Проектирование лексического анализатора
Содержание
| Введение......................................................................................................... | 2 |
| 1. Организация таблицы идентификаторов................................................. | 3 |
| 1.1. Исходные данные................................................................................. | 3 |
| 1.2. Назначение таблиц идентификаторов............................................... | 3 |
| 1.3. Метод простого рехэширования........................................................ | 5 |
| 1.4. Метод цепочек..................................................................................... | 7 |
| 1.5. Результаты............................................................................................ | 9 |
| 2. Проектирование лексического анализатора............................................ | 11 |
| 2.1. Исходные данные................................................................................. | 11 |
| 2.2. Принципы работы лексического анализатора.................................. | 12 |
| 2.3. Схема распознавателя......................................................................... | 13 |
| 2.4. Результаты............................................................................................ | 14 |
| 3. Проектирование синтаксического анализатора...................................... | 16 |
| 3.1. Исходные данные................................................................................. | 16 |
| 3.2. Построение синтаксического анализатора........................................ | 16 |
| 3.3. Результаты............................................................................................ | 20 |
| Заключение..................................................................................................... | 22 |
| Список использованной литературы........................................................... | 23 |
| Приложение А - Исходный текст программы............................................ | 24 |
| Приложение Б - Граф состояний лексического анализатора.................... | 34 |
| Приложение В - Матрица операторного предшествования...................... | 36 |
|
|
|
Введение
Компилятор – программный модуль, задачей которого является перевод программы, написанной на одном из языков программирования (исходный язык) в программу на языке ассемблера или языке машинных команд.
Целью данной курсовой работы является изучение составных частей, основных принципов построения и функционирования компилятора, практическое освоение методов построения составных частей компилятора для заданного входного языка.
Курсовая работа заключается в реализации отдельных фаз компиляции заданного языка.
В первой части работы требуется разработать программный модуль, который получает на входе набор идентификаторов, организует таблицу идентификаторов по заданным методам и позволяет осуществить многократный поиск идентификатора в этой таблице. Программа должна подсчитывать число коллизий и среднее количество сравнений, выполняемых для поиска идентификатора.
Во второй части работы требуется разработать программный модуль, выполняющий лексический анализ входного текста по заданной грамматике и порождающий таблицу лексем с указанием их типов.
|
|
|
В третьей части работы требуется разработать программу, которая на основании таблицы лексем выполняет синтаксический разбор текста по заданной грамматике с построением цепочки вывода и дерева разбора.
В качестве среды разработки для реализации приложения использован язык программирования Delphi 7 и система программирования Borland Delphi 7.
Организация таблицы идентификаторов
Исходные данные
На входе имеется набор идентификаторов, которые организуются в таблицу идентификаторов по одному из двух методов:
1. Простое рехэширование.
2. Метод цепочек.
Должна быть предусмотрена возможность осуществления многократного поиска идентификатора в этой таблице. Список идентификаторов задан в виде текстового файла. Длина идентификатора ограничена 32 символами.
Требуется, чтобы программа подсчитывала число коллизий и среднее количество сравнений, выполняемых при поиске идентификатора.
Назначение таблиц идентификаторов
Проверка правильности семантики и генерация кода требуют знания характеристик идентификаторов, используемых в программе на исходном языке. Эти характеристики выясняются из описаний и из того, как идентификаторы используются в программе и накапливаются в таблице символов, или таблице идентификаторов. Любая таблица идентификаторов состоит из набора полей, количество которых равно числу идентификаторов программы. Каждое поле содержит в себе полную информацию о данном элементе таблицы. Под идентификаторами подразумеваются константы, переменные, имена процедур и функций, формальные и фактические параметры.
|
|
|
В данной работе сравниваются два метода организации таблицы идентификаторов: метод простого рехэширования и метод цепочек.
Данные методы основаны на хеш-адресации, то есть на использовании значения, возвращаемого хеш-функцией, в качестве адреса ячейки из некоторо-
го массива данных. Хеш-функция вычисляется путем выполнения над цепочкой символов некоторых простых арифметических и логических операций. Самой простой хеш-функцией для символа является ASCII-код символа.
В данной курсовой работе принята хэш-функция - сумма ASCII-кодов первых двух символов цепочки.
При хэш-адресаци возможна ситуация, когда двум или более идентификаторам соответствует одно и то же значение хэш-функции. Такая ситуация называется коллизией. Сравниваемые в данной работе методы организации таблицы идентификаторов - простого рехэширования и метод цепочек - отличаются по способу разрешения коллизий. Ниже каждый метод рассмотрен подробнее.
|
|
|
Метод простого рехэширования
Согласно данному методу, если для элемента А адрес п() = h(A),указывает на уже занятую ячейку, то есть в случае возникновения коллизии, необходимо вычислить значение функции n1 = h1(A) и проверить занятость ячейки по адресу n1. Если и она занята, то вычисляется значение h2(A). И так до тех пор, пока либо не будет найдена свободная ячейка, либо очередное значение hi(A) не совпадет с h(A). В последнем случае считается, что таблица идентификаторов заполнена и места в ней больше нет - выдается сообщение об ошибке размещения идентификатора в таблице.
Согласно методу простого рехэширования, hi(A) = (h(A)+i) mod Nm, где Nm- максимальное значение хэш-функции.
В данной курсовой работе принята хэш-функция - сумма ASCII-кодов первых двух символов цепочки, максимальное значение хэш-функции равно 512.
Поскольку при заполнении таблицы идентификаторов основными операциями являются добавление элемента в таблицу и поиск элемента в ней, на рис. 1 и рис. 2 представлены блок-схемы этих операций для рассматриваемого метода.
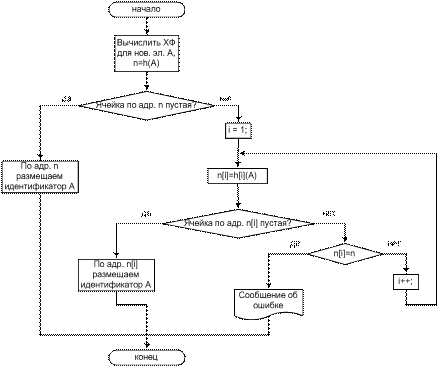
Рис. 1. Блок-схема добавления элемента в таблицу идентификаторов по методу простого рехэширования

Рис. 2. Блок-схема алгоритма поиска элемента в таблице идентификаторов, организованной по методу простого рехэширования
Метод цепочек
Согласно данному методу, хэш-функция вычисляет адрес, по которому происходит обращение сначала к хеш-таблице, а затем через нее по найденному адресу — к таблице идентификаторов. В таблицу идентификаторов для каждого элемента добавляется поле, в котором может содержаться ссылка на любой элемент таблицы. В случае возникновения коллизии алгоритм размещает элементы в ячейках таблицы, связывая их друг с другом последовательно через поле ссылки.
Поскольку при заполнении таблицы идентификаторов основными операциями являются добавление элемента в таблицу и поиск элемента в ней, на рис. 3 и рис. 4 представлены блок-схемы этих операций для рассматриваемого метода.

Рис. 3. Блок-схема добавления элемента в таблицу идентификаторов по методу цепочек

Рис. 4. Блок-схема алгоритма поиска элемента в таблицу идентифиикаторов, организованной по методу цепочек
Результаты
Для сравнения метода простого рехэширования и метода цепочек выбран текстовый файл, содержащий 100 строк.
В результате работы программы получены следующие данные, которые представлены в табл. 1.
Таблица 1
| Метод простого рехэширования | Метод цепочек | |
| Коллизий | 74 | 59 |
| Сравнений | 19 | 3 |
| Среднее число сравнений | 0,19 | 0,03 |
На основе полученных результатов можно сделать следующие выводы.
Недостатки метода простого рехэширования:
- элементы могут попадать в ячейки с адресами, которые потом будут совпадать со значениями хеш-функции, что приводит к возникновению дополнительных коллизий;
- среднее время на размещение элемента и на поиск элемента в таблице зависит от заполненности таблицы идентификаторов и качества используемой хеш-функции;
- требование неполного заполнения таблицы ведет к неэффективному использованию объема доступной памяти.
Достоинством метода простого рехэширования является то, что он позволяет добиться неплохих результатов для эффективного поиска элемента в таблице (лучших, чем метод бинарного дерева).
Достоинства метода цепочек:
- нет необходимости заполнять пустыми значениями таблицу идентификаторов (это можно сделать только для хеш-таблицы), то есть память используется более экономно;
- элементы не могут попадать в ячейки с адресами, которые потом будут совпадать со значениями хеш-функции, то есть дополнительные коллизии не будут возникать;
- среднее время на размещение элемента и на поиск элемента в таблице зависит только от среднего числа коллизий, возникающих при вычислении хеш-функции.
Недостатком метода цепочек является необходимость организации работы с динамическими массивами данных.
Метод цепочек является более эффективным методом организации таблицы идентификаторов. Именно он и будет в дальнейшем использован для хранения информации об идентификаторах в курсовой работе.
Проектирование лексического анализатора
Исходные данные
Для выполнения данной части курсовой работы требуется написать программу, которая выполняет лексический анализ входного текста в соответствии с заданием и порождает таблицу лексем с указанием их типов и значений. Текст на входном языке задан в виде текстового файла. Программа должна выдавать сообщения о наличие во входном тексте ошибок, которые могут быть обнаружены на этапе лексического анализа. Программа должна допускать наличие комментариев неограниченной длины во входном файле.
В соответствии с заданием должны распознаваться:
- ключевые слова : «prog», «end.», «begin», «end», «if», «then», «else», «for», «to», «downto», «do», «and», «or», «not»;
- идентификаторы: любые последовательности латинских символов и цифр; идентификатор должен начинаться с символа;
- константы: двоичное представление числа;
- знаки операций: «=», «<», «>», «–», «+», «*», «/»;
- оператор присваивания: «:=»;
- разделитель: «;»;
- комментарии, заключенные в «{», «}».
Дата добавления: 2018-02-15; просмотров: 1477; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!