ЧАСТЬ 2 КОДЫ ХЕММИНГА, ГОЛЕЯ И РИДА-МАЛЛЕРА
Технологический институт
ЮЖНОГО ФЕДЕРАЛЬНОГО УНИВЕРСИТЕТА
В г.ТАГАНРОГЕ
________________________________________________________
Максимов М.Н.
Помехоустойчивое кодирование
Таганрог 2011
ГЛАВА3. 4
ЧАСТЬ 1 ВВЕДЕНИЕ.. 4
1.1. Кодирование для исправления ошибок: Основные положения. 7
1.1.1. Блоковые и сверточные коды.. 7
1.1.2. Хеммингово расстояние, Хемминговы сферы и корректирующая способность. 8
1.2. Линейные блоковые коды.. 11
1.2.1. Порождающая и проверочная матрицы.. 12
1.2.2. Вес как расстояние. 13
1.3. Кодирование и декодирование линейных блоковых кодов. 13
1.3.1. Кодирование с помощью матриц G и Н.. 13
1.3.2. Декодирование по стандартной таблице. 15
1.3.3. Хемминговы сферы, области декодирования и стандартная таблица. 19
1.4. Распределение весов и вероятность ошибки. 21
1.4.1. Распределение весов и вероятность необнаруженной ошибки в ДСК. 21
1.4.2. Границы вероятности ошибки в ДСК, каналах с АБГШ и с замираниями. 23
1.5 Общая структура жесткого декодера для линейных кодов. 33
Вопросы для самоконтроля. 34
ЧАСТЬ 2 КОДЫ ХЕММИНГА, ГОЛЕЯ И РИДА-МАЛЛЕРА.. 39
2.1. Коды Хемминга. 39
2.1.1. Процедуры кодирования и декодирования. 40
2.2. Двоичный код Голея. 43
2.2.1 Кодирование. 43
2.2.2. Декодирование. 44
2.2.3. Арифметическое декодирование расширенного (24,12,8) кода Голея. 44
2.3. Двоичные коды Рида-Маллера. 46
2.3.1. Булевы полиномы и РМ коды.. 46
2.3.2. Конечные геометрии и мажоритарное декодирование. 48
Вопросы для самоконтроля. 54
ЧАСТЬ 3 ДВОИЧНЫЕ ЦИКЛИЧЕСКИЕ КОДЫ И КОДЫ БЧХ.. 54
3.1. Двоичные циклические коды. 55
3.1.1. Порождающий и проверочный полиномы. 55
3.1.2. Порождающий многочлен. 56
3.1.3. Кодирование и декодирование двоичных циклических кодов. 57
3.1.4. Проверочный полином. 59
3.1.5. Укороченные циклические коды и CRC коды.. 61
3.2. Общий алгоритм декодирования циклических кодов. 63
3.2.1. Арифметика GF(q) 66
3.3. Двоичные коды БЧХ.. 72
3.4. Полиномиальные коды.. 74
3.5. Декодирование двоичных БЧХ кодов. 75
3.5.1. Общий метод декодирования для БЧХ кодов. 77
3.5.2. Алгоритм Берлекемпа-Мэсси (ВМА) 78
3.5.3. Декодер PGZ.. 81
3.5.4. Евклидов алгоритм (ЕА) 83
3.5.5. Метод Ченя и исправление ошибок. 85
3.5.6. Исправление стираний и ошибок. 86
3.6. Распределение весов и границы вероятности ошибки. 88
3.6.1. Оценка вероятности ошибки. 89
Вопросы для самоконтроля. 92
ЧАСТЬ 4 НЕДВОИЧНЫЕ БЧХ КОДЫ -КОДЫ РИДА-СОЛОМОНА.. 94
4.1. Коды PC как полиномиальные коды.. 94
4.2. От двоичных кодов БЧХ к PC кодам.. 95
4.3. Декодирование кодов PC.. 96
4.3.1. Комментарий к алгоритмам декодирования. 101
4.3.2. Исправление ошибок и стираний. 102
4.4. Распределение весов. 107
Вопросы для самоконтроля. 108
ГЛОССАРИЙ.. 109
ЛИТЕРАТУРА.. 110
ГЛАВА3
ЧАСТЬ 1 ВВЕДЕНИЕ
История кодов, исправляющих ошибки, началась с изобретения кодов Хемминга почти одновременно с появлением основополагающей работы Шеннона. Чуть позже были предложены коды Голея. Эти классы кодов являются оптимальными. Понятие оптимальности кода мы рассмотрим в последующих разделах.
На Рисунке 1 показана блок-схема канонической цифровой системы передачи или хранения информации. Это знаменитый Рисунок 1, с которого начинаются почти все книги по теории помехоустойчивого кодирования (в дальнейшем будет использоваться сокращение ЕСС со значением - помехоустойчивое кодирование, или кодирование с исправлением ошибок, или коды, исправляющие ошибки). Источник и получатель информации обычно включают какое-либо кодирование (преобразование) источника, соответствующее природе информации. Кодирующее устройство (кодер канала) системы помехоустойчивого кодирования получает информационные символы от источника и добавляет к ним избыточные символы таким образом, чтобы могла быть исправлена большая часть ошибок, возникающих в процессе модуляции сигналов, их передачи по каналу с шумом и демодуляции.
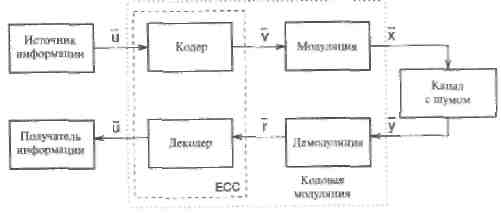
Рис. 1. Каноническая цифровая система связи.
Обычно предполагается, что в канале связи отсчеты аддитивного шумового процесса прибавляются к модулированным символам (рассматривается узкополосное комплексное представление сигналов). Отсчеты шума предполагаются независимыми от источника символов. Эту модель сравнительно легко исследовать. Она легко позволяет включить каналы с гауссовым шумом (АБГШ), каналы с общими Релеевскими замираниями, а также двоичный симметричный канал (ДСК). На приемной стороне декодирующее устройство (декодер канала) использует избыточные символы для исправления ошибок, внесенных каналом связи. В режиме обнаружения ошибок декодер ведет себя как кодер полученного из канала сообщения и проверяет совпадение вычисленных избыточных символов с принятыми.
В классической теории кодов, исправляющих ошибки, комплекс, включающий модулятор, демодулятор и шумовую среду распространения сигналов, называется дискретным каналом без памяти с входом v и выходом г. Примером такого канала является система передачи двоичных сигналов по каналу с АБГШ (аддитивным белым гауссовым шумом), который моделируется как двоичный симметричный канал с вероятностью ошибки (или вероятностью перехода) р равной вероятности ошибки на бит для двоичного сигнала в АБГШ,
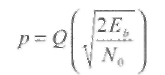 (1.1)
(1.1)
где
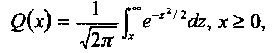 (1.2)
(1.2)
является гауссовой Q-функцией и Еb/N0 есть отношение сигнал-шум (SNR) на бит. Этот случай будет исследован ниже в этой части.
В 1974 Мэсси предложил рассматривать помехоустойчивое кодирование (ЕСС) и модуляцию как единое целое, известное в современной литературе как кодовая модуляция (coded modulation) (Часто используется и несколько более точный термин — сигнально кодовая конструкция). Совместное конструирование кода и множества сигнальных точек обеспечивает более высокую эффективность и больший (энергетический) выигрыш от кодирования (coding gain) {Выигрыш от кодирования определен как разность между отношениями сигнал-шум системы с кодированием и системы без кодирования при одинаковой скорости (и одинаковой вероятности ошибки)}, чем последовательное применение ЕСС и модуляции. В этой пособии рассмотрены некоторые методы комбинирования кодирования и модуляции, включая: решетчатую кодовую модуляцию (ТСМ— trellis-coded modulation) in многоуровневую кодовую модуляцию (МСМ — multilevel coded modulation). В системах кодовой модуляции «мягкое решение» (soft decision) на выходе канала вводится непосредственно в декодер и обрабатывается им. Напротив, в классической системе с помехоустойчивым кодированием в декодер вводится «жесткое решение» (hard decision) демодулятора.
Коды, исправляющие ошибки, можно комбинировать различными способами. Примером последовательного каскадирования (serial concatenation, т.е. каскадная конструкция в классическом смысле) является следующая конструкция. Многие годы наиболее популярной каскадной схемой ЕСС была комбинация внешнего кода Рида-Соломона (PC), промежуточного перемежения (или перемешивания — interleaving) и внутреннего сверточного кода. Эта конструкция была использована во многих приложениях от систем космической связи до цифровых широковещательных систем телевидения высокой четкости. Основная идея состоит в том, что пакеты ошибок, которые появляются на выходе декодера сверточного кода с мягким решением, могут быть разбиты на мелкие части с помощью интерливинга и затем полностью исправлены декодером кода PC. Коды Рида-Соломона являются недвоичными кодами, каждый символ которых состоит из нескольких двоичных бит. Эти коды способны исправлять многократные пакеты ошибок. Преимуществом каскадной конструкции является то, что для нее требуются раздельные декодеры внутреннего и внешнего кодов вместо одного, но очень сложного декодера для каскадного кода в целом.
В пособии изучаются разные типы систем с ЕСС. Сначала рассматриваются базовые кодовые конструкции и алгоритмы их декодирования в Хемминговом пространстве (т.е. работающие с битами). Затем, во второй части пособия, вводятся алгоритмы декодирования с мягким решением для передачи двоичных сигналов, работающие в Евклидовом пространстве. В системах этого типа необходимая мощность передаваемых сигналов снижается на 2 дБ/бит по сравнению с декодерами в Хемминговом пространстве (с жестким решением). Рассматриваются декодеры с мягким решением нескольких типов. При этом основное внимание уделяется собственно алгоритмам (тому, как они работают), а не теоретическим вопросам (почему они работают).
1.1. Кодирование для исправления ошибок: Основные положения
Все коды, исправляющие ошибки, основаны на одной общей идее: для исправления ошибок, которые могут возникнуть в процессе передачи или хранения информации, к ней добавляется некоторая избыточность. По основной схеме (используемой на практике), избыточные символы дописываются вслед за информационными, образуя кодовую последовательность или кодовое слово (codeword). В качестве иллюстрации на Рисунке 2 показано кодовое слово, сформированное процедурой
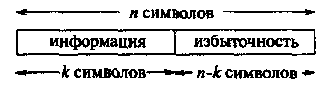
Рис.2. Систематическое блоковое кодирование для исправления ошибок.
кодирования блокового кода (block code). Такое кодирование называют систематическим (systematic). Это означает, что информационные символы всегда появляются на первых к позициях кодового слова. Символы на оставшихся п-к позициях являются различными функциями от информационных символов, обеспечивая тем самым избыточность, необходимую для обнаружения или исправления ошибок. Множество всех кодовых последовательностей называют кодом, исправляющим ошибки (error correcting code), и обозначают через С.
1.1.1. Блоковые и сверточные коды
В соответствии с тем, как вводится избыточность в сообщение, коды, исправляющие ошибки, могут быть разделены на два класса: блоковые и сверточные (convolutional code) коды. Обе схемы кодирования нашли практическое применение. Исторически сверточные коды имели преимущество главным образом потому, что для них известен алгоритм декодирования Витерби с мягким решением и в течение многих лет существовала убежденность в том, что блоковые коды невозможно декодировать с мягким решением. Однако последние достижения в теории и конструировании алгоритмов декодирования с мягким решением для линейных блоковых кодов помогли рассеять это убеждение. Более того, наилучшие ЕСС, известные сегодня (в начале двадцать первого века), являются блоковыми кодами (нерегулярными кодами с низкой плотностью проверок - irregular low-density parity-check codes).
При блоковом кодировании каждый блок информационных символов обрабатывается независимо от других. Другими словами, блоковое кодирование является операцией без памяти в том смысле, что кодовые слова не зависят друг от друга. Выход сверточного кодера, напротив, зависит не только от информационных символов в данный момент, но и от предыдущих символов на его входе или выходе. Чтобы упростить объяснения, мы начнем с изучения структурных свойств блоковых кодов. Многие из этих свойств являются общими для обоих типов кодов.
Следует заметить, что на самом деле блоковые коды обладают памятью, если рассматривать кодирование как побитовый процесс в пределах кодового слова. Сегодня это различие между блоковыми и сверточными кодами кажется все менее и менее ясным, особенно после недавних достижений в понимании решетчатой (trellis) структуры блоковых кодов и кольцевой (tail-biting) структуры некоторых сверточных кодов.
Примечание: Название кольцевые сверточные коды еще не окончательно утвердилось в отечественной литературе, иногда tail-biting convolutional codes называют циклически замкнутыми.
Специалисты по сверточным кодам иногда рассматривают блоковые коды как «коды с меняющейся во времени структурой решетки» (time-varying trellis structure). Аналогично, специалисты в области блоковых кодов могут рассматривать сверточные коды как «коды с регулярной структурой решетки».
1.1.2. Хеммингово расстояние, Хемминговы сферы и корректирующая способность
Рассмотрим двоичный код С, исправляющий ошибки. Если не все из 2п возможных двоичных векторов длины п будут передаваться по каналу связи, то этот код может обладать свойством помехоустойчивости. В действительности, код С является подмножеством w-мерного двоичного векторного пространства V2 = {0, 1}nтаким, что элементы этого подмножества максимально удалены друг от друга.
В двоичном пространстве V2 расстояние определяется как число позиций, на которых два вектора не совпадают. Пусть x1=(x1,0, x1,1, …,x1,n-1) и х2=(х2,0 , х2,1,..., x2,n-1) два вектора в V2. Тогда Хеммингово расстояние между векторами х1 и х2, обозначаемое как dH(x1, x2), равно
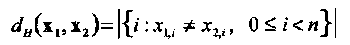 (1.3)
(1.3)
где через |А| обозначено число элементов в множестве А.
Для заданного кода С минимальное Хеммингово расстояние, dmin, определяется как минимум Хеммингова расстояния по всем возможным парам различных кодовых слов,
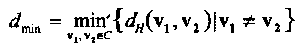 (1.4)
(1.4)
Повсюду в пособии обозначение (n, k, dmin) используется для параметров блокового кода длины n, который используется для кодирования сообщений длины k, и имеет минимальное Хеммингово расстояние dmin. Предполагается, что число кодовых слов этого кода равно |С|=2k.
Пример 1.Простейшим примером является код-повторение длины 3. Каждый информационный бит повторяется три раза. Таким образом, сообщение «0» кодируется вектором (000), а сообщение «1», вектором (111). Так как два вектора различаются в трех позициях, Хеммингово расстояние между ними равно 3. На Рисунке 3 показано графическое представление этого кода. Трехмерное двоичное векторное пространство соответствует 23=8 вершинам трехмерного единичного куба. Хеммингово расстояние между кодовыми словами (000) и (111) равно числу вершин, через которые проходит соединяющий их путь. Это эквивалентно числу координат, которые необходимо изменить, чтобы преобразовать (000) в (111) и наоборот. Таким образом, dH= ((000),(111)) = 3. Так как в этом коде только два кодовых слова, то dmin = 3.
Двоичное векторное пространство V2 обычно называют Хемминговым пространством. Пусть v кодовое слово кода С. Хемминговой сферой St(v) радиуса t с центром в точке v является
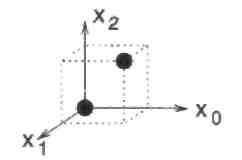
Рис. 3. (3,1,3) код-повторение в трехмерном векторном пространстве.
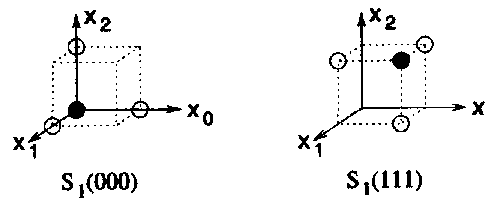
Рис. 4. Хемминговы сферы радиуса t=1, окружающие кодовые слова (3,1,3) двоичного кода-повторения.
множество векторов (точек) в V2 на расстоянии меньше или равном t от центра v,
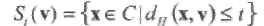 (1.5)
(1.5)
Заметим, что число слов (число векторов) в St(v) равно
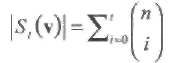 (1.6)
(1.6)
Пример 2. На Рисунке 4 показаны Хемминговы сферы радиуса t = 1, окружающие кодовые слова (3,1,3) двоичного кода-повторения.
Заметим, что Хемминговы сферы для этого кода не пересекаются, т.е. в пространстве V2 нет векторов (или вершин в единичном трехмерном кубе), принадлежащих одновременно и S1(000), и S1(111). В результате, если изменить любую одну позицию кодового слова v, то получится вектор, который, тем не менее, останется внутри Хемминговой сферы с центром в v. Эта идея является принципиальной для понимания и определения корректирующей способности кода С.
Корректирующей способностью (error correcting capability) t кода С называют наибольший радиус Хемминговой сферы St(v) для всех кодовых слов v  C такой, что для любых различных пар vi, vj
C такой, что для любых различных пар vi, vj  С соответствующие им Хемминговы сферы не пересекаются, т.е.
С соответствующие им Хемминговы сферы не пересекаются, т.е.
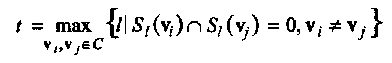 (1.7)
(1.7)
Это соответствует более распространенному определению
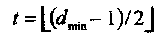 (1.8)
(1.8)
где [x] обозначена целая часть x, т.е. целое число меньше или равное x.
Заметим, что для определения минимального кодового расстояния произвольного блокового кода С в соответствии с (1.4), необходимо вычислить все 2k(2k — 1) расстояний между различными парами кодовых слов. Это практически невозможно даже для сравнительно коротких кодов, например, с к = 50. Одним из важных преимуществ линейных блоковых кодов является то, что для вычисления dmin достаточно знать только Хемминговы веса 2к — 1 ненулевых кодовых слов.
1.2. Линейные блоковые коды
Как уже упоминалось выше, построение хорошего кода означает поиск в V2 подмножества элементов в наибольшей степени удаленных друг от друга. Это очень трудная задача. Более того, если даже это сделано, то остается неясным как назначить кодовые слова информационным сообщениям.
Линейный код (т.е. множество кодовых слов) является векторным подпространством в пространстве V2. Это означает, что операция кодирования может быть представлена умножением на матрицу. В терминах цифровой электроники простое кодирующее устройство может быть построено на элементах «исключающее ИЛИ», «И» и триггерах типа D. В этой части операциями сложения и умножения вдвоичном векторном пространстве являются «исключающее ИЛИ» (сложение по модулю 2) и «И», соответственно. Таблицы сложения и умножения двоичных элементов имеют следующий вид:
| а | b | a+b | ab |
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |
1.2.1. Порождающая и проверочная матрицы
Пусть С двоичный линейный (п, к, dmin) код. Так как С есть k-мерное подпространство, то оно имеет базис, например, (v0, v1,…, vk-1) такой, что любое кодовое слово v 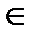 С может быть записано как линейная комбинация элементов этого базиса:
С может быть записано как линейная комбинация элементов этого базиса:
 (1.9)
(1.9)
где ui 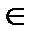 {0, 1}, 0 ≤ i < k. Уравнение (1.9) может быть записано в матричной форме через порождающую матрицу G и вектор-сообщение и = (и0, u1, …, uk-1):
{0, 1}, 0 ≤ i < k. Уравнение (1.9) может быть записано в матричной форме через порождающую матрицу G и вектор-сообщение и = (и0, u1, …, uk-1):
v=uG (1.10)
где
 (1-11)
(1-11)
Так как С является k- мерным векторным пространством в V2, то существует (n-k)-мерное дуальное пространство (dual space) С┴, которое порождается строками матрицы Н, называемой проверочной матрицей (parity-check matrix), такой, что GHT=0,где через НT обозначена транспонированная матрица Н. Заметим, в частности, что любое кодовое слово v  С удовлетворяет условию
С удовлетворяет условию
vHT=0 (1.12)
Как будет показано в разделе 1.3.2 уравнение (1.12) является фундаментальным для декодирования линейных кодов.
Линейный код С┴, который генерируется матрицей Н, является двоичным линейным (п, п - k, d┴min) кодом, который называют обычно дуальным коду С.
1.2.2. Вес как расстояние
Как упоминалось в разделе 1.1.2, линейные коды отличаются тем, что для определения минимального расстояния кода достаточно знать минимум Хеммингова веса ненулевых кодовых слов. Ниже этот факт будет доказан. Определим вес Хемминга wtH (x) вектора х  V2, как число ненулевых элементов в х. Из определения Хеммингова расстояния ясно, что wtH(x) = dH(x, 0). Для двоичного линейного кода С получаем
V2, как число ненулевых элементов в х. Из определения Хеммингова расстояния ясно, что wtH(x) = dH(x, 0). Для двоичного линейного кода С получаем
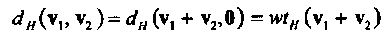 (1-13)
(1-13)
Наконец, из свойства линейности кода имеем v1+v2 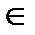 C. Отсюда следует, что минимальное расстояние кода С равно и может быть вычислено как минимальный вес по всем 2к — 1 ненулевым кодовым словам. Эта задача существенно проще, чем полный перебор по всем парам кодовых слов, хотя и остается очень сложной даже для кодов среднего размера (или размерности к).
C. Отсюда следует, что минимальное расстояние кода С равно и может быть вычислено как минимальный вес по всем 2к — 1 ненулевым кодовым словам. Эта задача существенно проще, чем полный перебор по всем парам кодовых слов, хотя и остается очень сложной даже для кодов среднего размера (или размерности к).
1.3. Кодирование и декодирование линейных блоковых кодов
1.3.1. Кодирование с помощью матриц G и Н
Равенство (1.10) определяет по существу правило кодирования для линейного блокового кода, которое может быть использовано непосредственно. Если кодирование должно быть систематическим, то произвольная порождающая матрица G линейного блокового (n, к, dmin) кода С может быть преобразована к систематической форме Gsys (иначе, к канонической форме) с помощью элементарных операций и перестановок столбцов матрицы. Матрица Gsys состоит из двух подматриц: k×k единичной матрицы, обозначаемой Ik, и k× (n-k) проверочной подматрицы Р. Таким образом,
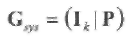 (1.14)
(1.14)
где
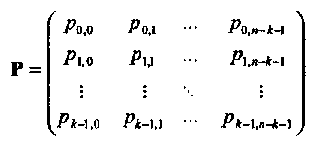 (1.15)
(1.15)
Так как GHT = 0, то отсюда следует, что систематическая форма проверочной матрицы имеет вид
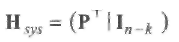 (1-16)
(1-16)
Пример 3.Рассмотрим двоичный линейный (4,2,2) код с порождающей матрицей
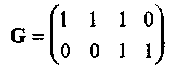
Перестановкой второго и четвертого столбцов преобразуем эту матрицу в систематическую форму
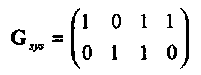
Таким образом, проверочная подматрица равна
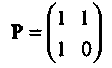
Интересно отметить, что в данном случае выполняется соотношение Р = Рт. Из (1.16)следует, что систематическая форма проверочной матрицы имеет вид
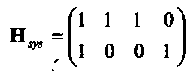
В дальнейшем будет использовано обозначение u = (u0, u1,…,uk-1) для информационного сообщения и обозначение v = (v0, vl,..., vn-1) для соответствующего кодового слова кода С.
Если параметры С таковы, что k<(n- k) или, эквивалентно, скорость кода k/п < 1/2, то кодирование с помощью порождающей матрицы более экономно по числу логических операций.
В этом случае
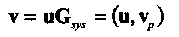 (1.17)
(1.17)
где vр= uP = (vk,vk+1,…,vn-1) представляет проверочную часть кодового слова.
Однако, если k>(n-k) или k/n > 1/2, тогда кодирование с помощью проверочной матрицы Н требует меньшего количества вычислений. Этот вариант кодирования основан на уравнении (1.12) (u, vp)HT= 0. Проверочные позиции (vk, vk+1, …, vn-1) вычисляются следующим образом:
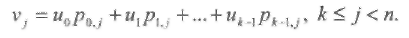 (1.18)
(1.18)
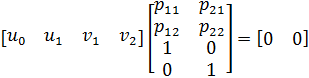
Можно сказать, что элементами систематической формы проверочной матрицы являются коэффициенты проверочных уравнений, из которых вычисляются проверочные символы. Этот факт будет использован при обсуждении кодов с низкой плотностью проверок.
Пример 4.Рассмотрим двоичный линейный (4,2,2) код из примера 3. Пусть сообщение и кодовые слова обозначены u= (u0,u1) иv = (v0, v1, v2, v3), соответственно. Из уравнения (1.18) получаем
v2=u0+ u1,
V3=u0
Соответствие между 22 = 4 двух битными сообщениями и кодовыми словами имеет следующий вид:
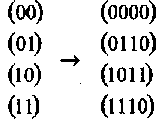 (1-19)
(1-19)
1.3.2. Декодирование по стандартной таблице
В этом разделе представлена процедура декодирования, которая находит кодовое слово v, ближайшее к принятому с искажениями слову r = v + е, где вектор ошибок е 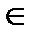 {0, 1} создан двоичным симметричным каналом (ДСК) в процессе передачи кодового слова. Модель ДСК показана на Рисунке 5. По предположению переходная вероятность р (или параметр ДСК) меньше 1/2.
{0, 1} создан двоичным симметричным каналом (ДСК) в процессе передачи кодового слова. Модель ДСК показана на Рисунке 5. По предположению переходная вероятность р (или параметр ДСК) меньше 1/2.
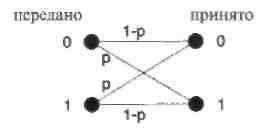
Рис.5. Модель двоичного симметричного канала.
Стандартной таблицей (или стандартной расстановкой) для двоичного линейного (n, k, dmin) кода С называется таблица всех возможных принятых из канала векторов r, организованная таким образом, что может быть найдено ближайшее к r кодовое слово v.
Таблица 1. Стандартная таблица двоичного линейного блокового кода.
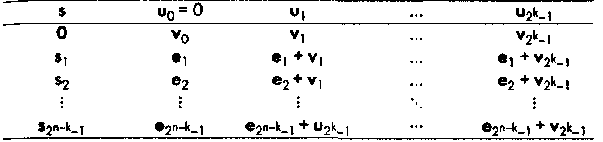
Стандартная таблица содержит 2n-k строк и 2к + 1 столбцов. Правые 2к столбцов таблицы содержат все вектора из пространства V2={0,1}n
Для описания процедуры декодирования необходимо ввести понятие синдрома. Определение синдрома произвольного слова из V2 следует из уравнения (1.12),
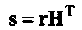 (1-20)
(1-20)
где Н проверочная матрица кода С. Покажем, что синдром является индикатором вектора ошибок. Предположим, что кодовое слово v С, переданное по ДСК, принято как r = v + е. Синдром принятого слова равен
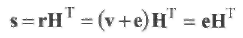 (1.21)
(1.21)
Таким образом, вычисление синдрома можно рассматривать как линейное преобразование вектора ошибок.
Процедура построения стандартной таблицы
Правые столбцы первой строки заполним кодовыми словами кода С, начиная с нулевого кодового слова. В первую ячейку первого столбца запишем нулевой синдром. Положим j = 0.
Для j =j + 1, найдем слово еj V2 минимального веса Хемминга, не являющееся кодовым и не включенное в предыдущие строки таблицы. Соответствующий синдром sj = ejHT запишем в первый (крайний левый) столбец j-ой строки. В оставшиеся 2к ячеек этой строки запишем суммы ej и содержимого первой строки (т.е. кодового слова).
3. Повторяем шаг 2 процедуры, пока все вектора из V2 не окажутся включенными в таблицу. Эквивалентно, повторяем шаг 2 пока j <2п-к, иначе Стоп.
Пример 5. Стандартная таблица двоичного линейного (4,2,2) кода:
| S | 00 | 01 | 10 | 11 |
| 00 | 0000 | 0110 | 1011 | 1101 |
| 11 | 1000 | 1110 | 0011 | 0101 |
| 10 | 0100 | 0010 | 1111 | 1001 |
| 01 | 0001 | 0111 | 1010 | 1100 |
Декодирование с помощью стандартной таблицы выполняется следующим образом. Пусть r = v +е принятое слово. Найдем это слово в таблице и возьмем в качестве результата декодирования сообщение u, записанное в верхней (первой) ячейке того столбца, в котором лежит принятое слово r. По идее, этот процесс требует хранения в памяти всей таблицы и поиска в ней заданного слова.
Однако, возможно некоторое упрощение процедуры декодирования, если заметить, что все элементы одной и той же строки имеют один и тот же синдром. Каждая строка Rowi,0 ≤i<2n-k, этой таблицы представляет смежный класс кода С, а именно, Rowi= { ei +v|v C}. Вектор еi называется лидером смежного класса.
Синдром всех элементов i-ой строки равен
 (1.22)
(1.22)
и не зависит от конкретного значения кодового слова v С. Упрощенная процедура декодирования состоит в следующем: вычислить синдром принятого слова r = еj + v
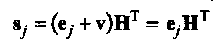
и найти его в левом столбце стандартной таблице; взять лидер смежного класса еj из второго столбца той же строки и прибавить его к принятому слову, получив ближайшее к принятому r = е’j + v’кодовое слово v’.
Таким образом, вместо таблицы п×2п бит для декодирования достаточно использовать таблицу лидеров смежных классов п х 2n-kбит.
Пример 6.Снова рассмотрим двоичный линейный (4, 2, 2) код из Примера 3. Положим, что передано было кодовое слово (0110), а принято слово (0010). Тогда синдром равен
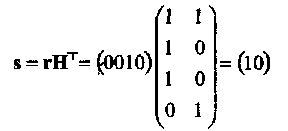
Находим в стандартной таблице лидер смежного класса (0100) и получаем декодированное кодовое слово (0010)+(0100)=(0110). Одиночная ошибка в слове исправлена! Это может показаться странным, так как минимальное кодовое расстояние равно 2 и, согласно условию (1.8), исправление однократных ошибок невозможно. Однако объяснение этому может быть найдено в стандартной таблице (Пример 5). Заметим, что третья строка таблицы содержит два различных двоичных вектора веса 1. Это означает, что только три из возможных четырех одиночных ошибок могут быть исправлены. В Примере 6 дана одна из исправляемых ошибок.
Оказывается, что данный (4, 2, 2) код является простейшим примером линейного кода с неравной защитой от ошибок (linear unequal error protection - LUEP код). Данному LUEP коду соответствует разделяющий вектор (3,2), который показывает, что минимальное кодовое расстояние равно трем, если различаются первые биты сообщений и равно двум, если различаются вторые биты сообщений.
В случае систематического кодирования рассмотренная выше процедура находит оценку переданного сообщения на первых kпозициях декодированного слова. Это может быть одной из возможных причин применения систематического кодирования.
1.3.3. Хемминговы сферы, области декодирования и стандартная таблица
Стандартная таблица предоставляет удобный способ объяснения понятий Хемминговой сферы и корректирующей способности линейного кода С, введенной в Разделе 1.1.2.
Из конструкции стандартной таблицы видно, что j-ый столбец из 2k правых столбцов таблицы, обозначаемый Colj, 1 ≤ 2k, содержит кодовое слово vj С и множество 2n-kслов, ближайших к нему по Хеммингову расстоянию, т.е.
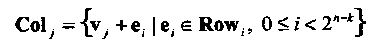 (1.23)
(1.23)
Каждый столбец (1.23) представляет собой область декодирования j-ого кодового слова в Хемминговом пространстве. Таким образом, если по ДСК передано кодовое слово vj С и принятое слово rпринадлежит столбцу Colj, то оно будет успешно декодировано в переданное слово vj.
Граница Хемминга
Множество столбцов Coljи корректирующая способность t кода С связаны между собой через Хеммингову сферу St(yj) следующим образом: двоичный линейный (п, k, d) код С имеет корректирующую способность t, если каждая область декодирования Со1jсодержит Хеммингову сферу радиуса t, т.е. St(vj) 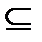 Colj.
Colj.
Учитывая, что каждая область декодирования содержит 2n-kслов, и, используя уравнение (1.6), получаем знаменитую границу Хемминга
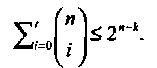 (1-24)
(1-24)
где 
Граница Хемминга имеет несколько комбинаторных интерпретаций. Вот одна из них:
Число синдромов 2n-k должно быть больше или равно числу исправляемых комбинаций ошибок, 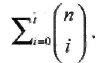
Пример7. Двоичный код (3,1,3) имеет порождающую матрицу G = (111) и проверочную матрицу
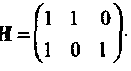
Соответственно, стандартная таблица имеет вид:
| S | 0 | 1 |
| 00 | 000 | 111 |
| 11 | 100 | 011 |
| 10 | 010 | 101 |
| 01 | 001 | 110 |
Четыре вектора во втором столбце таблицы (т.е. лидеры смежных классов) являются элементами Хемминговой сферы S1(000), показанной на Рисунке 4. Этот столбец содержит все векторы длины 3 ивеса 1 или меньше. Аналогично, третий столбец (правый) содержит все элементы S1(111). Для этого кода граница Хемминга выполняется с равенством.
Блоковые коды, удовлетворяющие границе (1.24) с равенством, называются совершенными кодами. Нетривиальными совершенными кодами являются следующие:
- двоичные (2т - 1, 2т - т - 1, 3) коды Хемминга,
- недвоичные (qт - 1)/(q - 1), (qm - 1)/(q - 1) - т - 1, 3) коды Хемминга, q > 2.
- коды-повторения (n,1,n),
- коды с проверкой на четность (n,n-1,2),
- двоичный (23,12,7) код Голея и
- троичный (11,6,5) код Голея.
Расширенные, т.е. дополненные общей проверкой на четность, коды Хемминга и Голея тоже совершенны.
Для недвоичных кодов граница Хемминга имеет вид:
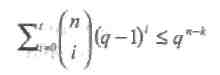
1.4. Распределение весов и вероятность ошибки
При выборе конкретной схемы кодирования очень важно иметь представление об ее помехоустойчивости. Известны несколько характеристик помехоустойчивости систем с исправлением ошибок. В этом разделе вводятся оценки для линейных кодов и трех базовых моделей каналов: модель ДСК, модель с аддитивным белым гауссовым шумом (АБГШ) и модель канала с общими Релеевскими замираниями.
1.4.1. Распределение весов и вероятность необнаруженной ошибки в ДСК.
Распределение весов W(С) = {Ai ,0 ≤ i ≤ n} кода С, исправляющего ошибки, определено как совокупность п + 1 целых Ai где Ai — количество кодовых слов Хеммингова веса i.
В следующем ниже разделе выводится оценка вероятности необнаруженной ошибки линейного кода в ДСК. Заметим, прежде всего, что вес wt(v) слова v равен Хеммингову расстоянию до нулевого слова, т.е. wt(v) = dH(v,0). Напомним также, что Хеммингово расстояние между кодовыми словами v1 и v2 равно весу их разности,
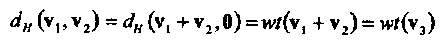
где из линейности кода следует, что v3 С
Вероятность необнаруженной ошибки PU(C) равна вероятности того, что принятое из канала связи слово отличается от переданного, но имеет нулевой синдром, т.е.
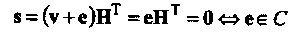
Таким образом, вероятность того, что синдром принятого ненулевого слова равен нулю, есть вероятность того, что вектор ошибок совпадает с одним из ненулевых кодовых слов.
В ДСК вектор ошибок веса i возникает с вероятностью, равной вероятности того, что i символов приняты с ошибкой, а остальные n-i приняты правильно. Обозначим вероятность этого события через Р(е,i). Тогда
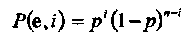
Для того чтобы возникла необнаруженная ошибка, вектор ошибок должен быть ненулевым кодовым словом. Имеется Аi кодовых слов веса i в кодовом множестве С. Следовательно,
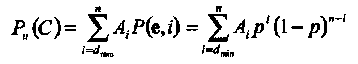 (1.26)
(1.26)
Формула (1.26) дает точное значение Ри(С) в ДСК. К сожалению, для большинства кодов, имеющих практическое значение, распределение весов неизвестно. В таких случаях, можно использовать тот факт, что число кодовых слов веса i меньше (или равно) общего числа слов веса i в двоичном векторном пространстве V2. Следовательно, справедлива следующая верхняя граница:
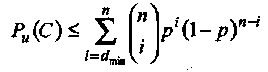 (1.27)
(1.27)
Примечание На самом деле допустима и более сильная оценка:
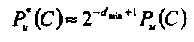
В уравнении еНт = 0 матрица Н имеет ранг p=dmin-1 и, по меньшей мере, р неизвестных элементов любого вектора ошибок еопределяются однозначно. Следовательно, средняя вероятность того, что произвольный вектор ошибок совпадает с некоторым кодовым словом, не превосходит 2-p.
Формулы (1.26) и (1.27) полезны в системах, использующих помехоустойчивое кодирование только для обнаружения ошибок таких, как системы связи с обратной связью и автоматическим
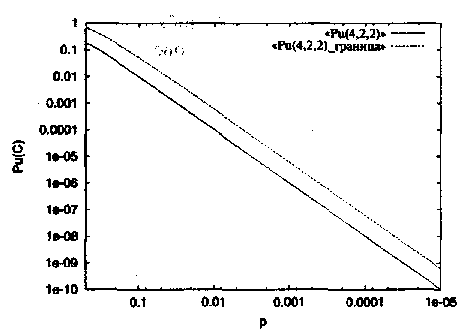
Рис. 6. Точное значение и верхняя граница вероятности необнаруженной ошибки для двоичного линейного (4,2,2) кода в ДСК.
запросом (ARQ) на повторную передачу сообщения с обнаруженными ошибками. Оценки помехоустойчивости для случая, когда кодирование используется для исправления ошибок, выводятся в следующем ниже разделе.
Пример 8.Для двоичного линейного (4,2,2) кода из Примера 4 W(C)=( 1,0,1,2,0). С помощью (1.26) находим

На Рисунке 6 показана зависимость Ри(С) вместе с правой частью границы (1.27).
1.4.2. Границы вероятности ошибки в ДСК, каналах с АБГШ и с замираниями
Целью этого раздела является введение в базовые модели каналов связи, которые будут рассматриваться в пособии, и вывод формул для оценки помехоустойчивости линейных кодов. Первым рассматривается ДСК.
Модель ДСК
Для двоичного линейного кода процедура декодирования с помощью стандартной таблицы состоит в выборе кодового слова, ближайшего к принятому слову. Ошибка декодирования возникает всякий раз, когда принятое слово оказывается вне правильной области декодирования.
Обозначим Li число лидеров смежных классов веса i в стандартной таблице линейного кода С. Вероятность правильного декодирования равна вероятности того, что вектор ошибок совпадает с одним из лидеров смежных классов,
 (1.28)
(1.28)
где  это максимальный вес лидера смежного класса е. Для совершенных кодов
это максимальный вес лидера смежного класса е. Для совершенных кодов  = t,
= t,
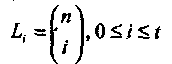
и из границы Хемминга (1.24) следует, что
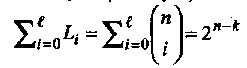
В общем случае для двоичных кодов выражение (1.28) дает нижнюю границу PC(C), так как существует хотя бы один лидер смежного класса веса более t.
Вероятность неправильного декодирования 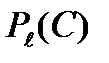 или вероятность ошибки декодирования равна вероятности того, что вектор ошибок принадлежит дополнению множества исправляемых ошибок, т.е. Pe(C) = 1 - PC(C). Из (1.28) получаем,
или вероятность ошибки декодирования равна вероятности того, что вектор ошибок принадлежит дополнению множества исправляемых ошибок, т.е. Pe(C) = 1 - PC(C). Из (1.28) получаем,
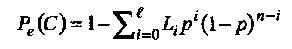 (1-29)
(1-29)
Наконец, учитывая обсуждение оценки (1.28), получаем верхнюю границу
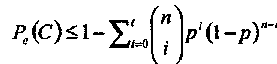 (1.30)
(1.30)
которую можно записать и в следующем виде
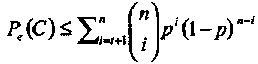 (1.31)
(1.31)
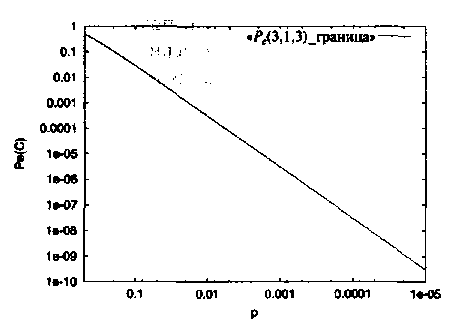
Рис.7. Вероятность ошибки декодирования для двоичного (3,1,3) кода.
Эти границы удовлетворяются с равенством только для совершенных кодов (когда и граница Хемминга удовлетворяется с равенством).
Пример 9.На Рисунке 7 показана зависимость Ре(С) по оценке (1.31) от переходной вероятности ДСК p для двоичного (совершенного) кода-повторения (3,1,3).
Модель канала с АБГШПожалуй, наиболее важной моделью для систем цифровой связи является модель канала с аддитивным белым гауссовым шумом (АБГШ - additive white Gaussian noise (AWGN)). В этом разделе выводятся оценки вероятности ошибки декодирования и вероятности ошибки на бит для линейных кодов в канале с АБГШ. Хотя аналогичные выражения оказываются справедливыми и для сверточных кодов, они будут выведены в последующих разделах, вместе с обсуждением декодирования с «мягким решением» по алгоритму Витерби. Следующие ниже результаты содержат необходимые инструменты для оценки помехоустойчивости двоичных систем кодирования в гауссовом канале.
Рассмотрим двоичную систему передачи сигналов, в которой кодовые символы {0,1} отображаются в действительные числа {+1,-1}, соответственно, как показано на Рисунке 8. В дальнейшем, вектора имеют размерность п и обозначение х = (x0, x1, …, xn-1). Условная функция плотности вероятности (ф.п.в.) последовательности у на выходе канала при условии, что на его входе передавалась последовательность х, равна
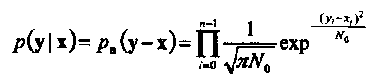 (1-32)
(1-32)
где рп(п) есть ф.п.в. п статистически независимых и одинаково распределенных (i.i.d.) отсчетов шума, каждый из которых имеет Гауссово распределение с нулевым средним и дисперсией, равной N0/2. Величина N0 называется односторонней спектральной плотностью мощности шума. Легко показать, что декодирование по максимуму правдоподобия (м.п.) линейного кода в таком канале соответствует выбору последовательности х', минимизирующей квадрат Евклидова расстояния между принятой последовательностью у и х', т.е.
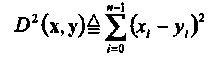 (1.33)
(1.33)
Следует заметить, что декодер, использующий (1.33) как метрику, называется декодером с мягким решением не зависимо от того, используется или нет принцип максимума правдоподобия.

Рис.8. Система двоичной передачи с кодированием по каналу с АБГШ.
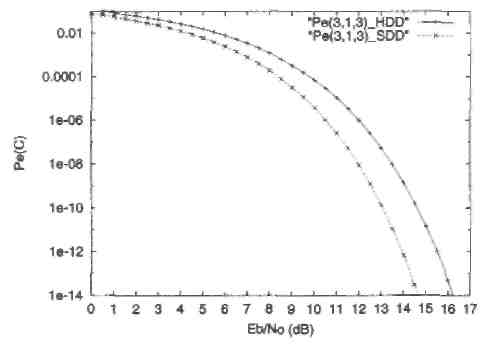
Рис.9. Вероятность ошибки декодирования для жесткого декодирования (Pt(3,l,3)_HDD) и мягкого декодирования (Pe(3,l,3)_SDD) двоичного (3,1,3) кода при передаче двоичных сигналов в канале с АБГШ.
Вероятность ошибки для МП декодирования, Ре(С), равна вероятности того, что при передаче последовательности х вектор шума оказался таким, что принятая последовательность у = х + n ближе к другой кодовой последовательности х" 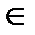 С, х" ≠ х. Для линейного кода можно предположить, что передается нулевое кодовое слово. Тогда вероятность Ре(С) может быть ограничена сверху с помощью границы объединения и распределения весов W(C) следующим образом:
С, х" ≠ х. Для линейного кода можно предположить, что передается нулевое кодовое слово. Тогда вероятность Ре(С) может быть ограничена сверху с помощью границы объединения и распределения весов W(C) следующим образом:
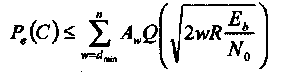 (1-34)
(1-34)
где R = k/n скорость кода, Еь/N0 отношение энергии сигнала на бит к мощности шума или (SNR на бит) и Q(x) определено в (1.2).
На Рисунке 9 показаны оценки вероятности ошибки для жесткого декодирования (1.30) и для мягкого декодирования (1.34) для двоичного (3,1,3) кода. Декодирование с жестким решением (или жесткое декодирование) означает, что декодер для ДСК использует выход двоичного демодулятора. Эквивалентный ДСК имеет переходную вероятность равную
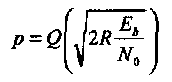
Заметим, что в данном частном случае, обе оценки вероятности ошибки являются точными, т.е. не оценками сверху, так как используется совершенный код, содержащий только два кодовых слова. Рисунок 9 показывает также, что мягкое декодирование обеспечивает большую эффективность, чем жесткое декодирование, в том смысле, что одинаковое значение Pe(C) при меньшей мощности передачи сигналов. Разность (в дБ) между соответствующими отношениями SNR на бит обычно называют выигрышем от кодирования.
Показано, что для вероятности ошибки на бит, обозначаемой Pb(C) двоичного систематического кода при передаче двоичных сигналов по каналу с АБГШ, справедлива следующая верхняя граница:
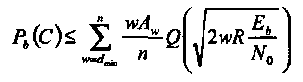 (1.35)
(1.35)
Эта граница справедлива только для систематического кода. Кроме того, систематическое кодирование минимизирует вероятность ошибки на бит. Это означает, что систематическое кодирование не только желательно, но и оптимально в рассматриваемом выше смысле.
Пример 10.Рассмотрим двоичный линейный (6,3,3) код с порождающей и проверочной матрицами
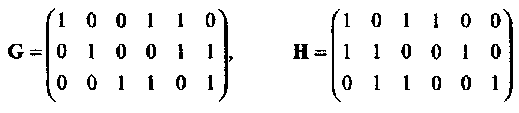
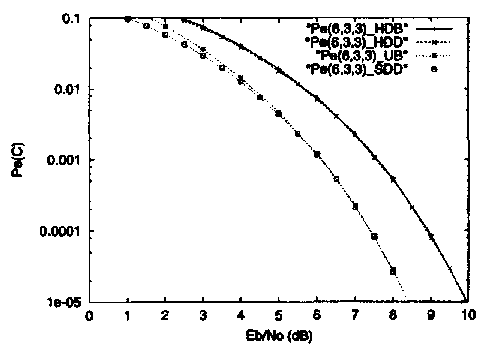
Рис. 10. Моделирование и границы объединения для двоичного (6,3,3) кода при передаче двоичных сигналов в канале с АБГШ.
соответственно. Распределение весов этого кода равно W(C) = {1,0,0,4,3,0,0}, которое может быть проверено непосредственным вычислением для всех кодовых слов v = (u,vp):
| u | vp |
| 000 | 000 |
| 001 | 101 |
| 010 | 011 |
| 011 | 110 |
| 100 | 110 |
| 101 | 011 |
| 110 | 101 |
| 111 | 000 |
В этом частном случае, МП декодирование состоит в вычислении квадрата Евклидова расстояния по формуле (1.33) между принятым словом и каждым из восьми возможных кодовых слов. В качестве решения выбирается слово с наименьшим расстоянием. На Рисунке 10 показаны результаты моделирования и границы объединения для жесткого и мягкого декодирования по максимуму правдоподобия для передачи двоичных сигналов в канале с АБГШ.
Модель канала с общими Релеевскими замираниями.
Другой важной моделью канала является модель с общими Релеевскими замираниями. Замирания сигналов происходят в системах беспроводной связи в виде меняющихся во времени искажений передаваемых сигналов. В этом пособии рассматриваются только общие замирания (flat fading). Термин «общие» (или «гладкие») означает, что канал не является частотно-селективным, т.е. передаточная функция канала в полосе пропускания равна константе.
Модель канала с покомпонентными мультипликативными искажениями показана на Рисунке 11. Мультипликативные искажения представлены случайным вектором α размерности п, компоненты которого являются независимыми, одинаково распределенными случайными величинами (i.i.d.), 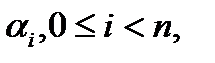 имеющими плотность вероятности Релея,
имеющими плотность вероятности Релея,
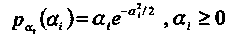 (1.36)
(1.36)
При такой плотности вероятностей множителей среднее значение отношения сигнал-шум (SNR) на бит равно Eb/N0 (как и для АБГШ без замираний), так как второй момент коэффициентов замирания равен E{a2i} = 1.
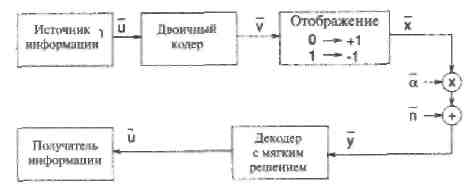
Рис. 11 Передача двоичных кодированных сообщений в канале с гладкими Релеевскими замираниями
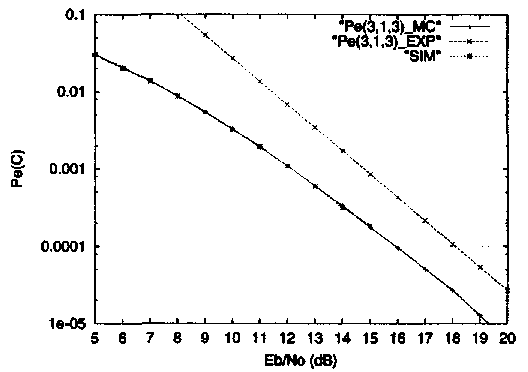
Рис. 12. Двоичная передача по Релеевскому каналу. Результаты моделирования (SIM), оценка границы объединения методом Монте-Карло (Ре(3,1,3)_МС) и граница Чернова (Ре(3,1,3)_ЕХР) для двоичного (3,1,3) кода.
Оценки эффективности двоичных линейных кодов в канале с общими Релеевскими замираниями находятся из оценок условной вероятности ошибки декодирования, Ре(С\α), или условной вероятности ошибки на бит, Рь(С\α). Безусловные вероятности ошибки находятся интегрированием условных вероятностей с весами αi, имеющими плотность вероятности (1.36).
Условные вероятности ошибки идентичны безусловным в канале с АБГШ. Существенное различие имеется только в аргументах функции Q(x), которые теперь взвешены на коэффициенты замирания αi,. Рассматривая передачу двоичных кодированных сообщений при отсутствии (внешней) информации о состоянии канала, находим, что
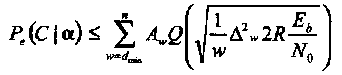 (1.37)
(1.37)
где
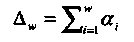 (1.38)
(1.38)
Окончательно, вероятность ошибки декодирования при передаче двоичных сигналов в канале с Релеевскими замираниями получается как математическое ожидание относительно случайной величины ∆w,
 (1.39)
(1.39)
Известны несколько методов оценивания выражения (1.39). Один из них состоит в применении метода Монте-Карло численного интегрирования с использованием следующей аппроксимации:
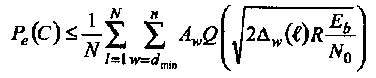 (1.40)
(1.40)
где 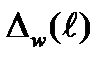 равно сумме квадратов w независимых одинаково распределенных (i.i.d.) случайных величин с Релеевской плотностью вероятностей (1.38), выданных на
равно сумме квадратов w независимых одинаково распределенных (i.i.d.) случайных величин с Релеевской плотностью вероятностей (1.38), выданных на 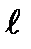 -ом обращении к компьютерной программе генерации, и N достаточно большое целое число, зависящее от ожидаемого диапазона значений Ре(С). Хорошим правилом, которое следует запомнить, является следующее: величина N должна быть, по меньшей мере, в 100 раз больше обратной величины Pe(C).
-ом обращении к компьютерной программе генерации, и N достаточно большое целое число, зависящее от ожидаемого диапазона значений Ре(С). Хорошим правилом, которое следует запомнить, является следующее: величина N должна быть, по меньшей мере, в 100 раз больше обратной величины Pe(C).
Другим методом является экспоненциальная аппроксимация сверху функции Q, которая позволяет проинтегрировать выражение или воспользоваться границей Чернова. Этот подход хоть и несколько ухудшает результат, зато дает замкнутое выражение:
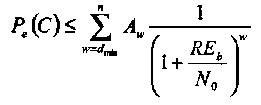 (1.41)
(1.41)

Рис.13. Двоичная передача по Релеевскому каналу. Результаты моделирования (SIM_(6,3,3)),°neHKa границы объединения методом Монте-Карло (Ре(6,3,3)_МС) и граница Чернова (Ре(6,3,3)_ЕХР) для двоичного (6,3,3) кода.
Граница (1.41) полезна в случаях, когда достаточно знать первое приближение в оценке помехоустойчивости кода.
Пример 11.На Рисунке 12 показаны результаты компьютерного моделирования двоичного (3,1,3) кода в канале с общими Релеевскими замираниями. Заметим, что интегрирование методом Монте-Карло дает точное значение помехоустойчивости кода, так как граница (1.40) содержит только один член. Заметим также, что граница Чернова дает результат, смещенный почти на 2дБ, относительно результата моделирования при отношении сигнал-шум на бит Еь/N0>18 дБ,
Пример 12.На Рисунке 13 показаны результаты компьютерного моделирования двоичного (6,3,3) кода из примера 10 в Релеевском канале. В этом случае граница объединения теряет точность при малых значениях Eb/N0 из-за присутствия дополнительных членов в формуле (1.40). Как и раньше, граница Чернова проигрывает около 2 дБ в отношении сигнал - шум на бит при Eb/N0> 18 дБ.
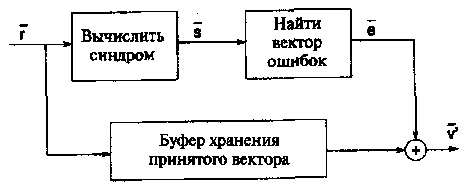
Рис. 14. Общая структура жесткого декодера для линейных блоковых кодов для ДСК.
Вопросы для самоконтроля:
1.5 Общая структура жесткого декодера для линейных кодов
В этом разделе проводится итоговое обсуждение структуры декодера с жестким решением. На Рисунке 14 показана упрощенная блок-схема процесса декодирования. Так как обсуждается жесткое решение, то решения демодулятора поступают на вход декодера, рассчитанного на работу с ДСК.
Обозначим v 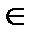 С переданное кодовое слово. На вход декодера подается принятое искаженное слово r = v + е. Процедура декодирования состоит из следующих шагов:
С переданное кодовое слово. На вход декодера подается принятое искаженное слово r = v + е. Процедура декодирования состоит из следующих шагов:
• Вычисляется синдром s = r НT. Согласно свойству линейного кода синдром является линейным преобразованием вектора ошибок, возникшего в канале,
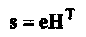 (1-42)
(1-42)
•Для вычисленного синдрома s найти наиболее вероятный вектор ошибок е и вычесть его (по модулю два в двоичном случае) из принятого вектора.
Несмотря на то, что большинство практических декодеров не реализуют процедуру декодирования так, как она сформулирована выше, имеет смысл рассматривать процедуру жесткого декодирования как метод решения уравнения (1.42). Заметим, что любой метод решения этого уравнения является методом декодирования. Например, можно попытаться решать это (ключевое) уравнение с помощью псевдо-обратной матрицы (НT)+ матрицы НT такой, что НТ(НТ)+ = In и для которой результат декодирования
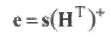 (1.42)
(1.42)
имеет наименьший вес Хемминга. Как легко бы это не казалось, задача эта очень сложна. Мы вернемся к этому соображению при обсуждении методов декодирования кодов БЧХ и Рида-Соломона.
Вопросы для самоконтроля
1. Из каких функциональных блоков состоит функциональная модель канонической цифровой системы передачи информации?
2. Чем понятие кодовая модуляция отличается от понятия помехоустойчивое кодирование?
3. Что понимают под мягким и жёстким способом построения декодера?
4. Имеет ли смысл в одной цифровой системе использовать комбинацию различных кодов исправляющих ошибки?
5. В чём состоит общая идея построения кодов исправляющих ошибки?
6. Что представляет собой кодовое слово систематического блокового кода?
7. В чём разница между блоковыми и сверточными кодами?
8. Поясните смысл понятия минимальное Хеммингово расстояния ?
9. Поясните, какие параметры имеет блоковый код (п, k, dmin).
10. Найдите минимальное Хеммингово расстояние d кода (3,1,d) состоящего из двух кодовых слов (000), (111).
11. Поясните, что называют Хемминговой сферой St(v).
12. Поясните, что понимают под корректирующей способностью t блокового кода.
13. Запишите формулу, по которой можно определить какое максимальное количество ошибок может исправить линейный блоковый код С(n,k,dmin) в неверно принятом слове.
14. Какому принципу должно удовлетворять множество кодовых слов, чтобы код обладал свойством помехоустойчивости?
15. Что такое порождающая матрица?
16. Что такое проверочная матрица?
17. Дайте определение веса Хемминга wtH (x)
18. Из чего состоит систематическая порождающая матрица Gsys линейного блокового кода (n, к, dmin)?
19. Из чего состоит систематическая форма проверочной матрицы Hsys линейного блокового кода (n, к, dmin)?
20. Как от порождающей матрицы G линейного блокового кода (n, к, dmin) перейти к систематической порождающей матрице Gsys этого же кода?
21. Раскройте смысл понятия скорость кода
22. Имеется двоичный линейный (4,2,2) код с порождающей матрицей запишите систематическую порождающую матрицу Gsys?
23. Имеется двоичный линейный (4,2,2) код с порождающей матрицей запишите систематическую проверочную матрицу Hsys?
24. Имеется двоичный линейный (4,2,2) код с порождающей матрицей запишите проверочную матрицу P.
25. Какую матрицу лучше использовать в процессе кодирования с точки зрения минимизации логических операций при скорости кода меньше 0.5.
26. Какую матрицу лучше использовать в процессе кодирования с точки зрения минимизации логических операций при скорости кода больше 0.5.
27. Что представляют собой кодовые слова, если при их создании использовались систематические формы матриц.
28. Имеется двоичный линейный (4,2,2) код с порождающей матрицей запишите кодовое слово соответствующее информационному сообщению (00)?
29. Имеется двоичный линейный (4,2,2) код с порождающей матрицей запишите кодовое слово соответствующее информационному сообщению (01)?
30. Имеется двоичный линейный (4,2,2) код с порождающей матрицей запишите кодовое слово соответствующее информационному сообщению (10)?
31. Имеется двоичный линейный (4,2,2) код с порождающей матрицей запишите кодовое слово соответствующее информационному сообщению (11)?
32. Что называют стандартной таблицей (стандартной расстановкой ) для двоичного линейного (n, k, dmin) кода С?
33. Как найти синдром кодового слова?
34. Имеется двоичный линейный (4,2,2) код с проверочной матрицей запишите значение синдрома, если лидер смежного класса равен 1000?
35. Имеется двоичный линейный (4,2,2) код с проверочной матрицей запишите значение синдрома, если лидер смежного класса равен 0100?
36. Имеется двоичный линейный (4,2,2) код с проверочной матрицей запишите значение синдрома, если лидер смежного класса равен 0001?
37. Имеется двоичный линейный (4,2,2) код с проверочной матрицей запишите значение синдрома, если лидер смежного класса равен 0010?
38. Что понимают под лидером смежного класса?
39. Способен ли код (4,2,2) в принципе исправлять ошибки?
40. Какие коды называют кодами с неравной защитой от ошибок?
41. Чему равно количество слов в столбце стандартной таблицы?
42. Что такое область декодирования кодового слова?
43. Как связаны между собой корректирующая способность t кода С и множество столбцов из стандартной таблицы
44. Как определить число синдромов для линейного блокового кода С (n,k,d)?
45. Сформулируйте правило границы Хемминга
46. Имеется двоичный линейный (3,1,3) код с проверочной матрицей запишите значение синдрома, если лидер смежного класса равен 100?
47. Имеется двоичный линейный (3,1,3) код с проверочной матрицей запишите значение синдрома, если лидер смежного класса равен 010?
48. Имеется двоичный линейный (3,1,3) код с проверочной матрицей запишите значение синдрома, если лидер смежного класса равен 001?
49. Имеется двоичный линейный (3,1,3) код с проверочной матрицей запишите значение синдрома, если лидер смежного класса равен 000?
50. Какие коды называются совершенными?
51. Какие двоичные коды называются кодами Хемминга?
52. Найти распределение весов W(C) для двоичного линейного (4,2,2) кода с набором кодовых слов (0000), (0110), (1011), (1101)?
53. Дайте определение распределения весов W(С) кода С?
54. Чему равна вероятность того, что синдром принятого ненулевого искажённого кода равен нулю?
55. Дан двоичный линейный (6,3,3) код с порождающей матрицей найти кодовые слова соответствующие сообщениям (000) и (001)
56. Дан двоичный линейный (6,3,3) код с порождающей матрицей найти кодовые слова соответствующие сообщениям (010) и (011).
57. Дан двоичный линейный (6,3,3) код с порождающей матрицей найти кодовые слова соответствующие сообщениям (100) и (101)
58. Дан двоичный линейный (6,3,3) код с порождающей матрицей найти кодовые слова соответствующие сообщениям (110) и (111)
59. Вычислить значение синдрома, если лидер класса равен (000001), а порождающая матрица равна
60. Вычислить значение синдрома, если лидер класса равен (000010), а порождающая матрица равна
61. Вычислить значение синдрома, если лидер класса равен (000100), а порождающая матрица равна
62. Вычислить значение синдрома, если лидер класса равен (001000), а порождающая матрица равна
63. Вычислить значение синдрома, если лидер класса равен (010000), а порождающая матрица равна
64. Вычислить значение синдрома, если лидер класса равен (100000), а порождающая матрица равна
65. Найти распределение весов W(C) для кодовой последовательности (000000),(001101), (010011), (011110), (100110), (101011), (110101), (111000)
66. Опишите процедуру декодирования при структуре декодера с жёстким решением и распространением сигнала в канале ДСК
67. Опишите процедуру декодирования при структуре декодера с мягким решением и распространением сигнала в канале АБГШ
ЧАСТЬ 2 КОДЫ ХЕММИНГА, ГОЛЕЯ И РИДА-МАЛЛЕРА
В этой части изучаются важные примеры линейных блоковых кодов. Эти примеры помогут глубже понять принципы исправления ошибок и хорошие алгоритмы декодирования. Коды Хемминга являются, по-видимому, наиболее известным классом блоковых кодов, за исключением, может быть, только кодов Рида-Соломона. Как упоминалось в части 1, коды Хемминга являются оптимальными в том смысле, что они требуют минимальную избыточность при заданной длине блока для исправления одной ошибки. Двоичные коды Голея это единственный нетривиальный пример оптимального кода, исправляющего тройные ошибки (другими примерами оптимальных кодов являются коды-повторения и коды с одной проверкой на четность). Коды Рида-Маллера представляют собой очень элегантную комбинаторную конструкцию с простым декодированием.
2.1. Коды Хемминга
Напомним (формула (1.12)), что любое кодовое слово v линейного (n, k, dmin) кода С удовлетворяет уравнению
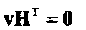 (2.1)
(2.1)
Полезная интерпретация этого уравнения состоит в следующем: максимальное число линейно независимых столбцов проверочной матрицы Н кода С равно dmin - 1.
В двоичном случае, для dmin = 3, из (2.1) следует, что сумма любых двух столбцов проверочной матрицы не равна нулевому вектору. Положим, что столбцы Н являются двоичными векторами длины m. Имеется всего 2m - 1 ненулевых различных столбцов. Следовательно, длина двоичного кода, исправляющего одиночную ошибку, удовлетворяет условию

Это неравенство в точности совпадает с границей Хемминга (1.24) для кода длины п, с п — к= т проверками и исправлением t = 1 ошибок. Соответственно, код, удовлетворяющий этой границе с равенством, известен как код Хемминга.
Пример 13. Для т=3 мы получаем (7,4,3) код Хемминга с проверочной матрицей
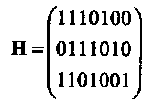
Как уже отмечалось, проверочная матрица кода Хемминга обладает тем свойством, что все ее столбцы различны. Если возникает одиночная ошибка на j-ой позиции, 1≤ j ≤ п, то синдром искаженного принятого слова равен j-ому столбцу матрицы Н. Обозначим евектор ошибок, добавленный к кодовому слову в процессе его передачи по ДСК, и предположим, что все его компоненты равны нулю за исключением j-ой позиции, еj = 1. Тогда синдром принятого слова равен
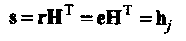 (2.2)
(2.2)
где hj- представляет j-ый столбец Н.
2.1.1. Процедуры кодирования и декодирования
Из уравнения (2.2) следует, что, если столбцы проверочной матрицы рассматривать как двоичное представление целых чисел, то значение синдрома равно номеру искаженной (ошибочной) позиции. Эта идея лежит в основе алгоритмов кодирования и декодирования, представленных ниже. Запишем столбцы проверочной матрицы в виде двоичного представления номера (от 1 до n) позиции кодового слова в возрастающем порядке. Обозначим эту матрицу через Н*. Очевидно, что матрице Н* соответствует эквивалентный код Хемминга с точностью до перестановки позиций кодового слова.
Напомним, что проверочная матрица в систематической форме содержит единичную подматрицу In-kразмера (п - k)× (п - к) как показано в (1.16). Очевидно, что в матрице Н* столбцы единичной подматрицы In-k (т.е. столбцы веса один) размещаются на позициях с номерами, равными степени 2, т.е. 2z z= 0,1,..., т.
Пример 14.Пусть т = 3. Тогда систематическая (каноническая) проверочная матрица может быть задана в следующем виде
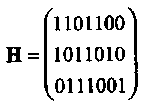
Матрица Н* заданная двоичным представлением целых чисел от 1 до 7 (младший разряд записывается в верхней строке) имеет вид:
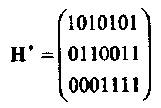
где матрица I3 содержится в столбцах 1, 2 и 4.
В общем случае, для (2m - 1, 2т-1-т) кода Хемминга и данного (арифметического) порядка столбцов единичная матрица Iт содержится в столбцах проверочной матрицы с номерами 1, 2,4,..., 2m-1.
Кодирование
Процедура кодирования следует из уравнения (1.18). При вычислении проверочных символов pj для всех 1 ≤ j ≤ m проверяются номера столбцов и те столбцы, номера которых не являются степенью 2, сопоставляются информационным позициям слова. Соответствующие информационные символы включаются в процесс вычисления проверок. Такая процедура кодирования в чем-то сложнее обычной процедуры для систематического (канонического) кода Хемминга. Однако, соответствующая ей процедура декодирования очень проста. Для некоторых приложений этот подход может оказаться наиболее привлекательным, так как обычно декодирование должно быть очень быстрым.
Декодирование
Если кодирование выполнялось в соответствии с матрицей Н*, то декодирование оказывается очень простым. Синдром (2.2) равен номеру позиции, в которой произошла ошибка! После вычисления синдрома s , который рассматривается как целое число s, ошибка исправляется по правилу
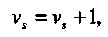 (2.2)
(2.2)
где выполняется сложение по модулю 2 (т.е. 0+0=0, 1 + 1=0, 0+1=1,1+0=1).
Примечание.Следует заметить, что в расширенном толковании оба варианта кода Хемминга в Примере 14 являются систематическими, так как в обоих случаях известен фиксированный набор позиций кодового слова, на которых значения символов кодового слова всегда совпадают с соответствующими информационными символами. Другими словами, любые перестановки символов кодового слова оставляют код систематическим (в расширенном смысле).
Пример 14 интересен еще и тем, что Н*=РН,т.е. проверочной матрице Н*, полученной перестановкой некоторых позиций, соответствует, как оказывается, линейное преобразование исходной матрицы, где преобразующая матрица имеет вид
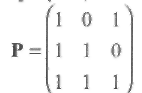
Таким образом, проверочная матрица заданного кода может иметь много различных представлений. Если еНТ = 0, то и еНТPT= 0, где Р любая невырожденная 3×3 матрица. Если еНТ =s, то и eHTPT= sPT =s*. Следовательно, для заданного линейного кода можно найти такое линейное преобразование его проверочной матрицы, которое окажется наиболее удобным для реализации, без каких-либо изменений самого кода. Эта возможность будет использована, например, при декодировании циклических кодов БЧХ.
Из примера 14 следует еще одно свойство линейных кодов. Пользуясь линейным преобразованием проверочной матрицы можно «назначить» проверочными любые ( n - k) позиций кодового слова, если только соответствующие им столбцы матрицы являются линейно независимыми. Это означает, что по оставшимся k позициям можно однозначно восстановить все кодовое слово. Такие наборы позиций называются информационными совокупностями. Множество информационных совокупностей используется в процедурах декодирования под общим названием «ловля ошибок».
2.2. Двоичный код Голея
Голей обнаружил, что
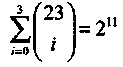
Это равенство позволяет предположить возможность существования совершенного двоичного (23,12, 7) кода с t = 3, т.е. кода, способного исправлять до трех ошибок в словах длиной 23 символа. В своей статье Голей привел порождающую матрицу такого двоичного кода, исправляющего до трех ошибок.
Из-за относительно небольшой длины (23) и размерности (12), а также небольшого числа проверок (11), кодирование и декодирование двоичного (23,12,7) кода Голея может быть выполнено табличным методом.
2.2.1 Кодирование
Табличное (LUT, look-up-table) кодирование реализуется с помощью просмотра таблицы, содержащей список всех 212 = 4096 кодовых слов, которые пронумерованы непосредственно информационными символами. Обозначим и информационный вектор размерности 12 бит и v соответствующее кодовое слово (23 бита). Табличный кодер использует таблицу, в которой для каждого информационного вектора (12 бит) вычислен и записан синдром (11 бит). Синдром берется из таблицы и приписывается справа к информационному вектору.
Операция LUT является взаимно однозначным отображением из множества векторов u на множество векторов v, которое может быть записано в виде
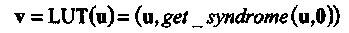 (2.3)
(2.3)
В реализации табличного кодера учтены упрощения, которые следуют из циклической природы кода Голея. Его порождающий полином имеет вид

или в шестнадцатиричной счисления системе С75. Этот полином используется в процедуре "get_syndrome", заданной уравнением (2.3).
2.2.2. Декодирование
Напомним, что задачей декодера (Часть 1, Рисунок 14) является оценка наиболее вероятного (т.е. обладающего минимальным Хемминговым весом) вектора ошибок е по принятому вектору r.
Процедура построения табличного LUT-декодера состоит в следующем:
Выписать все возможные вектора ошибок е, вес Хемминга которых не превышает трех;
Для каждого вектора ошибок вычислить соответствующий синдром s=get_syndrome(e);
Записать в таблицу для каждого значения s соответствующий ему вектор е, так что
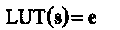
Исправление до трех ошибок в принятом искаженном слове r с помощью LUT-декодера может быть представлено следующим образом:
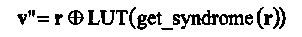
где v" — исправленное кодовое слово.
2.2.3. Арифметическое декодирование расширенного (24,12,8) кода Голея.
В этом разделе рассматривается процедура декодирования расширенного (24,12,8) кода Голея С24, реализующая арифметический алгоритм декодирования. Этот алгоритм использует строки и столбцы подматрицы В проверочной матрицы Н=(В, I12). Заметим, что (24,12,8) код Голея, эквивалентный с точностью до перестановки отдельных позиций коду С24, может быть построен добавлением общей проверки на четность к кодовым словам (23,11,7) кода Голея.
Двенадцать строк подматрицы В, обозначенные как rowi, 1 ≤ i < 12, имеют следующий вид в шестнадцатеричной системе:
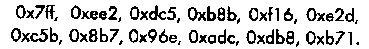
Важно отметить, что подматрица В проверочной матрицы кода С24 удовлетворяет равенству В = Вт, т.е. транспонированная и исходная матрицы совпадают. Это означает, что код С24 является самодуальным кодом. Дуальным кодом называют код, использующий проверочную матрицу исходного кода в качестве порождающей.
В программе golay24.c кодирование реализуется рекуррентно, по правилу (1.18). Как и раньше, через wtH(x) обозначен вес Хемминга вектора х. Процедура декодирования состоит в выполнении следующей последовательности шагов:
1. Вычислить синдром s = rНT.
2. Если wtH(s) ≤ 3, то исправляющий вектор равен е = (s, 0), перейти к шагу 8.
3. Если wtH(s + rowi) ≤ 2, для 1 ≤ i≤ 12, то исправляющий вектор равен е = (s + rowi, хi), где хi вектор длины 12, содержащий 1 в i-ой координате и нули в остальных. Перейти к шагу 8.
4. Вычислить sB.
5. Если wtH(sB) ≤ 3, то исправляющий вектор равен е = (0, sB), перейти к шагу 8.
6. Если wtH(sB + rowi) ≤ 2, для некоторого i, 1 ≤i ≤12, то исправляющий вектор равен е = (хi, sB + rowi), где хi вектор длины 12, содержащий 1 в i-ой координате и нули в остальных. Перейти к шагу 8.
7. Если ни одно из условий шагов 2 - 6 не было удовлетворено, то вектор r содержит неисправимое сочетание ошибок и устанавливается флаг «отказ от декодирования». Конец процедуры.
8. Вычислить с = r + е. Конец процедуры.
Примичание. Эта процедура имеет очень простое объяснение. Кодовое слово длиной 24 символа состоит из информационной части (12) бит и проверочной части (12) бит. Если все ошибки находятся только в проверочной части, то вес синдрома равен числу ошибок. Если этот вес не превышает трех, то декодер принимает на шаге 2 процедуры декодирования однозначное решение о том, что вектор ошибок совпадает с синдромом.
На шаге 3 проверяется предположение о том, что одна (именно одна) ошибка находится на i-ой позиции в информационной части принятого слова. Для правильного выбора i прибавление rowi к синдрому компенсирует вклад этой ошибки в синдром, после чего вес измененного синдрома будет равен 2 или 1. На основании этого декодер принимает однозначное решение о том, что исправляющий вектор равен конкатенации (соединению) вектора xi с измененным синдромом. В противном случае, число ошибок возрастет, вес синдрома не удовлетворит условию. Разумеется, может оказаться, что какое-то другое слово расположено на расстоянии не более 2 от измененного слова при условии, что в принятом слове больше трех ошибок.
На шагах 4—6 процедуры выполняются такие же проверки в предположении, что, либо все ошибки, либо все кроме одной, находятся в информационной части принятого слова. Для этого используется следующее линейное преобразование проверочной матрицы:

которому соответствует преобразование синдрома, равное sB.
Справедливость этого преобразования следует из равенства ВВ = I12, которое легко можно проверить. Другими словами, с помощью этого преобразования, с точки зрения декодера, меняются местами информационные и проверочные позиции кодового слова, хотя никакие изменения с самим кодом не происходят.
Рассмотренная идея использована в некоторых алгоритмах декодирования, близкого к максимуму правдоподобия.
2.3. Двоичные коды Рида-Маллера
Двоичные коды Рида-Маллера (РМ) составляют семейство кодов, исправляющих ошибки, с простым декодированием, основанным на мажоритарной логике. Кроме того, известно, что коды этого семейства имеют очень простые и хорошо структурированные решетки.
Известно элегантное определение двоичных РМ кодов, основанное на двоичных полиномах (или Булевых функциях). Согласно этому определению, РМ коды становятся близкими к кодам БЧХ и PC, которые входят в класс полиномиальных кодов.
2.3.1. Булевы полиномы и РМ коды
Обозначим f(x1, х2,..., хт) Булеву функцию от т двоичных переменных x1, х2,..., хт. Известно, что такие функции легко представить с помощью таблицы истинности. Таблица истинности содержит список значений функции f для всех 2т комбинаций значений ее аргументов. Все обычные Булевы операции (такие как «и», «или») могут быть представлены как Булевы функции.
Пример 15.Рассмотрим функцию f(х1,х2), заданную следующей таблицей истинности:
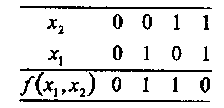
Тогда 
Ассоциируем с каждой Булевой функцией f двоичный вектор f длины 2т, составленный из значений данной функции для всех возможных комбинаций значений т ее аргументов. В последнем примере f=(0110), где принято соглашение о лексикографическом (иначе, арифметическом) упорядочении значений аргументов функции, таком, что x1 представляет младший разряд, a xm- старший разряд.
Заметим, что Булева функция может быть записана прямо по таблице истинности с помощью дизъюнктивной нормальной формы (ДНФ). В терминах ДНФ любая Булева функция может быть записана как сумма 2m элементарных функций: 1, х1, х2, …xm, x1 х2,..., х1хm,..., х1х2..хm такой что
 (2.4)
(2.4)
где вектор 1 добавлен для того, чтобы учесть свободный член (степени 0). В примере 15 f=x1+x2.
Двоичный (2т, k, 2т-r) РМ код, обозначенный РМr,m, определяется как множество векторов, ассоциированных со всеми Булевыми функциями степени до r, включительно, от mпеременных. Код PMr,m называют также кодом РМ r-ого порядка длины 2т. Размерность РМr,m кода, как легко может быть показано, равна
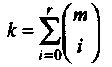
Это число равно числу способов, которыми могут быть построены полиномы степени rили меньше от mпеременных.
С учетом уравнения (2.4) строками порождающей матрицы РМr,m кода являются вектора, ассоциированные с kБулевыми функциями, которые могут быть записаны как полиномы степени rили меньше от m переменных.
Пример 16.Код РМ первого порядка длины 8, PM1,3, является двоичным (8,4,4) кодом, который может быть построен из Булевых функций степени 1 от 3 переменных: {1, х1, х2, х3}.Таким образом,
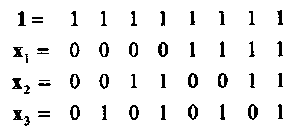
Порождающая матрица РМ1,3 кода имеет, следовательно, вид
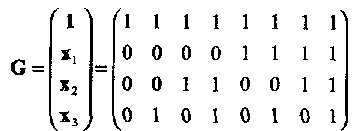 (2.5)
(2.5)
Заметим, что код PM1,3 может быть построен также и из кода Хемминга (7,4,3) добавлением общей проверки на четность. Расширенный код Хемминга и РМ1,3 код могут отличаться только порядком позиций (столбцов).
Дуальные коды кодов РМ также являются кодами РМ
Можно показать, что РМm-r-1, т код дуален коду PM r,m. Другими словами, порождающая матрица РМm-r-1,ткода может быть использована как проверочная матрица PM r,m кода.
2.3.2. Конечные геометрии и мажоритарное декодирование.
Определение кодов РМ может быть дано и в терминах конечных геометрии. Евклидова геометрия, EG(m,2), размерности т над GF(2) содержит 2т точек, которые представляют собой все двоичные вектора длины т. Заметим, что столбцы матрицы, образованной последними тремя строками порождающей матрицы PM1,3 кода, см. Пример 16, представляют собой 8 точек EG(3,2). Удалением нулевой точки это множество точек преобразуется в проективную геометрию PG(m-1,2). Коды над конечными геометриями являются по существу обобщением кодов РМ.
Связь между кодами и конечными геометриями можно объяснить следующим образом. Возьмем EG(m,2). Столбцы матрицы (xT1 , хт2 … хтm)т (где Т - операция транспонирования матрицы) рассматриваются как координаты точек геометрии EG(m,2). Тогда имеет место взаимно однозначное соответствие между компонентами двоичного вектора длины 2т и точками EG(m,2). Заданный двоичный вектор длины 2т ассоциируется с подмножеством точек EG(m,2). В частности, подмножество EG(m,2) может быть ассоциировано с двоичным вектором w = (w1 , w2, …, wn) длины п=2т, если интерпретировать значение его координат wi =1 как выбор точки. Другими словами, w является вектором инцидентности (совпадений).
Теперь двоичный код Рида-Маллера можно определить следующим образом: кодовыми словами PMr,m кода являются вектора инцидентности всех подпространств (т.е. линейных комбинаций точек) размерности т-r в EG(m,2) Из этого определения следует, что число кодовых слов минимального веса РМr,m кода равно
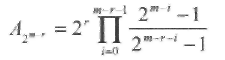 (2.6)
(2.6)
Код, который получается после удаления (перфорации) координат, соответствующих условию х1 = х2 = ... = хm = 0, из всех кодовых слов PМr,m кода является двоичным циклическим РМ*r,m кодом. Число слов минимального веса циклического РМ кода равно
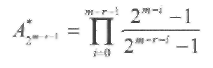 (2.7)
(2.7)
Декодирование РМ кодов может быть выполнено на основе мажоритарной логики (МЛ). Идея мажоритарного декодирования состоит в следующем. Как известно, проверочная матрица порождает 2п-к проверочных уравнений. Построение МЛ декодера сводится к выбору такого подмножества проверочных уравнений, чтобы решение о значении кодового символа на определенной позиции формировалось по большинству «голосов», причем каждый «голос» связан с одним из проверочных уравнений. В качестве иллюстрации рассмотрим код РМ1,3 из Примера 16.
Пример 17.Пусть вектор 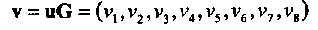 является кодовым словом кода PM1,3. Как уже упоминалось ранее, выражение (2.5) определяет порождающую, а также и проверочную матрицу PM1,3 кода, поскольку в данном случае r= 1 и m-r-1=1 и, следовательно, код является самодуальным. Все возможные ненулевые линейные комбинации (всего 15) проверочных уравнений (строк проверочной матрицы Н) имеют вид:
является кодовым словом кода PM1,3. Как уже упоминалось ранее, выражение (2.5) определяет порождающую, а также и проверочную матрицу PM1,3 кода, поскольку в данном случае r= 1 и m-r-1=1 и, следовательно, код является самодуальным. Все возможные ненулевые линейные комбинации (всего 15) проверочных уравнений (строк проверочной матрицы Н) имеют вид:
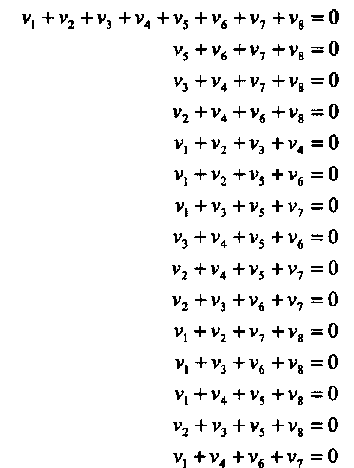 (2.8)
(2.8)
Читателю предлагается проверить, что сумма vi + vj любой пары кодовых символов vi и vjпоявляется точно в четырех уравнениях. Более того, в уравнениях, которые содержат одинаковую сумму (vi + vj), любые другие суммы пар появляются не более одного раза (т.е. не более чем в одном уравнении). Такие проверочные уравнения называют ортогональными относительно пары символов vi и vj.
Покажем теперь способ исправления одиночной ошибки. Пусть в результате передачи кодового слова v по ДСК получен вектор
r = v + e = ( r1, r2, r3, r4, r5, r6, r7, r8)
Предположим, что ошибка, которая должна быть исправлена, находится в v5. Построим процедуру мажоритарного декодирования для данного случая.
Выберем два уравнения, включающие сумму vi + v5, i≠ 5, и два других уравнения, содержащие сумму vj+ v5, j≠5 , i≠j. Примем, например, i = 3 и j = 4. Имеется четыре проверки ортогональные сумме v3 + v5. Выберем любые две из них. Выполним тоже самое для суммы v4 + v5. Ассоциированные с выбранными проверками синдромы обозначим S1 и S2 для суммы v3 + v5, а также S3 и S4 для суммы v4 + v5. В результате имеем:
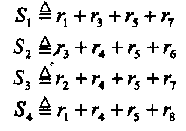 (2.9)
(2.9)
Так как вектор v является кодовым словом PM1,3 кода, то система уравнений (2.9) эквивалентна следующей
 (2.10)
(2.10)
Поскольку проверки S1 S2, S3, S4 ортогональны относительно е3 + е5 и е4 +e5 , то может быть построена новая пара уравнений ортогональных относительно е5.
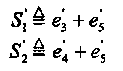 (2.11)
(2.11)
где e'j, j = 3, 4, 5, представляют мажоритарные оценки, полученные из уравнений (2.9). Уравнения (2.11) ортогональны относительно е'5 и, следовательно, значение е'5 может быть получено голосованием. Например, в данном случае это может быть результат операции «И» с входами S’1 и S'2
Предположим, что передавалось слово v = (111 10000) и было принято слово r = (11111000). Тогда из (2.10) получаем
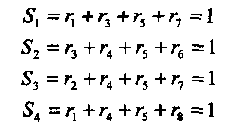 (2.12)
(2.12)
Таким образом, оба терма е3 + e5 и е4 + е5 оцениваются равными «1». Из (2.11) получаем оценку е5 = 1 и оценку исправляющего вектора е = (00001000). Окончательно, оценка переданного слова равна v = r + е = (11110000). Таким образом, продемонстрирован двух шаговый способ мажоритарного исправления одной ошибки на пятой позиции.
В предыдущем примере было показано, как исправляется одна ошибка в заданной позиции для кода PM1,3 Аналогичная процедура может быть применена к любой позиции принятого слова. Следовательно, могут быть получены и все восемь мажоритарных оценок для каждого символа.
В общем случае код РМr,m может быть декодирован (r + 1) -шаговой мажоритарной процедурой декодирования с исправлением любой из возможных комбинаций случайных ошибок веса |_(2m - 2 - 1) / 2_| или меньше .
Дополнительно заметим, что циклический код РМ*r,m декодируется несколько проще. В циклическом коде С, если (v1, v2,..., vn) любое кодовое слово, то и его циклический сдвиг (vn, v1, ... , vn-1) тоже кодовое слово. Отсюда следует, что, если некоторая позиция может быть декодирована по мажоритарному методу, то и все n позиций будут декодированы тем же самым способом с использованием циклического сдвига.
Пример 18. В этом примере рассматривается декодер циклического PM*1,3 кода, который совпадает с двоичным (7,4,3) кодом Хемминга. Для того, чтобы получить проверочные уравнения циклического кода из проверок PM1,3 кода, достаточно удалить во всех уравнениях координату v1, для которой x1 = х2 =...= хm. После удаления v1 изменим нумерацию позиций PM*1,3 кода следующим образом:
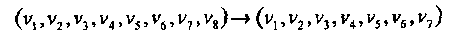
Как и раньше, можно построить мажоритарный декодер для произвольной позиции (например, пятой), учитывая семь линейно независимых проверочных уравнений:
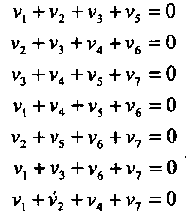 (2.13)
(2.13)
По аналогии с предыдущим примером находим, что синдромы S1 и S2 ортогональны относительно символов v4 и v5, а S2 и S3 ортогональны относительно v5 и v6:
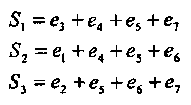 (2.14)
(2.14)
Используя промежуточные оценки сумм v4 + v5 и v5 + v6, получаем дополнительно два ортогональных уравнения относительно v5:
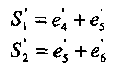 (2.15)
(2.15)
где e'j, j = 4, 5, 6, обозначены мажоритарные оценки, полученные на предыдущем шаге. Этот алгоритм представлен на Рисунке 15 в виде логической схемы.
Эта схема работает следующим образом. Начальное состояние семи ячеек регистра памяти устанавливается нулевым. Предположим, что принятое слово содержит ошибку в позиции с номером i, 1 ≤ i ≤ 7. На каждом такте содержимое регистра памяти сдвигается вправо на одну позицию. Время в тактах представлено на схеме нижним индексом.
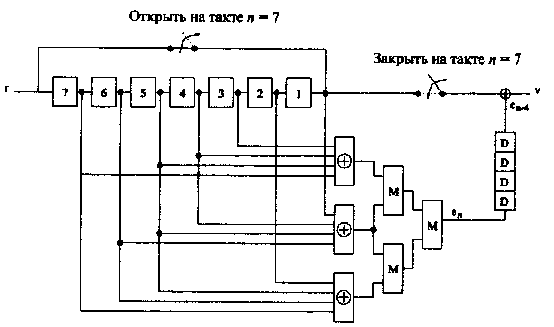
Рис. 15.Мажоритарный декодер циклического кода РМ*(1,3)
Рассмотрим случай i = 1. Это означает, что ошибка находится в первой позиции принятого слова. Через три такта эта ошибка переместится в пятую ячейку регистра (v5). Выход мажоритарной логической схемы примет состояние еп = 1. Еще через четыре такта (на седьмом такте) первый принятый символ попадет на выход декодера и будет исправлен. Рассмотрим теперь случай i = 7. Через девять тактов ошибка будет обнаружена и выход мажоритарной схемы примет значение еп = 1. Спустя четыре такта (т.е. на тринадцатом такте) последний символ поступит на выход декодера и будет исправлен. Декодер, который здесь рассматривается, имеет задержку 13 тактов. Через 13 тактов содержимое регистра стирается и начинается обработка нового принятого слова.
В следующей части рассматриваются циклические коды и обширное семейство БЧХ кодов.
Вопросы для самоконтроля
Какие коды называются самодуальными?
Запишите параметры (n,k,d) двоичного кода Голея.
Что значит понятие систематический код в расширенном смысле?
Дата добавления: 2018-02-18; просмотров: 3384; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!