Cинтаксический анализ для LL(1)-грамматики
Алгоритм синтаксического анализа на основе LL(K)-грамматики относится к классу алгоритмов нисходящего разбора.
Строкам управляющей таблицы М для грамматики G(V,T,P,S) /1/ ставятся в соответствие элементы множества VUTU$ ($-маркер дна стека), столбцам-элементы множества T U "lambda"("lambda" - пустая строка). Перед началом работы алгоритма в рабочий стек заносятся символы $ и S. Возможные значения элементов таблицы и их интерпретация алгоритмом разбора приведены в таблице 3.2.
Таблица 3.2
| N п/п | Значение элемента таблицы | Интерпретация алгоритмом разбора | |
| 1 | Номер i порождающего правила грамматики | Удаление символа из рабочего стека; запись этого символа в выходной стек; запись правой части правила номер i в рабочий стек справа налево, начиная с последнего символа | |
| 2 | "сдвиг" | Удаление символа из рабочего стека; запись его в выходной стек; считывание следующего символа входной цепочки | |
| 3 | допуск | конец работы | |
| 4 | "ошибка" | Вывод сообщения об ошибке; конец работы | |
Для построения управляющей таблицы М по заданной LL(1)-грамматике G(V,T,P,S) можно воспользоваться следующим алгоритмом /1/.
1.Если <A>::=r-правило номер i заданной грамматики, то M(<A>,a)=i для всех a (кроме "lambda"), являющихся терминальными префиксами цепочек, выводимых из r. Если таким префиксом может быть "lambda", то М(<A>,b)=i для всех b, являющихся терминальными символами, которые могут встречаться непосредственно справа от <A>.
|
|
|
2.M(a,a)="сдвиг" для всех a, принадлежащих Т.
3.M($,"lambda")="допуск".
4.Оставшиеся незаполненными элементы таблицы М получают значение "ошибка".
Пример.
Грамматика G(V,T,P,S) рассмотренного выше примера не обладает свойством LL(1),поскольку обе правые части для нетерминала <E> (правила 2 и 3) порождают цепочки, начинающиеся одним и тем же терминалом i. То же можно сказать и о правилах для терминала <T>.Преобразуем грамматику G(V,T,P,S) к грамматике G1(V1,T,P1,S), обладающей свойством LL(1).Правила последней примут вид :
1) <S>::=<E> 2) <E>::=<T><X> 3) <X>::=+<E> 4) <T>::=<F><Y>
5) <Y>::=*<T> 6) <F>::=i 7) <X>::="lambda" 8) <Y>::="lambda"
В соответствии с приведенным алгоритмом теперь можно построить управляющую таблицу для LL(1)-анализатора (таблица 3). Таблица 3
| i | + | * | $ | |
| <S> | 1 | |||
| <E> | 2 | |||
| <T> | 4 | |||
| <F> | 6 | |||
| <X> | 3 | 7 | ||
| <Y> | 8 | 5 | 8 | |
| i | сдвиг | |||
| + | сдвиг | |||
| * | сдвиг | |||
| $ | сдвиг |
Незаполненные элементы таблицы имеют значение "ошибка". Проанализируем входную цепочку i*i с помощью алгоритма LL(1)-анализатора. При этом, для облегчения формирования выходного стека, при записи символа в рабочий стек будем снабжать его указателем на символ, являющийся его предком в синтаксическом дереве разбора. Процесс анализа проиллюстрируем таблицей 4.
|
|
|
Таблица 3.4
| Рабочий стек | Вх. символ | М(A,a) |
| <S>,0 $ | i | M(<S>,i)=1 |
| <E>,1 $ | i | M(<E>,i)=2 |
| <T>,2 <X>,2 $ | i | M(<T>,i)=4 |
| <F>,3 <Y>,3 <X>,2 $ | i | M(<F>,i)=6 |
| i,4 <Y>,3 <X>,2 $ | i | M(i,i)="сдвиг" |
| <Y>,3 <X>,2 $ | * | M(<Y>,*)=5 |
| *,6 <T>,6 <X>,2 $ | * | M(*,*)="сдвиг" |
| <T>,6 <X>,2 $ | i | M(<T>,i)=4 |
| <F>,8 <Y>,8 <X>,2 $ | i | M(<F>,i)=6 |
| i,9 <Y>,8 <X>,2 $ | i | M(i,i)="сдвиг" |
| <Y>,8 <X>,2 $ | "lambda" | M(<Y>,"lambda")=8 |
| <X>,2 $ | "lambda" | M(<X>,"lambda")=7 |
| $ | "lambda" | M($,"lambda"= "допуск" |
В результате анализа получено синтаксическое дерево разбора (рис.3.4.).
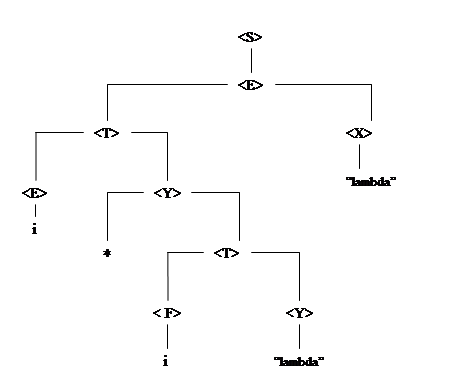
Рис.3.4. Синтаксическое дерево разбора
В выходном стеке это дерево представляется таблицей 3.5.
Таблица 3.5
| 12 | <X>,2 | |||
| 11 | <Y>,8 | |||
| 10 | i,9 | |||
| 9 | <F>,8 | |||
| 8 | <T>,6 | |||
| 7 | *,6 | |||
| 6 | <Y>,3
| |||
| 5 | i,4 | |||
| 4 | <F>,3 | |||
| 3 | <T>,2 | |||
| 2 | <E>,1 | |||
| 1 | <S>,0 | |||
Порядок выполнения работы
2.1.Проверить является ли заданная грамматика грамматикой LL(1), при необходимости выполнить соответствующие преобразования.
2.2.Построить управляющую таблицу разбора.
2.3.Разработать и отладить синтаксический анализатор, который должен быть оформлен в виде отдельной процедуры (подпрограммы).
Дата добавления: 2019-02-12; просмотров: 812; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!