Автоматическое аннотирование(Компьютер)
Министерство образования и науки Российской Федерации
Государственное образовательное учреждение высшего профессионального образования
«Ижевский государственный технический университет»
Воткинский филиал
(ВФ ИжГТУ)
Кучерова Е.А., Ившин О.А., Карлагина Н.С.
Извлечение информации из коллекции гомогенных текстов
Методическое пособие для выполнения лабораторной работы
по дисциплине "Математическая лингвистика"
для студентов, обучающихся по направлению 230100.62 «Автоматизированные системы обработки информации и управления»
Воткинск
2013
Цели:
Провести и анализировать автоматическое и ручное аннотирование (реферирование) текстов.
Задачи:
1. Выбрать одну из представленных предметных областей.
2. Найти и сформировать коллекцию документов, релевантных предметной области.
3. Протестировать точность и полноту работы автоматического и ручного аннотирования.
Теоретическое положение
Аннотация – это предельно сжатая характеристика материала. В отличие от реферата, аннотация не может заменить самого материала, так как она призвана дать лишь общее представление о содержании книги или статьи. Именно поэтому для аннотирования важно определить что является самым главным.
Ручное аннотирование(Человек)
Краткое представление о ручном аннотирование можно увидеть из таблицы ниже.
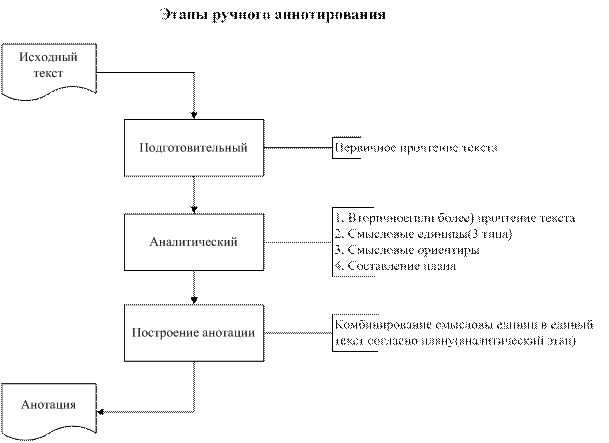
Рисунок 1- этапы ручного аннотирования
При выполнении работы по составлению аннотации человеком (референтом) обычно выделяют три этапа:
1) подготовительный — референт определяет тематическую направленность текста и пытается понять и осмыслить документ в целом;
2) аналитический — референт делит текст на некоторые фрагменты (абзацы, аспекты и т.п.). Каждый фрагмент внимательно изучается, в нем выделяют основные смысловые единицы (предложения, словосочетания, слова). Данный этап заканчивается составлением плана будущей аннотации;
3)этап непосредственного построения аннотации — выделенные ранее смысловые единицы (их комбинации или преобразования) располагаются в единый вторичный текст в соответствии с планом аннотации.
Смысловые единицы
В качестве основных смысловых единиц, выделяемых из исходного текста на 2-м этапе, могут выступать:
1. целые ключевые предложения
2. ключевые словосочетания и слова
Ключевое (опорное) слово — это термин, относящийся к основному содержанию текста и повторяющийся в нем несколько раз (с учетом всех возможных синонимов).
Ключевое словосочетание — это сочетание слов, среди которых есть одно или несколько ключевых.
Ключевым предложением считается предложение, содержащее два и более ключевых слова или ключевых словосочетания.
Вопрос, который необходимо рассмотреть, связан с тем, как человек выбирает из текста ключевые предложения, словосочетания и слова. Это делается, как уже отмечалось, на 2-м этапе общего процесса составления вторичного документа. Читая текст повторно (первый раз он читается на подготовительном этапе) или в третий раз, человек мысленно выделяет в нем три типа единиц (предложений, словосочетаний, слов):
1) единицы, которые обязательно должны быть включены в аннотацию. Такие единицы отражают новые идеи, гипотезы, новые методы, явления, процессы, новые результаты, т.е. все новое и оригинальное, что есть в исходном документе. Это, по существу, и есть основные смысловые единицы текста (ключевые предложения, словосочетания и слова);
2) единицы, которые отражают фактические данные: параметры изделий, процессов, методов и т.д. Такие единицы не являются принципиально новыми;
3) единицы, которые аргументируют и иллюстрируют единицы первых двух типов.
Единицы первого уровня обязательно используются при составлении аннотации. Из единиц второго уровня используются лишь некоторые (в зависимости от типа аннотации или её потребителя). Третья группа единиц изредка переносится в аннотацию в обобщенном виде.
Смысловыми единицами аннотации могут быть:
1) ключевые слова или словосочетания исходного текста с предшествующими им специальными фразами — реляторами типа: «В статье рассматриваются следующие вопросы:...», «Книга посвящена следующим проблемам:...»ит.п.;
2) специальные предложения, содержащие оценочные элементы: «Рассматривается важная проблема...», «Статья посвящена актуальной теме...»ит.д.;
3) специальные предложения, содержащие клише, т.е. специализированные словесные штампы, фиксирующие внимание читателя на определенных аспектах содержания: «Недостаток... заключается», «Цель публикации...», «Ставится задача...», «Делается попытка...» и т.д.
Смысловые ориентиры
Составление плана будущей аннотации заключается в выделении некоторых смысловых ориентиров, которые на 3-м этапе будут развернуты более подробно. В качестве таких ориентиров выступают:
1) основные темы и подтемы исходного текста;
2) основные аспекты исследования;
3) основные ключевые предложения, словосочетания и слова.
Автоматическое аннотирование(Компьютер)
Автоматическое реферирование и аннотирование — одно из направлений компьютерной обработки естественно-языковых текстов*. И в этом качестве оно относится к фундаментальным технологиям ИИ.
При составлении с помощью компьютера аннотации также используются как ключевые предложения (в том виде, что и при составлении реферата), так и ключевые слова и словосочетания. Последние перечисляются вслед за реляторами вида: «В статье рассматриваются следующие вопросы:...», «Книга посвящена следующим проблемам: ...», «Статья раскрывает следующие понятия: ...» и т.д.
Потребности в средствах автоматического реферирования и аннотирования испытывают: корпоративные системы документооборота; поисковые машины и каталоги ресурсов Internet; автоматизированные информационно-библиотечные системы; каналы вещания; службы рассылки новостей и др.
Основные виды автоматического реферирования можно увидеть из таблицы ниже.
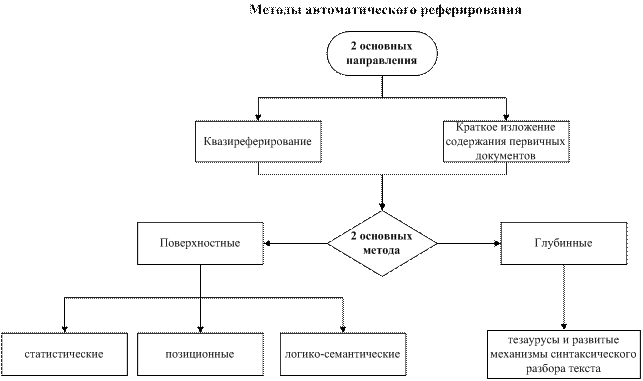
Рисунок 2- Методы автоматического реферирования
Существует много способов автоматического реферирования, которые довольно четко подразделяются на два направления - квазиреферирование и краткое изложение содержания первичных документов. Квазиреферирование основано на экстрагировании фрагментов документов - выделении наиболее информативных фраз и формировании из них квазирефератов.
В рамках квазиреферирования(поверхностный метод) выделяют три основных направления, которые в современных системах применяются совместно:
1) статистические
2) позиционные
3) логико-семантические(индикаторные)
Суть статистической группы методов заключается в том, что:
1) ключевыми словами считаются такие знаменательные слова текста, которые с учетом всех синонимов встречаются в тексте наибольшее число раз;
2) ключевым предложением считается предложение текста, которое:
а) имеет несколько ключевых слов;
б) содержит ключевые слова на небольшом расстоянии друг от друга.
Принадлежность слова, словосочетания или предложения к числу ключевых определяется специальными статистическими коэффициентами.
В позиционных методах автоматического реферирования и аннотирования ключевым предложением считается предложение, входящее в заголовок, подзаголовок, начало или конец какой-то части текста или всего текста. Такие предложения, как правило, содержат информацию о целях, методах, выводах и результатах исследования, описанного в первичном документе. Важность тех или иных предложений с указанной точки зрения определяется экспертами путем изучения семантической структуры первичных документов определенного типа.
Семантические методы формирования аннотаций предполагают два основных подхода:
1) Метод синтаксического разбора предложений
2) Методы, опирающиеся на понимание естественного языка.
В первом случае используются деревья разбора текста. Процедуры автоматического реферирования манипулируют непосредственно деревьями, выполняя перегруппировку и сокращение ветвей на основании сответствующих критериев. Такое упрощение обеспечивает построение аннотации - структурную "выжимку" исходного текста.
Второй подход основывается на системах искусственного интеллекта, в которых также на этапе анализа выполняется синтаксический разбор текста, но синтаксические деревья не порождаются. В этом случае формируются семантические структуры, которые накапливаются в виде концептуальных подграфов в базе знаний. В базах знаний избыточная и не имеющая прямого отношения к тексту информация устраняется путем отсечения некоторых подграфов. Затем информация подвергается агрегированию методом слияния оставшихся графов или их обобщения. В результате преобразования формируется концептуальная структура текста - аннотация, т.е. концептуальные "выжимки" из текста.
Многоуровневое структурирование текста с использованием семантических методов позволяет подходить к решению задачи реферирования путем:
- удаления малозначащих смысловых единиц. Преимуществом метода является гарантированное сохранение значащей информации, недостатком - низкая степень сжатия, т.е. сокращения объема реферата по сравнению с первичными документами;
- сокращения смысловых единиц - замена их основной лексической единицей, выражающей основной смысл;
- гибридного способа, заключающегося в уточнении реферата с помощью статистических методов, с использованием семантических классов, особенностей контекста и синонимических связей.
Вес терминов
TF-IDF (от англ. TF — term frequency, IDF — inverse document frequency) — статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью коллекции документов или корпуса. Вес некоторого слова пропорционален количеству употребления этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции.
Мера TF-IDF часто используется в задачах анализа текстов и информационного поиска, например, как один из критериев релевантности документа поисковому запросу, при расчёте меры близости документов при кластеризации.
Структура формулы
TF (term frequency — частота слова) — отношение числа вхождения некоторого слова к общему количеству слов документа. Таким образом, оценивается важность слова tj в пределах отдельного документа.
t = число различных терминов в коллекции документов
tfij = число вхождений термина tj в документ Di.
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции. Учёт IDF уменьшает вес широкоупотребительных слов. Для каждого уникального слова в пределах конкретной коллекции документов существует только одно значение IDF.
idfj= log( d/ dfj), где d = число всех документов, dfj = число документов содержащих tj.
Пример:

Модификации алгоритма
Следующая формула считается хорошей для подсчета весов:
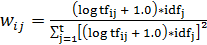 , где
, где 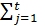 общее число слов в документе
общее число слов в документе
Решена проблема: Если в запросе и документе совпадал один термин, с высокой частотой (tf), то результат мог стать «перекошенным».
Дата добавления: 2023-01-08; просмотров: 38; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!