Стисле та індексне зберігання лінійних списків.
Лабораторна робота №10
Тема роботи: Розробка алгоритмів задач з використанням складних структур.
Мета роботи: Одержати навички роботи з структурами списки, стеки, черги для розв’язання задач.
Рекомендована література:
1. В. С. Проценко, П. Й. Чаленко, А. Б. Ставровський Техніка програмування мовою Ci. Київ, Либідь, 1993. ст. 48 - 69.
2. В.Н. Пильщиков Сборник упражнений по языку Паскаль. М., Наука, 1989, ст.96-119.
3. Сборник задач по информатике с решениями., Преподаватель Егорова, Кривой рог, 1997
Контрольні запитання:
1. Яка структура має назву списки?
2. Яким чином у мові С описується список?
3. Що таке стек?
4. Що таке черга?
5. Чим відрізняється черга від стека та списку?
Теоретичні відомості:
Покажчики.
Імена даних вказують адреси байтів пам’яті ЕОМ, де розташовані дані. З кожним типом даних Т пов’язується множина адрес, за якими можуть розташовуватися ці данні. Така множина адрес є носієм типу “покажчик на Т”. Змінні цього типу називаються покажчиками, а їхніми значеннями є адреси об’єктів типу Т.
В мові С описи таких замінних будуються за допомогою операції * (“значення за адресою”). Наприклад:
char *pc, *ppc; - змінні pc та ppc є покажчиками на char.
Адреси значень типу Т задаються виразами “покажчик на Т”. Найпростішим виразом такого типу є & v, де & - знак операції “взяття адреси”, v - ім’я змінної або вираз, що задає елемент масиву, член структури або об’єднання. Наприклад:
|
|
|
char ch, *oc;
pc= &ch; - вираз та покажчик pc мають значення адресу змінної ch.
За допомогою покажчиків відбувається доступ та зміна значень даних без вживання їхніх імен. Якщо pe позначає довільний вираз типу “покажчик типу Т”, то вираз * pe має значення типу Т, яке розташоване за адресою, визначеною значенням pe. Якщо x, y - змінні, px, py - відповідно покажчики на них, то вирази x = y, *px = y, x = *py, *px = *py еквівалентні.
Операції * та & обернені, тобто вирази *(&p) і p, &(*p), i p еквівалентні.
Для покажчиків дозволені наступні операції.
Нехай pe та pv позначають відповідно довільний вираз і змінну типу “покажчик на Т”, ie - цілий вираз. Вираз pe + ie має значення val(pe) + val(ie) sizeof(T) типу pe, тобто значення покажчика збільшується на ціле число розмірів даних типу Т. Аналогічно, вирази pe - ie val(pe)-val(ie) sizeof(T). Вирази pv++, ++pv (pv--, --pv) збільшують (зменшують) значення pv на sizeof(T). Аналогічно pv+ = ie та pv- = ie збільшують або зменшують pv на val(ie) sizeof(T). Вираз pe1- pe2 означае ціле число об’єктів типу Т, які можна розмістити в пам’яті, починаючи з адреси val(pe1) val(pe2), тобто val(pe1- pe2)= (val(pe1)- val(pe2))/ sizeof(T).
Вирази відношення на покажчиками мають вигляд
pe1 S pe2,
де S- один з знаків операцій ==, !=, <, <=, >, >=/.
|
|
|
Ці операції аналогічні операціям відношення з арифметичними операндами. Вираз pe[ie] еквівалентний виразу *(pe + ie) і має значення типу Т. Якщо pe містить знаки операції, то слід писати (pe) [ie], тому що операція [] має найвищій пріоритет.
Вживання інших операцій над покажчиками неприпустиме. Значення покажчиків на один тип можна перетворити в значення покажчиків на інший тип. Але такі перетворення не завжди безпомилкові, тому що адреси об’єктів, які займають 2 чи більше байтів, можуть бути тільки парними. Деякі реалізації допускають використання цілих значень як адрес, і навпаки, тобто можливі вирази вигляду pv = ie, ’iv = pe. Приклад:
Для визначеного опису
float *px, *pz;
double *py, y;
a) вираз px++ p, збільшує val(px) на 4;
b) вираз py--=2 зменшує val(px) на 16;
c) після обчислення виразу pz=*(&px) +1; val(pz) -val(px) = 4;
d) якщо val(pz) =val(px) + 4, то після обчислення виразу px=(pz=px) +1; val(px) =val(pz) + 4.
Лінійні списки.
Лінійний список - це скінченна послідовність однотипних елементів (вузлўв), можливо, з
повтореннями. Кількість елементів у послідовності називається довжиною списку. Вона в процесі роботи програми може змінюватися.
При роботі з списками часто доводиться виконувати такі операції:
· знайти елемент із заданною властивістю;
|
|
|
· визначити i-й елемент у лінійному списку;
· внести додатковий елемент до або після вказанного вузла;
· вилучити певний елемент зі списку;
· упорядкувати вузли лінійного списку в певному порядку.
У реальних мовах програмування не існуї якої-небудь структури даних для зображення лінійного списку так, щоб усі операції над ним виконувались в однаковій мірі ефективно. Тому при роботі з лінійними списками важливе значення маї подання лінійних списків, які використовуються в програмі, таким чином, щоб була забезпечена максимальна ефективність і за часом виконання програми, і за обсягом потрібної їй пам'яті.
Основні методи зберігання лінійних списків поділяють на методи послідовного і зв'заного зберігання. При виборі способу зберігання в конкретній програмі слід ураховувати, які операції і з якою частотою будуть виконуватися над лінійними списками, вартість їх виконання та обсяг потрібної пам'ті для зберігання списку.
Зв'язане зберігання лінійних списків. Тут рекурсивні структури даних зв'язуються одним з полів у ланцюг, початок якого вказується покажчиком списку. При простому зв'язанному зберіганні списку цўлих чисел кожний елемент ї структурою типу LISTN, складеною з поля
|
|
|
val для значення елемента списку та поля next для покажчика на наступний елемент списку. Опис
typedef struct node
{ int val;
struct node * next;} LISTN, *LISTP;
визначаї структуру одного елемента списку типу LISTN і покажчика на нього типу LISTP. У роботі зі списками в зв'язанному зберіганні використовується функція new(v, pn), яка виділяє вільну ділянку пам'яті для зберігання вузла списку, встановлює val i next в v та pn і повертає покажчик на сформований вузел:
/*new-формування вузла списку*/
LISTP new(v,pn)
int v;
LIST pn;
{ char * calloc();
LISTP p;
if (p=(LISTP) calloc (1,sizeof (LISTN)))
{p->next=pn;p->val=v;
return p;}
else error ("переповнення");
}
Функцўя lform створюї зв'язний список F=<d1,d2,d3>з трьох елементів і повертаї покажчик на перший елемент:
LISTP lform(d1,d2,d3)
int d1,d2,d3;
{ LISTP new (), p;
p=new(d3, NULL); p = new(d2, p);
return new(d1, p);
}
Функція lprnd друкує значення і-го вузла, а функція lprbnd друкує обох сусідів вузла, на який показує p (d1-покажчик першого елемента лінійного списку, що зберігається зв'язано):
/*lprnd- друкування значення ў-го вузла*/
lprnd(d1,i)
LISTP d1;
int i;
{ int j;
for (j=1;j<i&&d1;j++)
d1=d1->next;
if (!d1) error (“немає вузла”);
printf("%_=_%d\n",i,d1->val);
}
/*lprbnd - друкування сусідів вузла, на який показує p*/
lprbnd(d1,p)
LISTP d1,p;
{if (!p!!d1==p!!!p->next)
error (“немає сусіда”);
while(d1&&d1->next!=p)
d1=d1->next;
if (!d1) error (“немає сусіда”);
printf("%d_%d\n",d1->val,(p->next)->val);
}
Зв'язане зберігання лінійного списку дозволяє ефективно вилучати чи додавати новий вузол із значенням dv за елементом, визначеним покажчиком h!=NULL. Функції ldelet i linst
реалізують відповідно ці операції:
/*ldelet- вилучення вузла за вузлом *p */
ldelet(p)
LISTP p;
{ LISTP r;
if (!(r=p->next))
error ("немаї вузла");
p->next=r->next;free(r);
}
/*linst-додавання вузла зІ значенням dv за вузлом *p*/
linst(dv,p)
int dv;
LISTP p;
{ LISTP new ();
p->next=new(dv,p->next);
}
Функція lptar частково упорядковує непорожній список d1 зі значеннями k1,k2,...,kn, перетворюючи його в список вузлів <k'1,k'2,...,k's, k1, k''1, k''2, ..., k''i>, s+t+1=l так, що k'i<k1 для 1<=i<=...<=s, k''j>=k1 для 1<=j<=t; вона повертає покажчик на частково упорядкований список:
/*lptar- часткове упорядкування зв'язанного списку*/
LISTP lptar(d1)
LISTP d1;
{int aux;LISTP p,r;
aux=d1->val;p=d1;
while(r=p->next)
if(r->val<aux)
{p->next=r->next;
r->next=d1;d1=r;
}
else p=r;
return d1;
}
Кількість дій,потрібних для виконання вказанних операцій над списком у зв'язанному зберіганні, оцінюється співвідношеннями: для функцій lprnd, lprbnd- O(l); для функцўй ldelet, linst-O(1);для функцій lptar-O(l).
Зв'язане зберігання лінійного списку називається списком з двома зв'язками, якщо кожний вузол (структура) маї два поля для зберігання покажчиків-посилань на попередній та наступний елементи лінійного списку.
Зв'язане зберігання лінійного списку називається циклічним списком, якщо його останній елемент показує на перший елемент, а покажчик списку p- останній елемент.
При розв'язанні конкретних задач можуть вникати й інші різновиди зв'язанного зберігання.
Приклад.
На вході задана послідовність цілих чисел b1, b2,...,bn з інтервалу 1-999. Список Fi, 1<=i<=n утворений упорядкуванням послідовності b1, b2,..., bi за зростанням. Скласти функцію для введення заданої послідовності, формування Fn у зв'язаному зберіганні і повернення покажчика на його початок.
Для розв'язання задачі будемо будувати упорядковані списки Fi+1, вводячи елемент bi+1 у певне місце списку Fi. Якщо список реалізований звичайним зв'язаним зберіганням, можливі три варіанти: коли в списку елементів немає, коли новий елемент додається на початку або в кінці списку. Програма маї вигляд:
/*arrange - створення упорядкованого зв'язаного списку */
LISTP arrange ()
{ int in;
LISTP r, p, new ();
r=new (0, new (1000, NULL));
while (scanf ("% d", &in)==1)
{
for (p=r; (p->next)->val<in; p=p->next);
p->next=new (in, p->next);
}
return r;
}
СТЕКИ і ЧЕРГИ
Стек - це лінійний список, де операції додавання і вилучення елемента та доступу до елемента виконуються тільки в його кінці.
Черга -це лінійний список, в якому елементи вилучаються з початку списку, а додаються в його кінці.
Двостороння черга - це лінійний список, в якому операції можна виконувати і на початку, і в кінці.
У роботі частіше зустрічаються стеки. Наведемо приклад застосування стеків при обчисленні виразів. Однією з форм подавання виразів є бездужковий польський інверсний запис, в якому порядок виконання операції визначається її контекстом та позицією у виразі. Вираз задається так, що операції в ньому записуються в порядку їх виконання, а операнди містяться безпосередньо перед операцією; елементи запису розділяються пропуском чи комою. Наприклад, вираз (5+7)*3-4*2 в польському інверсному записі маї вигляд 5, 7, +, 3, *, 4, 2, *, -. Особливість польського інверсного запису полягає в тому, що значення виразу можна обчислити за один його перегляд зліва направо, використовуючи стек (стек спочатку повинен бути порожнім). Якщо при перегляді виразу з'являються дані, то вони заносяться в стек, а якщо з'явиться операція, то вона виконується над верхніми елементами стека з заміною їх результатом обчислення. Ілюстрація динаміки зміни стека для виразу 5, 7, +, 3, *, 4, 2, *, - маї вигляд: st=<>--<5>--<5, 7>--<12>--<12, 3>--<36>--<36, 4>--<36, 4 ,2>--<36, 8>--<28>.
Функція seval () обчислює значення виразу, заданого в масиві a[n] у польському інверсному записі, причому a[i]>=0 означаї невід'їмне ціле число, a[i]<0-операцію. Для кодування операцій додавання, віднімання, множення і ділення вибрані відповідно від'їмні числа -1, -2, -3, -4. Для організації послідовного зберегання стека використовується масив цілих st[100] і ціла змінна t, що фіксує останній елемент стека У функції seval не реалізована перевірка стека на порожність, переповнення (t=-1, t=100) та на правильність вхідної інформації. Текст цієї функції є таким:
/*seval-обчислення виразу в польському інверсному записі*/
seval (a,n)
int a[], n;
{ int st [100], p, t, c;
t=-1;
for (p=0; p<n; p++)
if (a[p]<0)
{ c=st[t- -];
swich (a[p])
{
case -1: st[t]+ =c; break;
case -2: st[t]- =c; break;
case -3: st[t]* =c; break;
case -4: st[t]/ =c; break; }
}
else st[++t]=a[p];
return st[t];
}
Послідовне зберігання стеків і черг. Припустемо, що для розміщення потрібних в задачі стеків та черг цілих чисел є послідовна ділянка пам'яті - масив d з M елементами, задана описом:
# define M 100
int d[M];
Реалізація одного стека здіснюється так: перший елемент стека розміщюється на початку області d, а індекс його останнього елемента відмічається значенням змінної a, яке спочатку дорівнюї -1, що означає порожнўй стек, тобто має бути опис int a=-1;. Додавання елемента в стек виконується оператором d[++a]=v; вилучення зі стека - оператором v=d[a--]. Для реалізації двох стеків можна поділити область d на дві ділянки розмірів M1 та M2 (M1+M2=M) і в кожній з них розміщати окремий стек. Але це недоцільно, оскільки в одному зі стеків може настати переповнення, а в другому - пам'ять буде вільна. Тому доцільніше перший стек розміщувати з початку області d, фіксуючи його вершину значенням змінної a, а другий стек-з кінця області d, фіксуючи його вершину в змінній b, тобто мати оголошення int a=-1, b=M; і стеки рухати назустріч один одному. Операції вилучення та додавання елементів в стеки тепер здіснюються так: вилучення елемента з першого стека - v=d[a--]; з другого стека - v=d[b++]; додавання елемента в перший стек - d[++a]=new; в другий - d[--b]=new. Переповнення області d настає за виконанням умови a=b-1.
Якщо в області d повинно бути більше двох стеків, то організація їх керування неможлива без перерозподілу пам'яті, тобто не уникнути ситуації, коли в одному зі стеків настає переповнення за наявності в d вільних ділянок. При перерозподілі пам'яті між стеками доводиться більшість стеків переміщати (як правило, до 10% залишиної вільної пам'яті ділити рівномірно між всіма стеками, решту - пропорційно збільшенню стека за час від останнього перерозподілу).
При реалізації черги в масиві d її перший елемент розміщується на початку d. Для фіксації значень індексів початку та кінця черги використовуються цілі змінні a і b з початковими значеннями a=0; b=-1, тобто потрібний опис int a=0, b=-1;. Вилучення елемента з непустої черги здійснюється оператором v=d[a++]; додавання елемента в чергу -оператором d[++b]=v; черга стає порожньою, коли a>b, тобто a=b+1. Досягнення кінця області d, коли b=M-1, вимагає перерозподілу пам'яті, тобто зміщення черги до лівогокраю області d. Якщо черга стає порожньою, то для зменшення таких перерозподілів часто беруть a=0; b=1. Можна уникнути перерозподілів, організуючи в області d чергу як циклічну структуру, в якій слідом за останнім елементом області йде її перший елемент (...d[M-1], D[0], D[1], ...). За використання циклічної структури рівність a=b+1 буде вірна для порожньої черги або для заповненої. Щоб розрізняти ці черги, необхідно додатково мати інформацію про кількість елементів у них.
Організація в d двох або більше черг неможлива без переміщень і перерозподілів пам'яті. Реалізація двосторонніх черг з послідовним зберіганням аналогічна реалізації звичайних черг.
Зв'язане зберігання стеків та черг. Проблеми переміщення і перерозподілу пам'яті, коли стеків n>=3 або черг n>=2, зникають при зв'язаному зберіганні. Стеки реалізуються аналогічно лінійним спискам з покажчиком на кінець списку і зв'язком від наступного елемента до попереднього. Описом стека та його ініціацією є: LISTP dl=NULL;.
Функцўя pop вилучення елемента зі стека і функція add додавання нового елемента в стек з формальним параметром типу LISTP* змінюють значення покажчика на останній елемент стека. Крім того, функція pop повертає значення вилученого елемента стека. Текст цих функцій записується у вигляді:
/*pop-вилучення елемента зі стека *dl*/
pop (dl)
LISTP *dl;
{
int v; LISTP q;
if (q=*dl)
{ v=q->val; *dl=q->next; free (q);
return v;
}
else error ("немаї елемента");
}
/*add-додаванняв стек *dl елемента v*/
add (dl,v)
LISTP *dl; int v;
{ LISTP new ();
*dl=new (v,dl);
}
Черги релізуються аналогічно лінійним спискам, але з двома покажчиками LISTP dl, e; на перший та останній елементи. Поро жня черга реалўзуїться оператором dl=e=NULL. Функцўя addq додавання нового елемента в чергу і функція popq вилучення елемента з черги з двома формальними параметрами типу LISTP* мають вигляд:
/*addq-додавання в чергу елемента v*/
addq (dl, e, v)
LISTP *dl, *e; int v;
{
LISTP q, new ();
q=new (v, NULL);
if (*dl) (*e)->next=q;
else (*dl)=q;
*e=q;
}
/*popq-вилучення елементўв з черги */
popq (dl, e)
LISTP *dl, *e;
{
int v; LISTP q;
if (!(q=*dl)) error ("немаї елемента");
if (q==*e)
*dl=*e=NULL;
else (*dl)=q->next;
v=q->val; free (q);
return v;
}
Операції з чергою можна спростити, якщо додати до не “голову”-вузол з інформацією, що не використовується Тоді порожня черга формується оператором dl=e=new (0, NULL), а функції addqh і popqh реалізують операції додавання елемента в чергу та вилучення елемента з неї:
/*addqh - додавання елемента в чергу з “головою” */
addqh (dl, e, v);
LISTP *dl, *e;
int v;
{
LISTP new (), q;
q= new (v, NULL);
(*e)-> next;
}
/* popqh - вилучення елемента з черги з “головою” */
popqh (dl, e, v);
LISTP *dl, *e;
{
LISTP q;
if (*dl == *e) error (“немає елемента”);
q = *dl;
*dl = q->next;
free (q);
return (*dl)->val;
}
Чергу можна утворити, використовуючи циклічний список; тоді досить одного покажчика dl.
Двостороння черга реалізується аналогічно звичайній. У ній легко додавати елементи з обох кінців та вилучати елементи з початку, але важко вилучати елемента з кінця.
Стисле та індексне зберігання лінійних списків.
Нехай у списку B=<k1, k2, ..., kn> кілька елементів мають однакове значення v; список 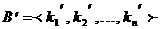 будується з В заміною кожного елемента ki парою k1’ =(i, ki), а список
будується з В заміною кожного елемента ki парою k1’ =(i, ki), а список 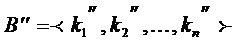 з В’ викресл.юванням усіх пар k1’ =(i, v). Стислим зберіганням В є будь - який метод Зберігання В’’, в якому не записуються елементи з значенням v. Цінність стислого зберігання списку при значній кількості елементів, рівних v, полягаї в можливості зменшення пам'яті для його зберігання.
з В’ викресл.юванням усіх пар k1’ =(i, v). Стислим зберіганням В є будь - який метод Зберігання В’’, в якому не записуються елементи з значенням v. Цінність стислого зберігання списку при значній кількості елементів, рівних v, полягаї в можливості зменшення пам'яті для його зберігання.
Пошук і-того елементу списку при зв'язаному стислому зберіганні здійснюється методом повного перегляду, а при послідовному стислому зберіганні - методом бінарного пошуку. Переваги та недоліки послідовного і зв'язаного стислих зберігань аналогічні перевагам та недолікам послідовного і зв'язаного зберігань.
Приклад. На вході (файл stdin) задані дві послідовності цілих чисел
М={m1,m2,...,m10000},
N={n1,n2,...,n10000}.
Відомо, що не менше 92% елементів послідовності М рівно нулю. Скласти програму для обчислення скалярного добутку векторўв М і N
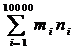
Організуємо для списку М послідовне стисле зберігання в масиві структур М. Програмою розв'язання задачў буде:
/*scalprod-скалярний добуток векторўв*/
main ()
{
int i,inp,sum;
struct {int nm, val;}M[800],*p;
p=M;
for (i=0;i<10000;i++)
{
scanf("%d",&inp);
if (p->val=inp) (p++)->nm=i;
}
p->nm=10000; sum=0; p=M;
for (i=0;i<10000;i++)
{
scanf("%d",&inp);
if(i==p->nm)sum+=(p++)->val*inp;
}
printf("sum=%d\n",sum);
}
Індексне зберігання. Спосіб індексного зберігання інформації полягає в тім, що початковий список В=(к1,к2,...кn) ділиться на кількість підсписків В1,В2,...Вm так, що кожний елемент списку В
потрапляє тільки в один з підсписків; додатково використовується індексний список з m елементами, що показують на початки списків В1,В2,...,Вm .Таке зберігання списку називається індексним з підсписками В1,В2,...,Вm та індексним списком Х=<adg1, adg2,...,adgm>, де adgj - адреса початку підсписку Вj,1<=j<=m. За індексного зберігання елемента к, що належить підсписку Вi, має індекс і.
Для індексного зберігання початковий список В часто перетворюють у список В', вміщуючи в кожен вузол його порядковий номер в В. Вj-й елемент індексного списку Х, крім adgі, може вводитися додаткова інформація про підсписок Вj. Поділ списку В на підсписки здійснюється так, щоб усі його елементи з певною властивістю pj потрапили в один підсписок Вj. Цінність індексного зберігання в тому, що для пошуку елемента к із заданою властивістю рj досить переглянути тільки елементи підсписку Вj; його почоток перебуває в індексному списку Х, оскільки для будь-якого к є Ві при і<>j властивість рj не виконуїться.
Для поділу списку В використовується індексна функція g(k),яка виробляє за елементом к його індекс, тобто g(k)=j. Функція g звичайно залежить від позиції к в В або від значення певного його компонента - ключа елемента к.
Приклад. Розглянемо список В=<к1,к2,...,к9> з елементами к1=(17,У), к2=(23,Н), к3=(60,І), к4=(90,S), к5=(166,Т), к6=(177,Т), к7=(250,U), k8=(288,W), k9=(300,S).
Якщо для поділу цього списку на підсписки візьмемо індксну функцію ga(k)==1+(поз.к-1)/3, де поз. к - порядковий номер елемента к в початковому списку В, то список розділиться на підсписки:
B1=[(17,Y), (23,H), (60,I)]
B2=[(90,S), (166,T), (177,T)]
B3=[(250,U), (288,W), (300,S)]
Додаючи кожен вузол ще порядковий номер (поз.) елемента в початковому списку, дістанемо:
B'1=[(1,17,Y), (2,23,H), (3,60,I)],
B'2=[(4,90,S), (5,166,T), (6,177,T)],
B'3=[(7,250,U), (8,288,W), (9,300,S)].
За індексною функцією gb(k)=1+(поз.k-1)% 3 буде:
B"1=[(1,17,Y), (4,90,S), (7,250,U)],
B"2=[(2,23,H), (5,166,T), (8,288,W)],
B"3=[(3,60,I), (6,177,T), (9,300,S)].
Тепер для визначення, наприклад, вузла к6 достатньо пернглянути тільки один список: В'2 для першого поділу, бо ga(6)=2, або В'3 для другого подўлу, бо gb(6)=3. Якщо за функцію поділу взяти gс(к)=1+ 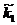 /100, де -перший компонент (ключ.) елемента к. то
/100, де -перший компонент (ключ.) елемента к. то
B1=[(17,Y), (23,H), (60,I), (90,S)],
B2=[(166,T), (177,T)],
B3=[(250,U),(288,W)],
B4=[(300,S)].
Відшукуючи вузол к з ключем =177, досить переглянути список В2, бо gc(177)=2.
Реалізація індексного зберігання. Оскільки довжина списку індексів Х відома, то часто використовують послідовно-зв'язане індексне зберігання: Х - послідовно, забезпечуючи прямий доступ до його елементів; В1, В2,...,Вm - зв'язано, що спрощуї додавання та вилучення елементів.
Приклад. На вході (файл stdin) задана послідовність цілих додатніх чисел, не більших 9999, що закінчується нулем. Написати функцію для введення цієї послідовності та організації її послідовно - зв'язаного індексного зберігання так, щоб числа, які мають однакові дві останні цифри, були в одному підсписку.
За індексну функцію візьмемо g(k)=k% 100, а для індексного списку Х- масив з 100 елементів. Щоб в підсписках елементи розміщувались у порядку початкової послідовності, підсписки організуються, як циклічні списки, а після закінчення введення послідовності циклічні списки перетворюються у звичайні. Функція indtx розв'язуї задачу так:
/* index - формування індексного зберігання* /
index(X)
LISTP X[100];
{
LISTP new ( ),t; int inp` t;
for (i=0; i<100; i++) X[i]=NULL;
while(scanf ("%d",& inp)==1 && inp!=0)
if (X[i=inp%100]
{
X[i]-> next=new [inp,X[i]->next);
X[i]=X[i]->next;
}
else{X[i]=new(inp, NULL);
X[i]->next=X[i];}
for(i=0;i>100;i++)
if(t=X[i])
{
X[i]=t->next; t->next=NULL;
}
}
Індивідуальні завдання.
1. Функція Аккермана має означення:
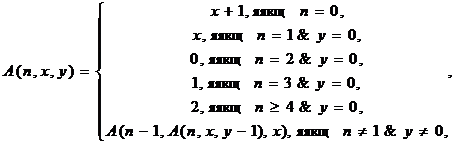
де n, x, y - цілі невід’ємні числа.
Обчислити значення функції Аккермана за допомогою стека, що містить трійки чисел (i, j, k).
2. Написати нерекурсивну функцію, яка, використовуючи стек, обчислює значення F(m,n) для будь-якої пари невід’ємних чисел n і m за співвідношенням
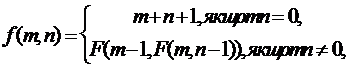
3. На вході задана послідовність n трійок (xi,yi, pi), де xi,- англійське слово, yi,- його український еквівалент, pi - частота використання ( в %) слова xi, в типовому англійському тексті. Для послідовності пар (xi,yi), інтерпретованих як лінійний список, застосоване послідовно - зв’язане зберігання. Елементи, що мають однакову першу букву англійського слова, вміщуються в один зв’язаний список, де впорядковані за спаданням частоти використання. Написати програму формування цієї структури даних та здійснення послідовного перекладу англійського речення з m слів. За відсутності перекладу конкретного англійського слова залишити його неперекладеним.
4. Многочлен від однієї змінної з цілими коефіцієнтами можна подати зв’язаним лінійним списком, впорядкованим за зростанням степеня змінної без одночленів з нульовими коефіцієнтами (на рис. зображено многочлен x5 -12x2+3). Написати функції, які реалізують над многочленами у такому поданні:
a)додавання двох многочленів;
b)множення двох многочленів;
c)ділення двох многочленів з часткою та остачею у вигляді многочленів.
5. Придумати спосіб моделювання черги за допомогою двох стеків ( та фіксованого числа змінних типу Т). При цьому обробка n операцій з чергою (таких, які починаються, коли черга порожня) повинна вимагати дій порядку n.
6. Деком називають структуру, яка поєднує чергу та стек: додавати та забирати елементи можна з обох кінців. Треба реалізувати дек обмеженого розміру на базі масиву так, щоб кожна операція потребувала обмеженого числа дій.
7. Є дек елементів типу Т (див. задачу 6) і кінчене число змінних типу Т та цілого типу. В початковому стані в деку деяке число елементів. Скласти програму, після виконання якої в деку зостались би ті ж самі елементи, а їх число було б в одній з цілих змінних.
8. Надрукувати в порядку зростання перші n натуральних чисел, в розкладу яких на прості множники входять тільки числа (2, 3, 5). (Вказівка: використати 3 черги).
9. Відомо, що орієнтований граф зв’язаний, якщо з будь якої вершини виходить стільки ж ребер, скільки входить. Довести, що існує замкнутий цикл, який проходить по кожному ребру рівно один раз. Скласти алгоритм відшукання такого циклу.
10.Довести, що для всякого n існує послідовність нулів та одиниць довжини 2n з наступною властивістю: якщо “звернути її в кільце” та розглянути всі фрагменти довжини n (їх кількість дорівнює 2n ), то одержимо всі можливі послідовності нулів та одиниць довжиною n. Побудувати алгоритм пошуку такої послідовності, який потребує не більш ніж Сn дій для деякої константі С.
11.Реалізувати k черг з обмеженою сумарною довжиною n, використовуючи пам’ять порядку n+k, причому кожна операція (крім початкової, яка робить всі черги порожніми) повинна потребувати обмеженого константою кількості дій.
12.На площині задано n точок, які пронумеровані зліва направо (а при рівних абсцисах - знизу вверх). Скласти програму, яка будує многокутник, що є випуклою їх оболонкою, за не більш ніж С*n дій.
13.За один перегляд файлу f дійсних чисел та без використання додаткових файлів надрукувати елементи файлу f в наступному порядку: спочатку всі числа менші за a, далі всі числа з відрізку [a,b], і в кінці всі інші числа, зберігаючи вихідний взаємний порядок в кожній з цих трьох груп чисел (a та b - задані числа, a<b).
14.Складове текстового файлу f , розділене на рядки, переписати в текстовий файл g, переносячи при цьому в кінець кожного рядка всі цифри, які входять до нього (з зберіганням вихідного взаємного порядку як серед цифр, так і серед решти літер рядка).
15.В текстовому файлі f записана без помилок формула такого виду:
<формула>::=<цифра>| М(<формула>,<формула>)|m(<формула>,<формула>)
<цифра>::=0|1|2|3|4|5|5|7|7|9
де М - означає функцію max, а m - min.
Визначити (як ціле число) значення даної формули (наприклад, M(5,m(6,8)) ®6).
Дата добавления: 2018-05-12; просмотров: 228; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!