Адресация элементов с помощью векторов Айлиффа
Векторы
Логическая структура.
Вектор (одномерный массив) - структура данных с фиксированным числом элементов одного и того же типа типа. Каждый элемент вектора имеет уникальный в рамках заданного вектора номер. Обращение к элементу вектора выполняется по имени вектора и номеру требуемого элемента.
Машинное представление. Адресация элементов структур.
Элементы вектора размещаются в памяти в подряд расположенных ячейках памяти. Под элемент вектора выделяется количество байт памяти, определяемое базовым типом элемента этого вектора. Необходимое число байтов памяти для хранения одного элемента вектора называется слотом. Размер памяти для хранения вектора определяется произведением длины слота на число элементов.
В языках программирования вектор представляется одномерным массивом с синтаксисом описания вида (PASCAL):
< Имя > : array [n..k] of < тип >;
где n-номер первого элемента, k-номер последнего элемента. Представление в памяти вектора будет такое, как показано на рис. 3.1.
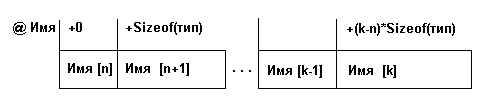
Рис. 1.1. Представление вектора в памяти
где @ Имя -адрес вектора или, что тоже самое, адрес первого элемента вектора,
Sizeof(тип)-размер слота (количество байтов памяти для записи одного элемента вектора), (k-n)*Sizeof(тип) - относительный адрес элемента с номером k, или, что тоже самое, смещение элемента с номером k.
Например:
var m1:array[-2..2] of real;
представление данного вектора в памяти будет как на рис. 3.2.
|
|
|
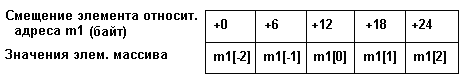
Рис. 1.2. Представление вектора m1 в памяти
В языках, где память распределяется до выполнения программы на этапе компиляции (C, PASCAL, FORTRAN), при описании типа вектора граничные значения индексов должны определены. В языках, где память может распределяться динамически (ALGOL, PL/1), значения индексов могут быть заданы во время выполнения программы.
Количество байтов непрерывной области памяти, занятых одновременно вектором, определяется по формуле:
ByteSise = ( k - n + 1 ) * Sizeof (тип)
Обращение к i-тому элементу вектора выполняется по адресу вектора плюс смещение к данному элементу. Смещение i-ого элемента вектора определяется по формуле:
ByteNumer = ( i- n ) * Sizeof (тип),
а адрес его: @ ByteNumber = @ имя + ByteNumber.
где @ имя - адрес первого элемента вектора.
Например:
var МAS: array [ 5..10 ] of word.
Базовый тип элемента вектора - Word требует 2 байта, поэтому на каждый элемент вектора выделяется по два байта. Тогда таблица 3.1 смещений элементов вектора относительно @Mas выглядит так:
| Смещение (байт) | + 0 | + 2 | + 4 | + 6 | + 8 | + 10 |
| Идентификатор поля | MAS[5] | MAS[6] | MAS[7] | MAS[8] | MAS[9] | MAS[10] |
Таблица 1.1
Этот вектор будет занимать в памяти: (10-5+1)*2 = 12 байт.
Смещение к элементу вектора с номером 8: (8-5)*2 = 6
Адрес элемента с номером 8: @ MAS + 6.
|
|
|
При доступе к вектору задается имя вектора и номер элемента вектора. Таким образом, адрес i-го элемента может быть вычислен как:
@Имя[i] = @Имя + i*Sizeof(тип) - n*Sizeof(тип) (3.1)
Это вычисление не может быть выполнено на этапе компиляции, так как значение переменной i в это время еще неизвестно. Следовательно, вычисление адреса элемента должно производиться на этапе выполнения программы при каждом обращении к элементу вектора. Но для этого на этапе выполнения, во-первых, должны быть известны параметры формулы (3.1): @Имя Sizeof(тип), n, а во-вторых, при каждом обращении должны выполняться две операции умножения и две - сложения. Преобразовав формулу (3.1) в формулу (3.2),
@Имя[i] = A0 + i*Sizeof(тип) -- (3.2)
A0 = @Имя - n*Sizeof(тип) --
сократим число хранимых параметров до двух, а число операций - до одного умножения и одного сложения, так как значение A0 может быть вычислено на этапе компиляции и сохранено вместе с Sizeof(тип) в дескрипторе вектора. Обычно в дескрипторе вектора сохраняются и граничные значения индексов. При каждом обращении к элементу вектора заданное значение сравнивается с граничными и программа аварийно завершается, если заданный индекс выходит за допустимые пределы.
|
|
|
Таким образом, информация, содержащаяся в дескрипторе вектора, позволяет, во-первых, сократить время доступа, а во-вторых, обеспечивает проверку правильности обращения. Но за эти преимущества приходится платить, во-первых, быстродействием, так как обращения к дескриптору - это команды, во-вторых, памятью как для размещения самого дескриптора, так и команд, с ним работающих.
Можно ли обойтись без дескриптора вектора?
В языке C, например, дескриптор вектора отсутствует, точнее, не сохраняется на этапе выполнения. Индексация массивов в C обязательно начинается с нуля. Компилятор каждое обращение к элементу массива заменяет на последовательность команд, реализующую частный случай формулы (3.1) при n = 0:
@Имя[i] = @Имя + i*Sizeof(тип)
Программисты, привыкшие работать на C, часто вместо выражения вида: Имя[i] употребляют выражение вида: *(Имя+i).
Но во-первых, ограничение в выборе начального индекса само по себе может являться неудобством для программиста, во-вторых, отсутствие граничных значений индексов делает невозможным контроль выхода за пределы массива. Программисты, работающие с C, хорошо знают, что именно такие ошибки часто являются причиной "зависания" C-программы при ее отладке.
|
|
|
Массивы
Логическая структура
Массив - такая структура данных, которая характеризуется:
- фиксированным набором элементов одного и того же типа;
- каждый элемент имеет уникальный набор значений индексов;
- количество индексов определяют мерность массива, например, два индекса - двумерный массив, три индекса - трехмерный массив, один индекс - одномерный массив или вектор;
- обращение к элементу массива выполняется по имени массива и значениям индексов для данного элемента.
Другое определение: массив - это вектор, каждый элемент которого - вектор.
Синтаксис описания массива представляется в виде:
< Имя > : Array [n1..k1] [n2..k2] .. [nn..kn] of < Тип >.
Для случая двумерного массива:
Mas2D : Array [n1..k1] [n2..k2] of < Тип >, или
Mas2D : Array [n1..k1 , n2..k2] of < Тип >
Наглядно двумерный массив можно представить в виде таблицы из (k1-n1+1) строк и (k2-n2+1) столбцов.
Физическая структура
Физическая структура - это размещение элементов массива в памяти ЭВМ. Для случая двумерного массива, состоящего из (k1-n1+1) строк и (k2-n2+1) столбцов физическая структура представлена на рис. 3.3.
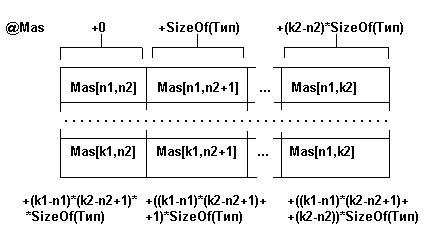
Рис. 1.3. Физическая структура двумерного массива из (k1-n1+1) строк и (k2-n2+1) столбцов
Многомерные массивы хранятся в непрерывной области памяти. Размер слота определяется базовым типом элемента массива. Количество элементов массива и размер слота определяют размер памяти для хранения массива. Принцип распределения элементов массива в памяти определен языком программирования. Так в FORTRAN элементы распределяются по столбцам - так, что быстрее меняется левые индексы, в PASCAL - по строкам - изменение индексов выполняется в направлении справа налево.
Количество байтов памяти, занятых двумерным массивом, определяется по формуле :
ByteSize = (k1-n1+1)*(k2-n2+1)*SizeOf(Тип)
Адресом массива является адрес первого байта начального компонента массива. Смещение к элементу массива Mas[i1,i2] определяется по формуле:
ByteNumber = [(i1-n1)*(k2-n2+1)+(i2-n2)]*SizeOf(Тип)
его адрес : @ByteNumber = @mas + ByteNumber.
Например:
var Mas : Array [3..5] [7..8] of Word;
Базовый тип элемента Word требует два байта памяти, тогда таблица 3.2 смещений элементов массива относительно @Mas будет следующей:
| Смещение (байт) | Идентификатор поля | Смещение (байт) | Идентификатор поля |
| + 0 | Mas[3,7] | + 2 | Mas[3,8] |
| + 4 | Mas[4,7] | +6 | Mas[4,8] |
| + 8 | Mas[5,7] | + 10 | Mas[5,8] |
Таблица 1.2
Этот массив будет занимать в памяти: (5-3+1)*(8-7+1)*2=12 байт; а адрес элемента Mas[4,8]:
@Mas+((4-3)*(8-7+1)+(8-7)*2 = @Mas+6
Операции
Важнейшая операция физического уровня над массивом - доступ к заданному элементу. Как только реализован доступ к элементу, над ним может быть выполнена любая операция, имеющая смысл для того типа данных, которому соответствует элемент. Преобразование логической структуры в физическую называется процессом линеаризации, в ходе которого многомерная логическая структура массива преобразуется в одномерную физическую структуру.
В соответствии с формулами (3.3), (3.4) и по аналогии с вектором (3.1), (3.2) для двумерного массива c границами изменения индексов:
[B(1)..E(1)][B(2)..E(2)], размещенного в памяти по строкам, адрес элемента с индексами [I(1),I(2)] может быть вычислен как:
Addr[I(1),I(2)] = Addr[B(1),B(2)] +
{ [I(1)-B(1)] * [E(2)-B(2)+1] + [I(2)-B(2)] }*SizeOf(Тип) (3.5)
Обобщая (3.5) для массива произвольной размерности:
Mas[B(1)..E(2)][B(2)..E(2)]...[B(n)..E(n)]
получим:
Addr[I(1),I(2),...,I(n)] = Addr[B(1),B(2),...B(n)] -
n n (3.6)
- Sizeof(Тип)*СУММА[B(m)*D(m)] + Sizeof(Тип)*СУММА[I(m)*D(m)]
m=1 m=1
где Dm зависит от способа размещения массива. При размещении по строкам:
D(m)=[E(m+1)-B(m+1)+1]*D(m+1), где m = n-1,...,1 и D(n)=1
при размещении по столбцам:
D(m)=[E(m-1)-B(m-1)+1]*D(m-1), где m = 2,...,n и D(1)=1
При вычислении адреса элемента наиболее сложным является вычисление третьей составляющей формулы (3.6), т.к. первые две не зависят от индексов и могут быть вычислены заранее. Для ускорения вычислений множители D(m) также могут быть вычислены заранее и сохраняться в дескрипторе массива. Дескриптор массива, таким образом, содержит:
- начальный адрес массива - Addr[I(1),I(2),...,I(n)];
- число измерений в массиве - n;
- постоянную составляющую формулы линеаризации (первые две составляющие формулы (3.6);
- для каждого из n измерений массива:
- значения граничных индексов - B(i), E(i);
- множитель формулы линеаризации - D(i).
Одно из определений массива гласит, что это вектор, каждый элемент которого - вектор. Некоторые языки программирования позволяют выделить из многомерного массива одно или несколько измерений и рассматривать их как массив меньшей мерности.
Например, если в PL/1-программе объявлен двумерный массив:
DECLARE A(10,10) BINARY FIXED;
то выражение: A[*,I] - будет обращаться к одномерному массиву, состоящему из элементов: A(1,I), A(2,I),...,A(10,I).
Символ-джокер "*" означает, что выбираются все элементы массива по тому измерению, которому соответствует заданный джокером индекс. Использование джокера позволяет также задавать групповые операции над всеми элементами массива или над выбранным его измерением,
например: A(*,I) = A(*,I) + 1
К операциям логического уровня над массивами необходимо отнести такие как сортировка массива, поиск элемента по ключу. Наиболее распространенные алгоритмы поиска и сортировок будут рассмотрены в данной главе ниже.
Адресация элементов с помощью векторов Айлиффа
Из выше приведенных формул видно, что вычисление адреса элемента многомерного массива может потребовать много времени, поскольку при этом должны выполняться операции сложения и умножения, число которых пропорционально размерности массива. Операцию умножения можно исключить, если применять следующий метод.
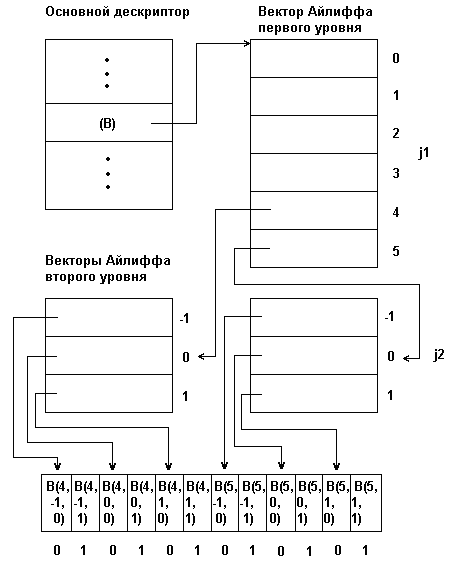
Рис. 1.4. Представление массивов с помощью векторов Айлиффа
Для массива любой мерности формируется набор дескрипторов: основного и несколько уровней вспомогательных дескрипторов, называемых векторами Айлиффа. Каждый вектор Айлиффа определЯнного уровня содержит указатель на нулевые компоненты векторов Айлиффа следующего, более низкого уровня, а векторы Айлиффа самого нижнего уровня содержат указатели групп элементов отображаемого масси- ва. Основной дескриптор массива хранит указатель вектора Айлиффа первого уровня. При такой организации к произвольному элементу В(j1,j2,...,jn) многомерного массива можно обратиться пройдя по цепочке от основного дескриптора через соответствующие компоненты векторов Айлиффа.
На рис. 3.4 приведена физическая структура трЯхмерного массива В[4..5,-1..1,0..1], представленная по методу Айлиффа. Из этого рисунка видно, что метод Айлиффа, увеличивая скорость доступа к элементам массива, приводит в то же время к увеличению суммарного объЯма памяти, требуемого для представления массива. В этом заключается основной недостаток представления массивов с по- мощью векторов Айлиффа.
Специальные массивы
На практике встречаются массивы, которые в силу определенных причин могут записываться в память не полностью, а частично. Это особенно актуально для массивов настолько больших размеров, что для их хранения в полном объеме памяти может быть недостаточно. К таким массивам относятся симметричные и разреженные массивы.
Симметричные массивы.
Двумерный массив, в котором количество строк равно количеству столбцов называется квадратной матрицей. Квадратная матрица, у которой элементы, расположенные симметрично относительно главной диагонали, попарно равны друг другу, называется симметричной. Если матрица порядка n симметрична, то в ее физической структуре достаточно отобразить не n^2, а лишь n*(n+1)/2 еЯ элементов. Иными словами, в памяти необходимо представить только верхний (включая и диагональ) треугольник квадратной логической структуры. Доступ к треугольному массиву организуется таким образом, чтобы можно было обращаться к любому элементу исходной логической структуры, в том числе и к элементам, значения которых хотя и не представлены в памяти, но могут быть определены на основе значений симметричных им элементов.
На практике для работы с симметричной матрицей разрабатываются процедуры для:
а) преобразования индексов матрицы в индекс вектора,
б) формирования вектора и записи в него элементов верхнего треугольника элементов исходной матрицы,
в) получения значения элемента матрицы из ее упакованного представления. При таком подходе обращение к элементам исходной матрицы выполняется опосредованно, через указанные функции.
В приложении приведен пример программы для работы с симметричной матрицей.
Разреженные массивы.
Разреженный массив - массив, большинство элементов которого равны между собой, так что хранить в памяти достаточно лишь небольшое число значений отличных от основного (фонового) значения остальных элементов.
Различают два типа разреженных массивов:
- 1) массивы, в которых местоположения элементов со значениями отличными от фонового, могут быть математически описаны;
- 2) массивы со случайным расположением элементов.
В случае работы с разреженными массивами вопросы размещения их в памяти реализуются на логическом уровне с учетом их типа.
Дата добавления: 2018-02-15; просмотров: 949; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!