МОДЕЛИРОВАНИЕ ПРОЦЕССА ЛЕКСИЧЕСКОГО АНАЛИЗАТОРА.
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РФ
ФГБОУ ВО РОСТОВСКИЙ ГОСУДАРСТВЕННЫЙ ЭКОНОМИЧЕСКИЙ УНИВЕРСИТЕТ (РИНХ)
Институт Магистратуры РГЭУ (РИНХ)
Кафедра «Информационных технологий и защиты информации»
КУРСОВОЙ ПРОЕКТ
По дисциплине «Средства разработки и проектирования компонент операционных систем»
Тема: «Построение лексического анализатора»
Автор курсового проекта: Коновской А. О.
Группа: 821-ПРИ
Направление: Программная инженерия
Руководитель проекта: А.С. Родионов
Ростов – на – Дону
2020
СОДЕРЖАНИЕ
Введение…………………………………………………………………………………3
ЛЕКСИЧЕСКИЙ АНАЛИЗАТОР. ТЕОРИЯ…………………… …………………….4
Роль лексического анализатора……………………………………………………...…4
Токены, шаблоны и лексемы………………………………………………………...…8
Лексические ошибки…………………………………………………………………..10
|
|
|
Словарь определений……………………………………………………………….…11
МОДЕЛИРОВАНИЕ ПРОЦЕССА ЛЕКСИЧЕСКОГО АНАЛИЗАТОРА………......13
ПРОЕКТИРОВАНИЕ ЛЕКСИЧЕСКОГО АНАЛИЗАТОРА………………...............23
Заключение……………………………………………………………………….…….32
Библиографический список…………………………………………………………...33
Введение
Первой фазой процесса компиляции является лексический анализ, т.е. группирование строк литер, обозначающих идентификаторы, константы или слова языка и т. д., в единые символы. Конечно, в однопроходных компиляторах этот процесс идет параллельно с другими фазами компиляции. Однако независимо от того, составляет ли лексический анализ отдельную фазу компиляции, при описании конструкции компилятора, а также его построении удобно представлять себе лексический анализ как самостоятельную фазу. В настоящей главе мы рассмотрим, как распознаются различные символы, и опишем таблицы, которые лексический анализатор должен построить для себя и для последующих фаз компилятора.
Мы рассмотрим создание лексического анализатора. Для реализации лексического анализатора вручную стоит начать с диаграммы или иного описания лексем каждого токена. Затем можно написать код, который будет идентифицировать каждую встреченную во входном потоке лексему и возвращать информацию об обнаруженном токене.
|
|
|
Можно также получить лексический анализатор автоматически, определив шаблоны лексем для генератора лексических анализаторов и компилируя их в код, функционирующий в качестве лексического анализатора. Данный подход упрощает внесение изменений в лексический анализатор, поскольку для этого требуется переписать только измененные шаблоны, но не весь код программы. Он также ускоряет процесс реализации лексического анализатора, поскольку программист при этом работает только с очень высокоуровневыми шаблонами, а детальный код получается в результате работы генератора лексических
анализаторов.
Изучение генераторов лексических анализаторов начнется с регулярных выражений, удобной записи для определения шаблонов лексем. Будет рассмотрено, как преобразовать эту запись сначала в недетерминированный, а затем в детерминированный автомат. Последние две записи могут использоваться в качестве входных данных для "драйвера", т.е. кода, который имитирует работу этих автоматов и использует их в качестве руководства для определения следующего токена во входном потоке. Этот драйвер и спецификация автомата образуют ядро лексического анализатора.
|
|
|
ЛЕКСИЧЕСКИЙ АНАЛИЗАТОР. ТЕОРИЯ.
Роль лексического анализатора
Первая фаза компиляции называется лексическим анализом или сканированием. Лексический анализатор читает поток символов, составляющих исходную программу, и группирует эти символы в значащие последовательности, называющиеся лексемами.
С теоретической точки зрения лексический анализатор не является обязательной, необходимой частью компилятора. Его функции могут выполняться на этапе синтаксического разбора. Однако существует несколько причин, исходя из которых, в состав практически всех компиляторов включают лексический анализ:
· упрощается работа с текстом исходной программы на этапе синтаксического разбора и сокращается объем обрабатываемой информации, так как лексический анализатор структурирует поступающий на вход исходный текст программы и выкидывает всю незначащую информацию;
· для выделения в тексте и разбора лексем возможно применять простую, эффективную и теоретически хорошо проработанную технику анализа, в то время как на этапе синтаксического анализа конструкций исходного языка используются достаточно сложные алгоритмы разбора;
|
|
|
· сканер отделяет сложный по конструкции синтаксический анализатор от работы непосредственно с текстом исходный программы, структура которого может варьироваться в зависимости от версии входного языка – при такой конструкции компилятора при переходе от одной версии языка к другой достаточно только перестроить относительно простой сканер.
Функции, выполняемые лексическим анализатором, и состав лексем, которые он выделяет в тексте исходной программы, могут меняться в зависимости от версии компилятора. В основном лексические анализаторы выполняют исключение из текста исходной программы комментариев и незначащих пробелов, а также выделение лексем следующих типов: идентификаторов, строковых, символьных и числовых констант, ключевых (служебных) слов входного языка.
В большинстве компиляторов лексический и синтаксический анализаторы – это взаимосвязанные части. Лексический разбор исходного текста в таком варианте выполняется поэтапно так, что синтаксический анализатор, выполнив разбор очередной конструкции языка, обращается к сканеру за следующей лексемой. При этом он может сообщить информацию о том, какую лексему следует ожидать. В процессе разбора может даже происходить «откат назад», чтобы выполнить анализ текста на другой основе. В дальнейшем будем исходить из предположения, что все лексемы могут быть однозначно выделены сканером на этапе лексического разбора.
Работу синтаксического и лексического анализаторов можно изобразить в виде схемы, приведенной на рис.1.
Обычно взаимодействие реализуется как вызов лексического анализатора синтаксически анализатором. Этот вызов, представленный как команда getNextToken, заставляет лексический анализатор читать символы из входного потока, пока он не сможет идентифицировать очередную лексему и вернуть синтаксическому анализатору корректный токен.
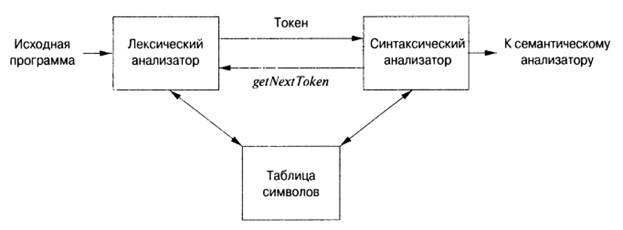
Рисунок 1 – Взаимодействие лексического анализатора с синтаксическим.
Поскольку лексический анализатор является частью компилятора, которая читает исходный текст, он может заодно выполнять и некоторые другие действия, помимо идентификации лексем. Одной из таких задач является отбрасывание комментариев и пробельных символов (пробел, символы табуляции и новой строки, а также, возможно, некоторые другие символы, использующиеся для отделения токенов друг от друга во входном потоке). Еще одной задачей является синхронизация сообщений об ошибках, генерируемых компилятором, с исходной программой. Например, лексический анализатор может отслеживать количество символов новой строки, чтобы каждое сообщение об ошибке сопровождалось номером строки, в которой она обнаружена. В некоторых компиляторах лексический анализатор создает копию исходной программы с сообщениями об ошибках, вставленными в соответствующие места исходного текста. Если исходная программа использует макропрепроцессор, то раскрытие макросов также может выполняться лексическим анализатором. Иногда лексические анализаторы разделяются на соединенные каскадом два процесса.
а) Сканирование состоит из простых процессов, не требующих токенизации входного потока, таких как удаление комментариев и уплотнение последовательностей пробельных символов в один.
б) Собственно лексический анализ — более сложная часть, которая генерирует токены из выходного потока сканера.
В простейшем случае фазы лексического и синтаксического анализа могут выполняться компилятором последовательно. Но для многих языков программирования информации на этапе лексического анализа может быть недостаточно для однозначного определения типа и границ очередной лексемы.
Иллюстрацией такого случая может служить пример оператора присваивания из языка программирования Си++:
k = i+++++j;
Который имеет только одну верную интерпретацию (если операции разделить пробелами):
k = i++ + ++j;
Если невозможно определить границы лексем, то лексический анализ исходного текста должен выполняться поэтапно. Тогда лексический и синтаксический анализаторы должны функционировать параллельно, поочередно обращаясь друг к другу. Лексический анализатор, найдя очередную лексему, передает ее синтаксическому анализатору, тот пытается выполнить анализ считанной части исходной программы и может либо запросить у лексического анализатора следующую лексему, либо потребовать от него вернуться на несколько шагов назад и попробовать выделить лексемы с другими границами.
Очевидно, что параллельная работа лексического и синтаксического анализаторов более сложна в реализации, чем их последовательное выполнение. Кроме того, такая реализация требует больше вычислительных ресурсов и в общем случае большего времени на анализ исходной программы.
Чтобы избежать параллельной работы лексического и синтаксического анализаторов, разработчики компиляторов и языков программирования часто идут на разумные ограничения синтаксиса входного языка. Например, для языка Си++ принято соглашение, что при возникновении проблем с определением границ лексемы всегда выбирается лексема максимально возможной длины. Для рассмотренного выше оператора присваивания это приводит к тому, что при чтении четвертого знака + из двух вариантов лексем (+ – знак сложения, ++ – оператор инкремента) лексический анализатор выбирает самую длинную, т.е. ++, и в целом весь оператор будет разобран как k = i++ +++j;, что неверно. Любые неоднозначности при анализе данного оператора присваивания могут быть исключены только в случае правильной расстановки пробелов в исходной программе.
Вид представления информации после выполнения лексического анализа целиком зависит от конструкции компилятора. Но в общем виде ее можно представить как таблицу лексем, которая в каждой строчке должна содержать информацию о виде лексемы, ее типе и, возможно, значении. Обычно такая таблица имеет два столбца: первый – строка лексемы, второй – указатель на информацию о лексеме, может быть включен и третий столбец – тип лексем. Не следует путать таблицу лексем и таблицу идентификаторов – это две принципиально разные таблицы! Таблица лексем содержит весь текст исходной программы, обработанный лексическим анализатором. В нее входят все возможные типы лексем, при этом, любая лексема может в ней встречаться любое число раз. Таблица идентификаторов содержит только следующие типы лексем: идентификаторы и константы. В нее не попадают ключевые слова входного языка, знаки операций и разделители. Каждая лексема в таблице идентификаторов может встречаться только один раз.
Вот пример фрагмента текста программы на языке Паскаль и соответствующей ему таблицы лексем:
...
begin
for i:=1 to N do
fg := fg * 0.5
...
Таблица 1 – Таблица лексем программы.
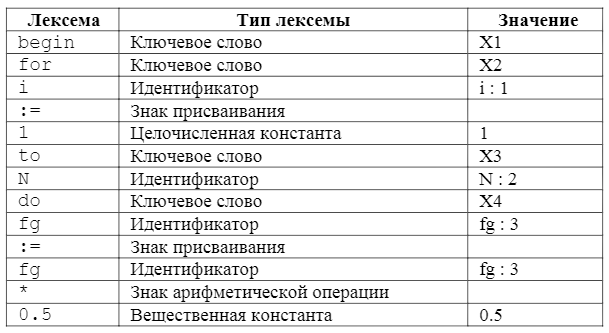
В этой таблице поле «значение» подразумевает некое кодовое значение, которое будет помещено в итоговую таблицу лексем. Значения, приведенные в примере, являются условными. Конкретные коды выбираются разработчиками при реализации компилятора. Связь между таблицей лексем и таблицей идентификаторов отражена в примере некоторым индексом, следующим после идентификатора за знаком «:». В реальном компиляторе эта связь определяется его реализацией.
Токены, шаблоны и лексемы
Токен представляет собой пару, состоящую из имени токена и необязательного атрибута. Имя токена — это абстрактный символ, представляющий тип лексической единицы, например конкретное ключевое слово или последовательность входных символов, составляющую идентификатор. Имена токенов являются входными символами, обрабатываемыми синтаксическим анализатором. Далее обычно мы будем записывать имя токена полужирным шрифтом и ссылаться на токен по его имени.
• Шаблон (pattern) — это описание вида, который может принимать лексема токена. В случае ключевого слова шаблон представляет собой просто последовательность символов, образующих это ключевое слово. Для идентификаторов и некоторых других токенов шаблон представляет собой более сложную структуру, которой соответствуют (matched) многие строки.
• Лексема представляет собой последовательность символов исходной программы, которая соответствует шаблону токена и идентифицируется лексическим анализатором как экземпляр токена.
На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического анализа и разбора. Для каждой лексемы анализатор строит выходной токен (token) вида:
‹имя_токена, значение_атрибута›
Он передается последующей фазе, синтаксическому анализу. Первый компонент токена, имя_токена, представляет собой абстрактный символ, использующийся во время синтаксического анализа, а второй компонент, значение атрибута, указывает на запись в таблице символов, соответствующую данному токену. Информация из записи в таблице символов необходима для семантического анализа и генерации кода.
Предположим, например, что исходная программа содержит инструкцию присваивания:
position = initial + rate * 60
Символы в этом присваивании могут быть сгруппированы в следующие лексемы и отображены в следующие токены, передаваемые синтаксическому анализатору.
1. Position представляет собой лексему, которая может отображаться в токен (id 1) где id – абстрактный символ, обозначающий идентификатор, а 1 указывает запись в таблице символов для position. Запись таблицы символов для некоторого идентификатора хранит информацию о нем, такую как его имя и тип.
2. Символ присваивания = представляет собой лексему, которая отображается в токен (=). Поскольку этот токен не требует значения атрибута, второй компонент данного токена опущен. В качестве имени токена может быть использован любой абстрактный символ, например такой, как assign, но для удобства записи в качестве имени абстрактного символа можно использовать саму лексему.
3. Initial представляет собой лексему, которая отображается в токен (id 2) где 2 указывает на запись в таблице символов для initial.
4. + является лексемой, отображаемой в токен (+).
5. Rate – лексема, отображаемая в токен (id 3) где 3 указывает на запись в таблице символов для rate.
6. * – лексема, отображаемая в токен *.
7. 60 – лексема, отображаемая в токен (number 4) где 4 указывает на запись таблицы символов для внутреннего представления целого числа 60.
Пробелы, разделяющие лексемы, лексическим анализатором отбрасываются.
Представление инструкции присваивания после лексического анализа в виде последовательности токенов:
(id, 1) (=) (id, 2) (+) (id, 3) (*) (number, 4)
При этом представлении имена токенов =, + и * представляют собой абстрактные символы для операторов присваивания, сложения и умножения соответственно.
В таблице 1 приведены некоторые типичные токены, неформальное описание их шаблонов и некоторые примеры лексем. Чтобы увидеть использование этих концепций на практике, в инструкции на языке программирования С:
printf("Total = %d\n", score);
“Printf” и “score” представляют собой лексемы, соответствующие токену id, a "Total = %d\n" является лексемой, соответствующей токену literal.
Таблица 2 – Примеры токенов.

Во многих языках программирования описанные далее ситуации охватывают большинство (если не все) токенов.
1. По одному токену для каждого ключевого слова. Шаблон для ключевого слова выглядит так же, как само ключевое слово.
2. Токены для операторов, либо отдельные, либо объединенные в классы, как это сделано в случае токена comparison
3. Один токен, представляющий идентификаторы.
4. Один или несколько токенов, представляющих константы, такие как числа и строковые литералы.
5. Токены для каждого символа пунктуации, такие как левые и правые скобки,
запятые или точки с запятыми.
Лексические ошибки
Без помощи других компонентов компилятора лексическому анализатору сложно обнаружить ошибки в исходном тексте программы. Например, если в программе на языке С строка f i впервые встретится в контексте
fi ( а == f(x)) …
лексический анализатор не сможет определить, что именно представляет собой f i — неверно записанное слово if или необъявленный идентификатор функции. Поскольку f i является корректной лексемой для токена id, лексический анализатор должен вернуть этот токен синтаксическому анализатору и позволить другой фазе компилятора — в данном случае, по всей видимости, синтаксическому анализатору — обработать ошибку перестановки местами двух букв.
Однако представим ситуацию, когда лексический анализатор не способен продолжать работу, поскольку ни один из шаблонов не соответствует префиксу оставшегося входного потока. Простейшей стратегией в этой ситуации будет восстановление в "режиме паники". Мы просто удаляем входные символы до тех пор, пока лексический анализатор не встретит распознаваемый токен в начале оставшейся входной строки. Этот метод восстановления может запутать синтаксический анализатор, но для интерактивной среды данная методика может быть вполне и адекватной.
Существуют и другие возможные действия по восстановлению после ошибки.
1. Удаление одного символа из оставшегося входного потока.
2. Вставка пропущенного символа в оставшийся входной поток.
3. Замена символа другим.
4. Перестановка двух соседних символов.
Преобразования наподобие перечисленных пытаются исправить входной поток. Простейшая стратегия исправления состоит в выяснении, не может ли префикс оставшейся входной строки быть преобразован в корректную лексему при помощи одного действия. Такая стратегия имеет смысл, поскольку на практике большинство лексических ошибок вызываются единственным символом. Более глобальная стратегия состоит в поиске наименьшего количества трансформаций, необходимых для преобразования исходной программы в программу, состоящую только из корректных лексем, но на практике это слишком дорогой подход, не оправдывающий затрачиваемых усилий.
Словарь определений
Токены. Лексический анализатор сканирует исходную программу и выдает последовательность токенов, которая обычно передается синтаксическому анализатору по одному токену. Некоторые токены состоят из одного имени токена, в то время как другие могут иметь связанное с ними лексическое значение, несущее информацию о конкретном экземпляре токена, и найденном во входном потоке.
♦ Лексемы. Каждый раз, когда лексический анализатор возвращает синтаксическому анализатору токен, с последним связана его лексема — последовательность входных символов, которую представляет токен.
♦ Буферизация. Поскольку зачастую для того, чтобы увидеть, где заканчивается очередная лексема, требуется опережающее сканирование входного потока (предпросмотр), лексический анализатор должен буферизовать входной поток. Две методики, ускоряющие процесс сканирования и входного потока — циклическое использование пары буферов с применением ограничителей, которые предупреждают о достижении конца буфера.
♦ Шаблоны. Каждый токен имеет шаблон, который описывает, какая последовательность символов может формировать лексему, соответствующую этому токену. Множество слов, или строк символов, которые соответствуют данному шаблону, называется языком.
Регулярные выражения. Эти выражения обычно используются для описания шаблонов. Регулярные выражения строятся из отдельных символов с использованием операторов объединения, конкатенации и замыкания Клини.
♦ Регулярные определения. Для определения сложных наборов языков, таких как шаблоны, описывающие токены языка программирования, часто используются регулярные определения, которые представляют собой последовательности инструкций, в которых регулярным выражениям сопоставляются обозначающие их переменные. Регулярное выражение для некоторой переменной может использовать ранее определенные переменные для других регулярных выражений.
♦ Расширенная запись регулярных выражений. В регулярных выражениях для упрощения может использоваться ряд дополнительных операторов, представляющих собой сокращения имеющихся регулярных выражений. Примерами таких операторов могут служить оператор (одно или несколько вхождений), ? (нуль или одно вхождение), а также классы символов.
♦ Диаграммы переходов. Поведение лексического анализатора часто можно описать с использованием диаграмм переходов. Эти диаграммы включают состояния, каждое из которых представляет определенную историю просмотренных входных символов в процессе поиска текущей лексемы, соответствующей одному из возможных шаблонов. Из одних состояний в другие ведут стрелки, или переходы, каждая из которых соответствует некоторому возможному входному символу, приводящему к изменению состояния лексического анализатора.
♦ Конечные автоматы. Существует формализация диаграмм переходов, которая включает указание одного начального и одного или нескольких принимающих состояний, а также множества состояний, входных символов и переходов между состояниями. Принимающие состояния указывают, что найдена лексема для некоторого токена. В отличие от диаграмм переходов конечные автоматы могут осуществлять переходы как для входных символов, так и для пустой входной строки.
♦ Детерминированные конечные автоматы. ДКА представляет собой специальный вид конечного автомата, у которого из каждого состояния для каждого входного символа имеется ровно один переход. Кроме того, запрещены переходы для пустых строк. ДКА легко моделируются и обеспечивают хорошую реализацию лексических анализаторов, аналогичную диаграммам переходов.
♦ Недетерминированные конечные автоматы. Автомат, не являющийся детерминированным, называется недетерминированным. НКА часто существенно проще спроектировать, чем ДКА. Еще одной возможной архитектурой лексического анализатора является табуляция для каждого возможного шаблона всех состояний НКА, в которых он может оказаться при сканировании входного потока.
♦ Преобразования представлений шаблонов. Можно преобразовать любое регулярное выражение в НКА примерно того же размера, распознающий определяемый этим регулярным выражением язык. Далее, любой НКА может быть преобразован в ДКА для того же шаблона, хотя в наихудшем случае (не встречающемся при работе с обычными языками программирования) размер ДКА может экспоненциально зависеть от размера НКА. Можно также преобразовать любой недетерминированный или детерминированный конечный автомат в регулярное выражение, которое определяет тот же язык, что и распознаваемый этим автоматом.
МОДЕЛИРОВАНИЕ ПРОЦЕССА ЛЕКСИЧЕСКОГО АНАЛИЗАТОРА.
Спроектировать лексический анализатор языка программирования Java. Сам программный продукт должен быть выполнен на языке программирования C#. Должны проверяться следующие лексемы:
· Числовые константы.
· Типы данных:
1) Целочисленные.
2) Вещественные.
· Массивы и элементы массивов.
· Арифметические операторы.
· Операции сравнения.
· Описание данных.
· Операторы условного и безусловного перехода.
· Метки.
Составим классы лексем Java (таблица 3).
Таблица 3 – Классы лексем
| Тип | Обозначение |
| Константы целочисленные | С |
| Константы с плавающей точкой | Z |
| Тип данных | T |
| Идентификаторы | I |
| Арифметические операторы | A |
| Операторы | S |
| Разделитель | R |
| Ключевые слова | K |
В языке программирования Java числовые константы представляются в виде:
Таблица 4 – Числовые константы в языке программирования Java.
| Десятичные | Последовательность цифр (0 — 9), которая начинаются с цифры, отличной от нуля. Пример: 1, -29, 385. Исключение — число 0. | C1 |
Таблица 5 – Числовые константы с плавающей точкой в языке Java
| Знак | Порядок | Мантисса | Сдвиг | |
| 32 bit Float | 1 бит [31] | 8 бит [30-23] | 23+1 бит [22-0] | -127 |
| 64 bit double | 1 бит [63] | 11 бит [62-52] | 52+1 бит [51-0] | -1023 |
Лексический анализатор должен определять все числовые константы. Он должен отличать константы от чисел в имени переменной.
Целочисленные типы данных в Java (таблица 6):
Таблица 6 – Целочисленные типы данных в Java.
| Имя | Токен |
| Byte | 1 |
| Short | 2 |
| Int | 3 |
| Long | 4 |
Типы данных с плавающей точкой в Java (таблица 7).
Таблица 7 – Типы данных с плавающей точкой.
| Имя | Токен |
| Double | 5 |
| Float | 6 |
Таблица 8 – Ссылочный тип данных
| Имя | Токен |
| Scanner | 7 |
Имеют вид:
1)Имя Список переменных;
2)Имя переменная = числовая константа;
В языке программирования Java массивы представлены в виде:
Тип_данных переменная [размер массива] = [константа] ….
Тип_данных переменная [размер массива] [размер массива] = [константа][константа] [константа][константа] [константа][константа]….
Лексический анализатор должен определять типы переменных и типы массивов. Определять является ли переменная массивом и считывает каждый элемент массива.
Арифметические операции в Java (таблица 9):
Таблица 9 – Арифметические операции в Java.
| Cимвол | Токен | Неформальное описание |
| + | 1 | Сложение |
| - | 2 | Вычитание |
| * | 3 | Умножение |
| / | 4 | Деление |
| % | 5 | Деление с остатком |
Операторы условного и безусловного перехода в Java имеют вид:
break
for(int i = 0; i < 100; i++) {
if(i == 5) break; // выходим из цикла, если i равно 5
mInfoTextView.append("i: " + i + "\n");
}
mInfoTextView.append("Цикл завершён");
Continue
for (int i = 0; i < 10; i++) {
mInfoTextView.append(i + " ");
if (i % 2 == 0)
continue;
mInfoTextView.append("\n");
}
return
Оператор return используют для выполнения явного выхода из метода. Оператор можно использовать в любом месте метода для возврата управления тому объекту, который вызвал данный метод. Таким образом, return прекращает выполнение метода, в котором он находится.
Таблица 10 – Операторы
| Имя | Токен | Неформальное описание |
| > | 1 | Больше чем |
| < | 2 | Меньше чем |
| <= | 3 | Меньше или равно |
| >= | 4 | Больше или равно |
| == | 5 | Равно |
| = | 0 | Присвоить |
| println | 6 | Ввод |
| out | 7 | Ввывод |
| break | 8 | Безусловные |
| Continue | 9 | |
| return | 10 | |
| Goto | 11 | |
| if | 12 | Условные |
| else | 13 |
Таблица 11 – Разделители
| Разделитель | Код |
| пробел | 1 |
| , | 2 |
| ; | 3 |
| ( | 4 |
| ) | 5 |
| . | 6 |
| { | 7 |
| } | 8 |
| “ | 9 |
| ” | 10 |
| конец строки | 11 |
Таблица 12 – Ключевые (служебные) слова
| Имя | Токен |
| public | 1 |
| main | 2 |
| class | 3 |
| new | 4 |
| System | 5 |
| nextDouble | 6 |
| String | 7 |
| import | 8 |
| java | 9 |
| util | 10 |
При лексическом разборе входной цепочки пробелы не кодируются как разделители и в выходную цепочку не попадают. Это связано с тем, что в исходном тексте программы пробелы служат только для структурирования текста программы и не несут дополнительной смысловой нагрузки.
Рассмотрим работу сканера на примере исходной программы, представленной ниже:
import java.util.Scanner;
public class main {
public static void main(String[] args) {
int a = 10;
Scanner in = new Scanner(System.in);
double b = in.nextDouble();
String text = "Больше";
String text1 = "Меньше";
if ( a > b ) {
System.out.println(text);
}
if( a < b) {
System.out.println(text1);
}
if (a == b){
System.out.println("=");
} } }
Спроектируем лексический анализатор. Для этого построим блок-схемы будущего приложения (блок-схемы 1 - 3). В таблицах приведены токены, которые будет видеть выдавать лексический анализатор.
Каждая обработанная лексема преобразуется к виду:
<буква><код>
где: <буква> – это признак класса лексемы
<код> – номер лексемы в соответствующей таблице.
на выходе сканера будет сформирована следующая последовательность
кодов лексем:
Для данной исходной программы лексический анализатор сформирует следующую выходную последовательность лексем (таблица 13):
Таблица 13 - Выходную последовательность лексем
| Входная последовательность текста исходной программы | Выходная последовательность лексем во внутреннем представлении |
| //программа сравнения чисел | |
| import java.util.Scanner; | K8 K9 R6 K10 R6 T7 R3 |
| public class main { | K1 K2 K3 R7 |
| int a = 10; | T3 I S0 W1 R3 |
| Scanner in = new Scanner(System.in); | T7 I S0 K4 T7 K5 R6 I R3 |
| double b = in.nextDouble(); | T5 I S0 I R6 K6 R4 R5 R3 |
| String text = "Больше"; | K7 I S0 R9 I R10 R3 |
| String text1 = "Меньше"; | K7 I S0 R9 I R10 R3 |
| if ( a > b ) { | S12 R4 I S1 I R5 R7 |
| System.out.println(text); | K5 R6 K8 R6 S6 R4 I R5 R3 |
| } | R8 |
| if( a < b) { | S12 R4 I S2 I R5 R7 |
| System.out.println(text1); | K5 R6 K8 R6 S6 R4 I R5 R3 |
| } | R8 |
| if (a == b){ | S12 R4 I S5 I R5 R7 |
| System.out.println("="); | K5 R6 S7 R6 S6 R4 R9 I R10 R5 R3 |
| } } } | R8 R8 R8 |
Разработаем блок-схемы для лексического анализатора (блок-схема 1, 2, 3). После составления всех таблиц с лексемами вы видим, что в нашем лексическом анализаторе буду отдельно проверяться типы данных, операции, Константы, операторы. На основе этих данных мы должны разобрать, как же будут у нас заполняться таблицы. Блок-схемы выглядят следующим образом
Блок-схема 1 - Схема работы лексического анализатора.
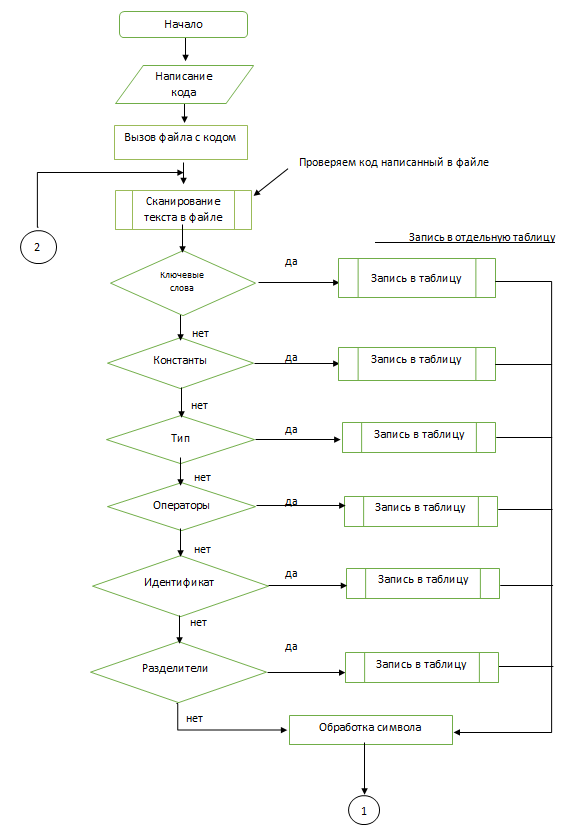
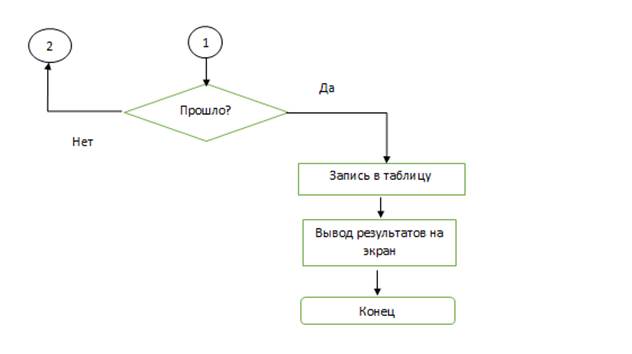
Блок-схема 2 - Сканирование документа (операции).
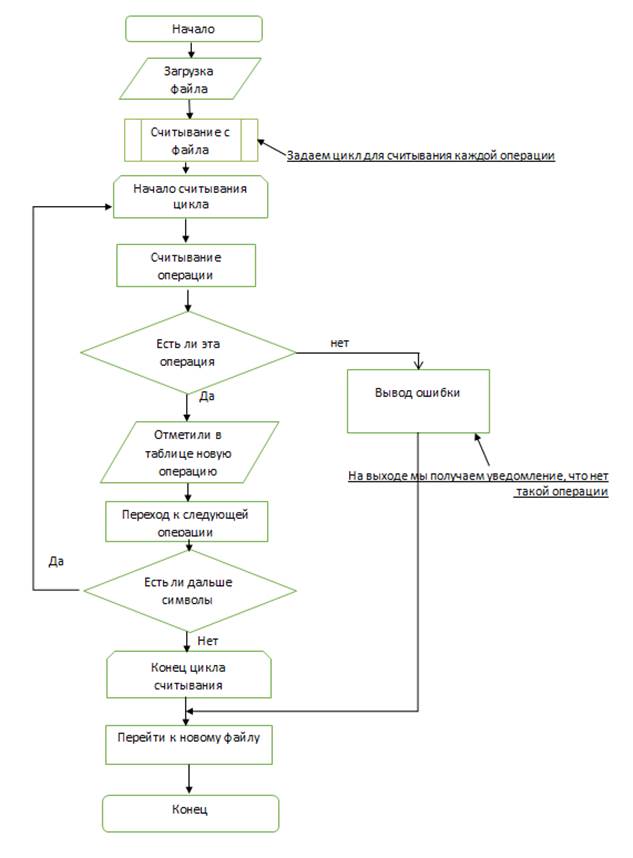
Блок-схема 3 - Сканирование документа (операторы).
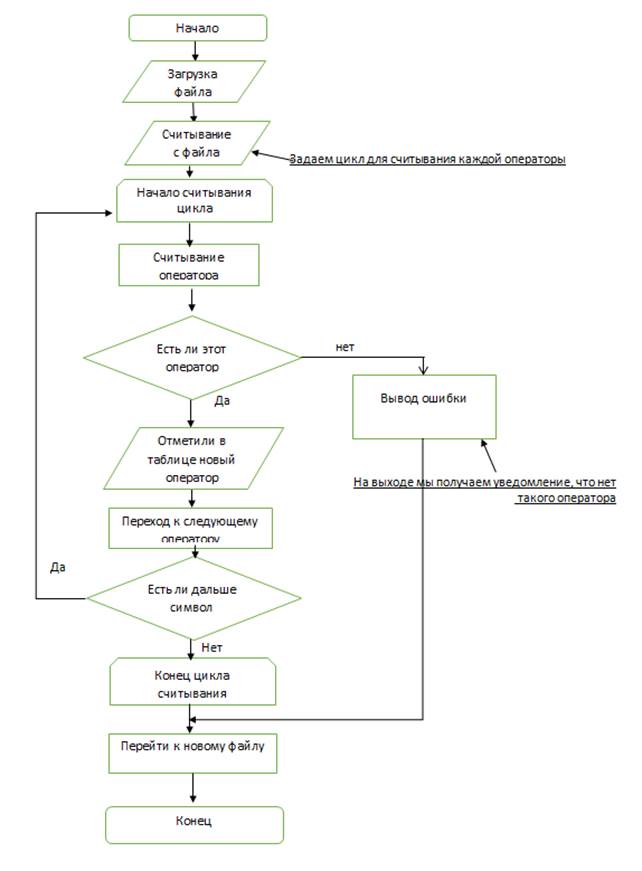
После того как мы составили блок-схемы и выяснили как у нас будет работать лексический анализатор перейдем в главу 3, где будет рассматриваться программное средство с помощью, которого будет написан лексический анализатор.
Дата добавления: 2020-04-25; просмотров: 413; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!