажется такой сложной. И я ещё в ахуе что часто авторы дают вообще нерабочие коды, которые либо не делают то что нужно, либо вылетают с ошибкой при запуске, либо вообще даже не компилируются. Все коды, которые тут ниже в главе размещены, я лично компилировал и проверял на работоспособность. Но тем не менее, какой бы тема ни была мутной, я должен был о ней написать, так что приступим.
Мы уже умеем хранить данные в виде массивов- это легко, быстро, компактно- но у массивов есть ряд недостатков, из-за которых и были придуманы другие способы организации данных. А недостатки в том, что при выполнения ряда действий происходят громоздкие операции для вычислительной машины, в результате чего массивы не всегда эффективны.
Например, мы хотим изменить размер массива. Для этого нам нужно выделить новую память с данным новым размером. Скопировать туда элементы. Удалить старый массив. Происходит много лишних операций. В ссылочной же организации данных мы просто можем добавить элемент к нашей структуре данных, размер тут не фиксирован. Или если мы хотим удалить средний элемент и изменить размер массива- чтобы не было пустоты посередине. Опять нужно выделение новой памяти, копирование, удаление. Это всё занимает мощности процессора. Гораздо быстрее и проще для компьютера просто поменять ссылки (указатели) на объекты, при этом не нужно лишний раз копировать огромное количество информационных блоков.
Можно продемонстрировать это более наглядно. Например, у нас есть ссылочная структура данных: 1 -> 2 -> 3 -> ... -> 1000. Мы хотим удалить информационный блок 216. Для этого мы его обнуляем, но выделять новую память и копировать ничего не нужно- мы просто поменяем указатели, т.е. 215 будет вести к 217, ну а далее уже всё друг за дружкой.
Как организовать все эти ссылочные структуры данных? Через указатели, с которыми мы уже познакомились. Ну и так же нам помогут классы.
Ключевой недостаток связных списков в том что мы не имеем прямого доступа к i-му элементу как в массиве. Но преимущество, как писалось выше, более простом добавлении и удалении.
Начнём мы с линейных связных списков- они бывают двух типов: односвязные и двусвязные. В случае двусвязных мы можем перемещать наш указатель (как бы стрелочку где мы находимся) вперёд и назад, а в случае односвязных- только вперёд или только назад.
Односвязные или двусвязные списки различают 3 типов: стопка (стек, stack), очередь и кольцо. В случае стопки мы кладём новые элементы как бы только наверх и извлекаем сверху- поэтому эта организация данных также называется LIFO (Last In First Out- последним вошёл, первым вышел). Можно сравнить со стопкой тарелок. В случае очереди мы наоборот- добавляем элементы как бы назад, а извлекаем спереди, здесь уже используется аббревиатура FIFO (First In First Out- первым вошёл, первым вышел). В случае кольца у нас нет начала или конца, это замкнутая структура- тут указатель с последнего элемента ведёт на первый, а в случае двусвязного списка также с первого на последний.
Теперь как же запрограммировать какой-нибудь из этих списков? Рассмотрим на примере стека. В с++ уже есть встроенные библиотеки и мы можем начать с них, чтобы посмотреть как это впринципе функционирует хотя бы на поверхностном уровне.
...
Для работы со стеком нужно подключить библиотеку <stack>. Далее мы можем создавать объекты типа stack, только нужно указывать тип информационного поля (int, string и т.п.) т.к. stack реализован как шаблон класса.
Я создам стек из целых чисел: stack <int> s;
Далее мы добавим в созданный стек значения. Например, в цикле от 1 до 9. Делается это так: for (int i=1; i<=9; i++) s.push(i);
Или мы просто хотим добавить число x: s.push(x);
Можно вывести верхний элемент стека: cout << "Верхний элемент: " << s.top() << endl;
Вывелось 9. Т.е. самое последнее добавленное число у нас будет на самом верху.
Теперь можно удалить верхний элемент: s.pop();
После этого верхний элемент будет уже 8. Это можно проверить, выведя s.top();
Есть также проверка- пустой ли стек: s.empty();
Например: if (s.empty()) cout << "Стек пустой" << endl;
Также есть метод peek, позволяющий обратиться к N-му элементу стека, но работает это только в версиях с++11 и выше, т.е. в devcpp не работает, а в visual studio 2012 работает (как это и было в случае с переменным именем файла). Например, если нам нужен 4-й элемент стека, можно вывести: s.peek(4);
Аналогично мы посмотрим встроенный механизм очереди. Для этого нужно подключить библиотеку <queue>
И сама очередь создаётся аналогично, например: queue <int> s; Для добавления элемента в очередь используется всё тот же метод push:
s.push(4); s.push(2); s.push(7); s.push(6);
При этом мы можем обратиться как к первому элементу, так и к последнему. Для обращения к первому элементу используем метод front, к последнему- back.
cout << "Первый: " << s.front() << endl; // выведет 4
cout << "Последний: " << s.back() << endl; // выведет 6
Для удаления всё тот же метод pop. Удалим элемент: s.pop(); теперь первым будет 2, последним 6.
Также можно проверять пуста ли очередь: if (s.empty()) cout << "Очередь пуста" << endl;
Также существуют очереди с приоритетом- это очереди, где мы расставляем элементы особым образом- новый элемент добавляется в то место, чтобы очередь была отсортирована по убыванию.
Для использования очереди с приоритетом остаётся та же библиотека <queue>, а сама очередь создаётся так: priority_queue <int> s;
Отличие в методах- тут нет front и back, можно обратиться только к первому элементу через метод top как в стеке: s.top();
Пример:
priority_queue <int> s;
s.push(4);
s.push(2);
s.push(7);
s.push(6);
cout << "Первый: " << s.top() << endl; // выведет 7, т.е. наибольший
s.pop();
cout << "Первый: " << s.top() << endl; // выведет 6, т.е. новый наибольший
...
Теперь же, если интересно, посмотрим вглубь- как можно самому создать класс стека или очереди. Ниже конструкция для стека, только мы назовём его стопкой, а узел- тарелкой.
class tarelka {
public:
int info; tarelka *next;
tarelka() {
info= 0; next= NULL;
}
};
Это создание класса для тарелки. В конструкторе значения по умолчанию.
Можно создать тарелку и вывести info (будет 0):
tarelka x; cout << x.info << endl;
Теперь класс для стопки. Он включает в себя указатель на текущую тарелку:
class stopka {
public:
tarelka *current;
stopka() {
current= new tarelka;
}
};
Пока мы просто сделали каркас. Методы пропишем ниже. В конструкторе стопки у нас выделяется адрес для нашей тарелки. Можно даже его вывести:
stopka x;
cout << x.current << endl; // выведет адрес
Если нам нужно информационное поле на этой тарелке, то мы тоже можем его вывести:
cout << x.current->info << endl;
Стрелочка используется, когда мы идём из указателя.
Теперь давай попробуем изменить значение инфополя в тарелке. Для этого мы в классе стопки пропишем функцию:
void change(int a) {
current->info= a;
}
И теперь можно использовать:
stopka x;
x.change(12);
cout << x.current->info << endl; // выведется 12
Можно вынести это значение инфополя в отдельную функцию, например:
int value() { return current->info; }
И использовать: cout << x.value() << endl;
Теперь научимся добавлять новую тарелку в стопку, т.е. нам с помощью указателей придётся перемещаться по тарелкам в стопке. В классе стопки пропишем новую функцию:
void push (int a) {
tarelka *up= new tarelka;
current->next= up;
up->info= a;
up->next= NULL;
}
Что тут происходит?
1. Создаётся новая тарелка.
2. Текущая тарелка связывается с этой новой.
3. Присваивается значение инфополю новой тарелки.
4. Новая тарелка пока ни с чем не связана, т.е. присваиваем NULL
Ну и также напишем функцию, которая будет перемещать нас наверх- к новой тарелке:
void goUP () { current= current->next; }
т.е. теперь текущая тарелка у нас будет следующей, т.е. которая выше.
И далее мы можем использовать:
stopka x; // создали стопку (она пока состоит из 1 тарелки и инфополя 0)
x.change(12); // присвоили инфополю 1-й тарелки значение 12
cout << x.value() << endl; // вывели это значение
x.push(3); // положили наверх новую тарелку с инфополем 3
x.goUP(); // переместились наверх
cout << x.value() << endl; // вывели инфополе новой верхней тарелки
Теперь сделаем круче: в цикле создадим 10 тарелок и внесём значения квадратов: 1, 4, 9 и т.д. и параллельно будем выводить:
stopka x;
x.change(1);
cout << x.value() << " ";
for (int i=2; i<=10; i++) {
x.push(i*i);
x.goUP();
cout << x.value() << " ";
}
У нас есть маленькое неудобство: первый элемент пришлось отдельно прописать. Можно сделать в конструкторе стопки, чтобы сразу его указывать:
stopka(int a) {
current= new tarelka;
current->info= a;
}
Ну а наш код выше теперь мы запишем короче и чётче:
stopka x(1);
for (int i=2; i<=11; i++) {
cout << x.value() << " ";
if(i==11) break;
x.push(i*i);
x.goUP();
}
Можно оставить 2 конструктора для стопки:
stopka(int a) {
current= new tarelka;
current->info= a;
}
stopka() {
current= new tarelka;
}
Это будет обычная перегрузка функции. Тогда мы сможем объявлять стопку 2 способами:
1. stopka x; // по умолчанию инфополе сделается равным 0
2. stopka x(5); // по умолчанию 5
Теперь научимся находить самый верхний элемент стопки, напишем для этого отдельную функцию. Чтобы попасть на самый верх, мы просто будем идти наверх по ступенькам, для этого уже есть функция goUP(); В классе стопки пишем:
int top() {
while (current->next!=NULL) goUP();
return current->info;
}
К слову, мы уже и так перемещаемся наверх при добавлении нового элемента. Но если мы оказались вначале вдруг, то всё равно можем легко подняться наверх.
Можно сделать функцию, которая одновременно добавляет новую тарелку и перемещает указатель на неё:
void add (int a) {
push(a); goUP();
}
Ниже демонстрация работы функции top и как мы можем сохранить нижний указатель:
stopka x;
tarelka *t= x.current;
for (int i=1; i<=10; i++) x.add(i*i);
x.current= t;
cout << x.top() << endl;
Теперь осталось только научиться удалять верхний элемент. Для начала мы должны переместиться туда, а далее уже можно удалять. В классе стопки напишем новую функцию:
void pop() {
while (current->next->next!=NULL) goUP();
current->next= NULL;
delete current->next;
}
Демонстрация применения:
stopka x;
tarelka *t= x.current;
for (int i=1; i<=10; i++) x.add(i*i);
x.current= t;
cout << x.top() << endl; // 100
x.current= t; // опять на первый
x.pop(); // удаляем последний
x.current= t; // опять вниз
cout << x.top() << endl; // 81
Важный нюанс- прежде чем использовать удаление, нам нужно переместиться в самый низ, т.к. если мы находимся на верхней тарелке, то проверяем через одну while (current->next->next!=NULL). Также это неприменимо если у нас 1 тарелка во всей стопке. В таком случае нужно писать отдельную функцию. Для всех этих целей нам нужно чтобы в классе стопки также хранился указатель на первую тарелку. Можно его сохранять при создании стека и помещать в область private. Так и сделаем, дополним наш класс. Теперь он будет выглядеть так:
class stopka {
tarelka *first; // самая нижняя тарелка (находится по умолчанию в закрытой области класса)
public:
tarelka *current; // указатель на текущую тарелку
// конструкторы стопок (значения по умолчанию + сохранение самой нижней тарелки)
stopka(int a) {
current= new tarelka;
current->info= a;
first= current;
}
stopka() {
current= new tarelka;
first= current;
}
// поменять значение у текущего элемента
void change(int a) {
current->info= a;
}
// инфоблок текущего элемента
int value() {
return current->info;
}
// переместить указатель на 1 тарелку вверх
void goUP () {
current= current->next;
}
// добавить новую тарелку и переместиться наверх
void push (int a) {
tarelka *up= new tarelka;
current->next= up;
up->info= a;
up->next= NULL;
goUP();
}
// инфоблок верхнего элемента
int top() {
while (current->next!=NULL) goUP();
return current->info;
}
// удаление верхнего элемента
void pop() {
current= first;
if(first->next!=NULL) {
while (current->next->next!=NULL) goUP();
current->next= NULL;
delete current->next;
}
}
// функция удаления стопки
void del() {
current= first;
while(first->next!=NULL) pop();
current= first= NULL;
delete current; delete first;
cout << "Стопка удалена" << endl;
}
};
Ну вот и всё. Как видишь, это не так сложно, есть по частям шаг за шагом аккуратно в этом разобраться. Можно аналогично написать класс для двусвязного списка (чтобы мы могли ещё и назад перемещаться), для очереди и т.д. и т.п. либо дополнить текущий класс стопки новыми функциями, расширить функционал. Здесь я показал лишь самые основы, которых достаточно для общего понимания темы.
Деревья
Ссылочные данные могут быть организованы не только линейно, но и разветвлённо. И особо важное значение тут имеет такой способ организации данных как дерево.
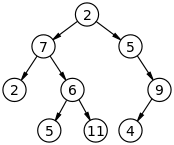
Я вставил рисунок, чтобы сразу было всё понятно. Самый верхний элемент называется корнем. Все элементы называются узлами. Последние элементы (в данном случае 2, 5, 11, 4) называются листьями. Для узла элементы ниже называются сыновьями. Например, у корня 2 сына- левый (7) и правый (5). У элемента 5 справа только 1 сын (9). У листьев сыновей нету. В обратную сторону- можно считать узлы выше родительскими. Например, для узла 11 родительским будет 6. Также есть термин "потомки"- это все элементы ниже. Например, для узла 7 будут потомки 2, 6, 5, 11.
Выше нарисовано бинарное (двоичное) дерево- тут каждый узел имеет не более 2 сыновей. В общем случае сыновей может быть сколько угодно.
...
Посмотрим как реализовать дерево на программном уровне. Рассмотрим двоичное дерево, оно используется чаще чем остальные. Мы будем использовать 2 класса: класс узла и класс собственно дерева.
Класс узла выглядит так:
class node {
public:
int info; node *left,*right,*parent;
node() { info=0; parent=NULL; right=NULL; left=NULL; }
};
В классе узла (по-английски node) у нас хранится 4 параметра: само информационное поле (int info) и 3 указателя- на левого сына, правого сына и на родительский узел.
Далее идёт конструктор класса, который присваивает значения по умолчанию. NULL это значит ничего, т.е. пусто.
Теперь класс самого дерева- он у нас будет состоять из указателя на текущий узел и различных функций (методов)- типа перейти в одну сторону, другую и прочее.
class tree {
public:
node *current; // указатель на текущий узел
tree() { current = new node; } // конструктор
// создать левый узел
void createL(int num) {
node *p = new node;
current->left = p;
p->info=num;
p->parent = current;
}
// создать правый узел
void createR(int num) {
node *p = new node;
current->right = p;
p->info=num;
p->parent = current;
}
// переместиться на левого сына
void goL() { current = current->left; }
// переместиться на правого сына
void goR() { current = current->right; }
// переместиться на родительский узел
void goUP() { current = current->parent; }
// присвоить информационному полю значение
void change(int a) { current->info = a; }
// вывести значение информационного поля
void get() { cout<< current->info << endl; }
// нарисовать дерево (начиная с корня)
void print(node *root,unsigned k=0) {
if (root != NULL) {
print(root->left, k + 3);
for(unsigned i = 0; i < k; i++) cout<<" ";
cout<< root->info << endl;
print(root->right, k + 3);
}
}
// удалить дерево
void del() {
if (current->parent->left==current) {current->parent->left=NULL;}
if (current->parent->right==current) {current->parent->right=NULL;}
delete current;
}
};
И далее мы можем это использовать в программе, например:
tree t; // создаём пустое дерево
node *root = t.current; // запоминаем корень
// заполняем дерево значениями
t.change(3);
t.createL(8);
t.goL();
t.createL(1);
t.createR(0);
t.goUP();
t.createR(5);
t.goR();
t.createL(4);
// выводим получившееся дерево
t.print(root);
Есть много различных вариаций деревьев, например двоичное дерево поиска, всякие способы балансировки деревьев и прочее, что можно про все эти структуры данных и методы работы с ними целую книгу писать, но мы это тут рассматривать не будем по ненадобности. Здесь мы на простом и поверхностном уровне рассмотрели, что представляет из себя двоичное дерево на программном уровне, на этом будет достаточно.
________________________________________________
РАЗДЕЛ 4
РАБОТА С ГРАФИКОЙ ЧЕРЕЗ БИБЛИОТЕКИ SFML и OpenGL
Установка SFML
SFML или Simple and Fast Multimedia Library- простая и быстрая мультимедийная библиотека. Это высокоуровневая библиотека, по которой мы можем научиться делать графические вещи на с++ без лишних усложнений в плане кода, чтобы сконцентрироваться больше на алгоритмах обработки изображений и т.п. Позже посмотрим более низкоуровневую, но и универсальную библиотеку- OpenGL.
SFML полностью бесплатна и скачать её можно на официальном сайте sfml-dev.org. Либо у меня с яндекс диска, где я собрал также все необходимые dll файлы для работы программ:
https://yadi.sk/d/nrm4h6O13KZV5j
Мы скачиваем архив, разархивируем и помещаем всю папку на диск С для удобства.
Инструкция для devcpp:
1. Создаём проект windows forms и всё стираем.
2. Заходим в параметры проекта
3. Вкладка "Параметры", колонка "Linker". Прописываем туда:
-lsfml-audio
-lsfml-graphics
-lsfml-system
-lsfml-window
4. Вкладка "файлы/каталоги", колонка "библиотек". Добавляем ссылку на папку lib: C:\SFML-2.4.2\lib
Аналогично "файлов включения" и C:\SFML-2.4.2\include
5. Подтвердить
6. Вставить тестовый код, скомпилировать, проверить
7. Добавить dll файлы из папки bin в папку с проектом. Также м.б. понадобится установить дополнительные dll файлы на компьютер.
Также все эти dll файлы мы перемещаем в папки system32 (для 32-битных файлов) и sysWOW64 (для 64-битных файлов)
Тестовый код:
#include <SFML/Graphics.hpp>
int main()
{
sf::RenderWindow window(sf::VideoMode(200, 200), "SFML works!");
sf::CircleShape shape(100.f);
shape.setFillColor(sf::Color::Green);
while (window.isOpen())
{
sf::Event event;
while (window.pollEvent(event))
{
if (event.type == sf::Event::Closed)
window.close();
}
window.clear();
window.draw(shape);
window.display();
}
return 0;
}
Должно запуститься окошечко и вывестись зелёный кружочек. Если потребует какие-то dll файлы, то докачать и установить в system32 и sysWOW64. Версия SFML может отличаться, т.к. периодически выходят новые, но это не принципиально- установка одинаковая для всех версий, просто имя папки вместо SFML-2.4.2 будет другое и соответственно с этим при установке тоже прописывать эти другие имена папки.
...
Для Visual Studio инструкция такая:
Создаём пустой проект как обычно, далее переходим в project -> properties. Туда же, куда заходили чтобы сделать программу рабочей на чужих компьютерах. Это параметры проекта. Далее:
1. Наверху где Configuration выбираем All Configurations. Слева Configuration Properties -> VC++ directories -> include directories -> edit -> добавить папку C:\SFML-2.4.2\include и там же library directories -> аналогично добавляем папку C:\SFML-2.4.2\lib и сохраняем изменения.
2. Configuration выбираем Release. Далее Linker -> input -> additional dependencies -> записать:
sfml-graphics.lib
sfml-window.lib
sfml-system.lib
sfml-audio.lib
Аналогично Configuration выбираем Debug. Linker -> input -> additional dependencies -> прописываем:
sfml-graphics-d.lib
sfml-window-d.lib
sfml-system-d.lib
sfml-audio-d.lib
Подтвердить, сохранить.
3. Все dll файлы из папки bin в SFML перенести в папку с проектом.
4. Создать cpp файл, вставить тестовый код, запустить и проверить. Если требует какие-то dll файлы, докачать их с интернета и установить как писал выше. Можно эти недостающие dll файлы не только в system32 перемещать, но и в папку с проектом- если вдруг не работает.
Эти инструкции сработали у меня, также выше я оставил ссылку на папку, где ты можешь всё скачать: SFML, dll файлы которые требовались у меня, инструкции. И как только у тебя всё заработало, можно приступать к дальнейшему обучению.
Для начала обратимся к этому куску кода:
sf::RenderWindow window(sf::VideoMode(200, 200), "SFML works!");
sf::CircleShape shape(100.f);
shape.setFillColor(sf::Color::Green);
Здесь ты можешь поменять размер начального окна (VideoMode), заголовок окна (следующий аргумент), радиус круга (вместо 100 написать другой) и цвет этого круга (третья строчка)- поэкспериментируй с этим. И после этого мы идём дальше- создавать нашу первую игру.
________________________________________________
РАЗДЕЛ 7
Дата добавления: 2018-09-22; просмотров: 398; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!