Малюнок 2.7. Програма як діалектичне заперечення проблеми 4 страница
Принцип тлумачення речень мови як послідовностей: на наступному рівні абстракції речення розглядаються як послідовності літер певного алафавіту.
Відзначимо, що тут абстрагуємось від порядку побудови ланцюжків. Наприклад, можна було б розрізняти ланцюжки (ab)c та a(bc). Але ми абстрагуємося від генетичного аспекту (аспекту породження). Це подібно до того, як ми сприймаємо, наприклад, паркан. Для нас це послідовність секцій, і не важливо, в якому порядку вони зводилися. Цей рівень розгляду будемо позначати як L.S.S (Language is a Set of Sequences).
Наведені міркування та постулати дозволяють ввести наступну математичну модель формальної мови.
Друга, абстрактна модель формальної мови – це деяка підмножинаL Í A*, де A* – скінченні послідовності літер з алфавіту A. Це фактично є певним абстрактним поняттям формальної мови.
Зв’язок моделей задається операцією абстрагування absL, яка є операцією переведення множини в множину з інкапсуляцією структури послідовності речень.
Що можна досліджувати на такому рівні абстракції? В першу чергу, це теоретико-множинні операції та операції над послідовностями. Крім того, не слід забувати про операції, які зв’язують послідовності з множинами. Ці операції будуть описані пізніше у математичній частині розділу. Разом з тим, такі операції занадто бідні і не розкривають особливостей синтаксичного аспекту. Викликано це тим, що ми абстрагувались від способу, яким задається мова. І якщо для перших двох моделей таке абстрагування від генетичного та дескриптивного аспектів було корисним, бо дозволяє вивчати операції над мовами, то тепер потрібно ввести механізми породження мов (дескрипції мов).
|
|
|
З’являється третя модель формальної мови. Ця модель успадковує властивості першої моделі з додаванням нової характеристики – механізму породження мови. Такий механізм можна називати породжуючою дескриптивною системою мови. Дуальний до породження механізм – сприйняття мов. Такий розподіл є традиційним для лінгвістики, де виділяють того, хто говорить (породження), і того, хто слухає (сприйняття). Такі ж механізми є і для програм: програмісти породжують програми, виконавці (зокрема, комп’ютери) – їх сприймають.
Отже, з’являється новий елемент поняття формальної мови – мовна дескриптивна система. Знову-таки, для визначення цієї системи будемо рухатись від абстрактного до конкретного.
Вважаючи, що породження є більш вагомим (ведучим) аспектом порівняно з сприйняттям, спочатку зосередимось на породженні.
Інтуїтивне розуміння породження полягає в тому, що це є процес, який веде від певних початкових елементів до заключних елементів (остаточно породжених елементів). Основні питання для уточнення цієї моделі полягають в наступному:
|
|
|
1. Елементи якої множини використовуються в процесі породження?
2. Які елементи є початковими?
3. Які елементи є заключними?
4. Як саме задаються операції породження одних елементів з інших?
Будемо вважати, що в процесі породження відбувається створення (перетворення) елементів множини St, початкові елементи задаються підмножиною I, а заключні – підмножиною F з St. Залишається питання про способи породження нових елементів. Найпростішим (найабстрактнішим) є випадок, коли породження задається бінарним відношенням перетворень (переходів, транзицій) tr Í St ´ St. Таким чином, отримали першу над-абстрактну модель породжуючої системи, яка задається параметрами T S = (St, I, F, tr). Така система породжує множину елементів L(TS) наступним чином: береться елемент a з I, далі береться елемент b, такий що (a, b) належить tr, потім цей процес повторюється, аж поки не буде отриманий елемент c з F. Цей елемент і входить до L(T S). Тут фактично описаний процес побудови рефлексивного транзитивного замикання tr* відношення tr і вибору тих пар, перший елемент яких належить I, а другий – F. Це дозволяє записати формулу L(T S) = { c | (a,c)Î tr*, aÎI, cÎF}.
|
|
|
Наведену модель в літературі часто називають транзиційною системою. Зафіксуємо цей розгляд за допомогою наступного принципу.
Принцип розгляду механізму породження мови як транзиційної системи: над-абстрактну модель породжуючої системи тлумачимо як транзиційну систему T S = (St, I, F, tr) з визначеними раніше параметрами (St, I, F, tr) та яка визначає множину породжуваних елементів мови наступною формулою L(T S) = { c | (a,c)Î tr*, aÎI, cÎF}.
Зауважимо, що транзиційні системи можна використовувати і як моделі сприйняття. В цьому випадку можна застосувати формулу L(T S) = { a | (a,c)Î tr*, aÎI, cÎF}.
Як бачимо, різниця в породженні та сприйнятті полягає в тому, що в першому випадку елементи мови є результатоми (вихідними даними) процесу породження, а в другому – аргументами (вхідними даними) процесу сприйняття. Крім того, можна говорити про те, що процес породження веде від позначення класу речень до окремого (індивідуального) речення, а процес сприйняття – навпаки, веде від індивідуального речення до позначення класу речень.
Транзиційні системи є моделями абстрактних динамічних систем, але суто мовні характеристики в них відсутні. Дійсно, як видно з наведеного визначення, ця над-абстрактна модель (транзиційна система) має той же рівень тлумачення елементів мови як і над-абстрактна модель формальної мови. Треба тепер конкретизувати цю модель, щоб перейти до тлумачення мови як множини ланцюжків, тобто перейти на рівень абстрактної моделі мови. Будемо вважати, що система має породити мову L Í A*.
|
|
|
Розумно припустити, щоб множина St також конкретизувалась як множина послідовностей над певним алфавітом B. Таке тлумачення пов’язане з тим, що на цьому рівні абстракції ми і не маємо інших структур речень. Зрозуміло, що AÍB. Але залишається питання, чи можна вважати, що A=B. Недовгі роздуми на цю тему приводять до висновку, що брати випадок A=B недоцільно, хоч в літературі такі системи досліджуються під назвою системам Туе. Справа в тому, що породження вимагає певної допоміжної інформації, тому краще взяти B, що складається з двох частин: алфавіту A, та деякого допоміжного алфавіту N. Елементи алфавіту N дійсно використовуються як допоміжні, тому вони не входять до ланцюжків породжуваної мови. За це їх називають нетермінальними символами (літерами), а елементи A входять в заключні ланцюжки, тому їх називають термінальними символами. Таким чином, проведена наступна конкретизація: St=(AÈN)*, I Í (AÈN)*, FÍ A*. Ця конкретизація не є повною, тому що відношення tr залишається абстрактним, воне не враховує нову структуру St.
Щоб наступна конкретизація не була зайвою конкретизацією, треба «розумно» скористатись тем, що St є множиною ланцюжків. Тому нова конкретизація tr заснована на тому, що перетворення задаються не «глобально» на вьому ланцюжку, а «локально», лише на деякій частині ланцюжка. Іншими словами, від трансформації об’єкта як цілісності, переходимо до трансформації окремих частин. Приклади наступні: змії змінують свою «одежу» – шкіру – повністю, люди – частинами (можна замінити окремо пальто, або сорочку і т.д.). Аналогічно, при ремонті складної техніки, можно замінити агрегат повністю, наприклад, замість пошкодженого двигуна поставити новий, або замінити лише пошкоджену частину двигуна на справну.
При такому тлумаченні відношення переходів задається множиною локальних правил P, а операція «глобалізації», яка одночасно є операцією абстракції absG, дозволяє перетворити P в tr. Вкажемо наступну формулу: absG(P)={ lar®lbr |(a,b)ÎP, l,rÎ(AÈN)*}. Деталі визначення absG буде наведено пізніше. У якості початкових ланцюжків береться лише один певний символ S з N. Такий початковий символ називають аксіомою (геном, «словоматкою»). Термінальний алфавіт у подальшому будемо позначати T.
Таким чином, отримали другу абстрактну модель породжуючої системи, яка задається параметрами G=(N, T, P, S) і яка успадковує над-абстрактну модель T = (St, I, F, tr) наступним чином: St=(TÈN)*, I = {S}, F=T*, tr=absG(P). Отриману модель називають породжуючою граматикою. Це відповідає традиційному вживанню терміну «граматика», який означає сукупність правил побудови правильних речень мови. Зафіксуємо цей розгляд у вигляді відповідного принципу.
Принцип подання породжуючих систем породжуючими граматиками: Абстрактну модель породжуючієї системи тлумачимо як породжуючу граматику G=(N, T, P, S) з наведеними вище параметрами, що є конкретизацією транзиційної системи TS = (St, I, F, tr) та визначає формальну мову L(G) вказаним вище чином.
Чотири побудованих моделі можуть бути охарактеризовані наступною таблицею.
Таблиця 4.1
| Екстенсійні множинні моделі | Дескриптивно-множинні моделі | |
Модель 1. Мова – певна множина елементів

| 
| Модель 3. Мова – певна множина елементів, яка задається транзиційною системою
|
| Модель 2. Мова – певна множина елементів, які є скінченними послідовностями |
| Модель 4. Мова – певна множина елементів, які є скінченними послідовностями, і яка задається породжуючою граматикою |
Наведена інформація про моделі може бути подана і у вигляді малюнку.
Малюнок подає взаємозв’язок моделей формальних мов. Цей малюнок демонструє, що визначення формальної мови має щонайменше два виміри: перший рівень (вертикальний) задає рівень абстракції складових, другий рівень вводить нову дескриптивну складову.

Малюнок 4.2. Моделі мов та граматик різного рівня абстракції
Розрізнення рівнів абстракції визначень формальної мови та породжуючих граматик дозволяє досліджувати їх властивості на більш адекватному (більш абстрактному) рівні, де такі дослідження будуть простішими. Далі певні властивості переносяться (успадковуються) на більш конкретні рівні. Наприклад, теоретико-множинні властивості верхнього рівня (порожність мови, скінченність та таке інше) переносяться на більш конкретні рівні.
Зауваження 4.1. Як вже відмічалось, в літературі часто вживаються різні терміни для позначення одних і тих же понять. Наприклад, елемент формальної мови називають «реченням», «словом», «ланцюжком». Такий різнобій у термінології викликаний щонайменше двома обставинами:
a) дослідження формальних мов ведуться представниками різних наукових шкіл, зокрема лінгвістики та інформатики. Термінологія таких шкіл відрізняється одна від одної;
b) самі формальні мови досліджуються на різних рівнях абстракції, і той термін, що є доречним на одному рівні абстракції, часто не є відповідним (адекватним) іншому рівню абстракції. Наприклад, термін «слово» досить адекватно відповідає рівню формальних мов, коли їх елементи задаються як послідовності символів, разом з тим цей термін не зовсім адекватний поданню елементів мови за допомогою граматик, бо текст великої програми, що складається з багатьох синтаксичних категорій, неадекватно тлумачити як одне слово.
Ми і в тексті цього посібника не будемо занадто строгими і дозволимо собі вживати різні терміни для одних і тих же понять.
Зробимо також декілька методологічних зауважень.
- Про опосередкування. Вивчення мови відбувається не безпосередньо (як множини ланцюжків), а опосередковується механізмом дескриптивних систем. Тобто вивчаються не стільки мови, скільки граматики. В книжках цей факт явно не акцентується. Це подібно до того, як вивчення натуральних чисел опосередковується вивченням операцій та відношень, заданих на натуральних числах. Так само і вивчення програм фактично опосередковується вивченням їх композицій. В цілому слід зазначити, що опосередкування – це важливий механізм діалектики.
- Про визначення породжуючої граматики. В існуючій літературі формальна граматика визначається як четвірка G=(N, T, P, S) з визначеними раніше параметрами. На наш погляд таке визначення не є вдалим, оскільки тут задаються лише індивідуальні параметри і совсім не розкриваються механізми породження мов. Це подібно до твердження, що автомобіль під моїми вікнами з вказаними конкретними характеристиками – це автомобільна промисловість. Акценти розставленні не вірно. (Те саме часто можна зустріти в деяких книжках з теорії алгоритмів, дискретної математики, логіки). Визначення граматики повинно починатись з властивостей класу породжуючих граматик, і лише потім потрібно задавати конкретні (індивідуальні) параметри.
- Про відношення вивідності. Воно задається через єдність загального та одиничного. Це подібно, наприклад, до інструкції з користування телевізором. Механізм опису апелює не до конкретного телевізора в вашій кімнаті, а до будь-якого телевізора відповідної моделі. Тобто інструкція спирається на загальні параметри, які потім інтерпретуються для кожного конкретного телевізора. Це досить тонке питання, і його слід розуміти.
Таким чином, розглянуто моделі формальних мов різного рівня абстракції. Ці моделі можна назвати інтенсіональними моделями, бо вони характеризують властивості формальних мов. Для задання конкретних мов використовують екстенсіональні моделі. В наступних розділах будемо спиратися на екстенсіональні визначення мов. Зазначимо, що традиційно обмежуються лише екстенсіональними визначеннями, не розкриваючи інтенсіональних.
Сформулюємо основні висновки нашого аналізу.
1. Поняття формальної породжуючієї граматики має два аспекти: інтенсіональний та екстенсіональний.
2. Екстенсіональний аспект більш простіший і задається як клас об’єктів, кожен з яких є четвіркою виду G=(N, T, P, S), де N і T – скінчені алфавіти, NÇT=Ø, 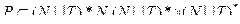 ,
,  скінчена і
скінчена і  .
.
3. Інтенсіонал поняття породжуючієї граматики полягає в наступному: кожна граматика призначена для породження формальної мови, породження відбувається за допомогою відношення безпосереднього виводу, а мова – це множина термінальних ланцюжків, що виводяться з аксіоми за скінченну кількість кроків.
4. Поняття формальної граматики є єдністю обох аспектів, тут важливо підкреслити, що інтенсіональний аспект є тим загальним, що може використовуватись у конкретних (індивідуальних, одиничних) граматиках, бо задається фактично схема визначень, яка інтерпретується на конкретних значеннях параметрів.
Зроблений методологічний та інтенсіональний аналіз поняття формальної мови дозволяє тепер перейти до введення екстенсіональних визначень формальних мов та граматик.
4.2 Визначення основних понять формальних мов
Визначення 4.1 Алфавітом називають скінчену непорожню множину символів (літер). Позначатимемо алфавіт знаком Σ.
Приклад 4.1 Найчастіше використовуються наступні алфавіти:
1. Σ = {0,1} – бінарний чи двійковий алфавіт;
2. Σ = {a , b … z} – множина літер англійського алфавіту.
Визначення 4.2 Ланцюжком, чи інколи словом, реченням, рядком, в алфавіті Σ називають скінченну послідовність символів з Σ.
Приклад 4.2 Послідовність 01101 – це ланцюжок в бінарному алфавіті Σ = {0,1}. Ланцюжок 111 також є ланцюжком в цьому алфавіті.
Визначення 4.3 Порожній ланцюжок – це ланцюжок, який не містить жодного символу. Цей ланцюжок позначається ε. Його можна розглядати як ланцюжок у довільному алфавіті.
Визначення 4.4 Довжина слова (послідовності) w позначається |w|; якщо Σ¢ Í Σ, то довжина послідовності, утвореної з w видаленням тих символів, що не належать Σ¢, позначається |w|Σ¢; якщо a Î Σ, то |w| a означає |w|{a} і задає кількість входжень символу a в w.
Приклад 4.3 Для ланцюжка abcbacaacccb маємо:
|abcbacaacccb| = 12, |abcbacaacccb|{a, c}= 9, |abcbacaacccb|c=5.
Визначення 4.5 Якщо w та u – ланцюжки в алфавіті Σ, то ланцюжок wu (результат дописування слова u в кінець слова w) називається конкатенацією (катенацією, зчепленням) слів w та u. Іноді конкатенацію слів позначають w×u.
Визначення 4.6 Якщо w – ланцюжок в алфавіті Σ, то ланцюжок  називається n-ю степенню w і позначається w n.
називається n-ю степенню w і позначається w n.
За визначенням, w 0=e.
Приклад 4.4 a3=aaa, a2b3c=aabbbc,
(abcbacaacccb)2= abcbacaacccbabcbacaacccb.
Визначення 4.7 Множина всіх ланцюжків в алфавіті Σ позначається Σ* і називається вільною напівгрупою, породженою Σ. Множина всіх непорожніх ланцюжків позначається Σ+.
Приклад 4.5 Якщо Σ ={a}, то Σ*={e, a, aa, aaa, …}, Σ+={a, aa, aaa, …}.
Термін «вільна напівгрупа» веде своє походження з алгебри. Напівгрупою називається множина з асоціативною бінарною операцією. Якщо така множина має одиничний елемент, то її називають моноїдом. Напівгрупа вільна, якщо ніяких інших співвідношень (крім асоціативності) немає. В теорії формальних мов часто вважають, що напівгрупа має одиничний елемент. Множину Σ* можна розглядати як вільну напівгрупу з одиницею. Конкатенація є асоціативною операцією, а порожній ланцюжок e є одиницію, тому що для довільного ланцюжка w маємо w × e= e×w= w. Такий розгляд множини ланцюжків Σ* дозволяє перейти до більш багатої структури напівгрупи та використати алгебраїчні властивості для дослідження цієї множини. Іншою обставиною є те, що подаючи множину послідовностей у вигляді напігрупи, ми ототожнюємо символ з послідовністю довжини 1, що складається з цього символу. Тому замість двохосновної моделі (алфавіт та множина послідовностей), яка розрізняє символи та послідовності, розглядається лише одна основа – множина ланцюжків. Це спрощує дослідження.
Дата добавления: 2019-02-13; просмотров: 219; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!