Приведем оценку эффективности приведенного на предыдущем шаге алгоритма построения дерева.
Алгоритмы построения бинарного дерева.
Приведем нерекурсивный алгоритм построения дерева поиска. В процессе изложения будет разъяснено, какими свойствами должно обладать бинарное дерево, чтобы быть деревом поиска.
Обозначим Tree - указатель на корень дерева.
Tree = NULL; //Построение пустого дерева.
Обозначим p - вспомогательный указатель на вершину дерева.
1. Пусть ключ первой, поступающей в дерево, вершины равен 100. Создаем первую вершину:
p = new(node);
(*p).Key = 100; (*p).Count = 1;
(*p).Left = NULL; (*p).Right = NULL;
Tree = p;

Рис.1. Создание первой вершины
2. Пусть ключ второй, поступающей в дерево, вершины равен 50. Выполняем следующие операции:
вначале создаем новую вершину:
p = new(node);
(*p).Key = 50; (*p).Count = 1;
(*p).Left = NULL; (*p).Right = NULL;

Рис.2. Создание новой вершины
так как 100>50, то по определению бинарного дерева поиска мы должны сделать вновь поступившую вершину левым сыном корня дерева:
(*Tree).Left = p;
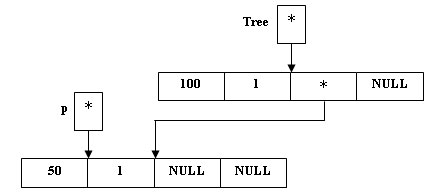
Рис.3. Размещение вершины в левом поддереве
3. Пусть ключ третьей вершины, поступающей в дерево, равен 200. Порядок наших действий:
создаем новую вершину:
p = new(node);
(*p).Key = 200; (*p).Count = 1;
(*p).Left = NULL; (*p).Right = NULL;
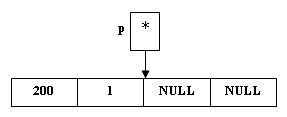
Рис.4. Создание новой вершины
так как 200>100, то по определению бинарного дерева поиска, мы должны сделать вновь поступившую вершину правым сыном корня дерева:
(*Tree).Right = p;

Рис.5. Размещение вершины в правом поддереве
Осталось определить, как же нам действовать в случае поступления, например, в дерево вновь вершины с ключом 100. Оказывается, что поле Count и применяется для учета повторяющихся ключей!
|
|
|
Точнее, в этом случае выполняется оператор присваивания (*Tree).Count = (*Tree).Count + 1;, результат выполнения которого изобразим на схеме:

Рис.6. Размещение вершины с ранее встречавшимся ключом
Таким образом, последовательное поступление вершин с ключами 100, 50, 200, 100 приведет к созданию структуры данных - бинарного дерева поиска.
Разумеется, написание алгоритма построения дерева поиска с использованием рекурсии или даже просто разбор рекурсивного алгоритма, написанного кем-то другим, далеко не простая задача; она требует большого опыта. Поэтому, мы приводим без комментариев рекурсивную реализацию алгоритма построения дерева))):
void BuildTree (node **Tree)// Построение бинарного дерева. // *Tree - указатель на корень дерева.{ int el; *Tree = NULL; // Построено пустое бинарное дерево. cout<<"Вводите ключи вершин дерева...\n"; cin>>el; while (el!=0) { Search (el,Tree); cin>>el;}}void Search (int x, node **p)// Поиск вершины с ключом x в дереве со вставкой // (рекурсивный алгоритм). // *p - указатель на корень дерева.{ if (*p==NULL) { // Вершины с ключом x в дереве нет; включить ее. *p = new(node);(**p).Key = x; (**p).Count = 1; (**p).Left = (**p).Right = NULL; } else //Поиск места включения вершины. if (x<(**p).Key) //Включение в левое поддерево. Search (x,&((**p).Left)); else if (x>(**p).Key) //Включение в правое поддерево. Search (x,&((**p).Right)); else (**p).Count = (**p).Count + 1;}Замечание! Методы поиска по динамическим таблицам часто называют алгоритмами таблиц символов, так как компиляторы и другие системные программы обычно используют их для хранения определяемых пользователем символов.
|
|
|
Приведем оценку эффективности приведенного на предыдущем шаге алгоритма построения дерева.
Как пишет H. Вирт: "Довольно естественно испытывать некоторое недоверие к алгоритму поиска по дереву с включениями... Прежде всего многих программистов беспокоит то, что обычно мы не знаем, каким образом будет расти дерево, и не имеем никакого представления о форме, которую оно примет".
Теоpема Хопкpофта-Ульмана.
Сpеднее число сpавнений, необходимых для вставки n случайных элементов в деpево поиска, пустое вначале, pавно O(nlog2n) для n>=1.
Доказательству теоремы предпошлём лемму.
Лемма.
Дата добавления: 2021-07-19; просмотров: 125; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!